1. Einleitung
Erstes Ziel dieses Beitrages ist die Klärung der Frage, ob – und wenn ja, inwiefern – digital verfügbare bündnerromanische (brom.) Medien für die linguistische Forschung nutzbar gemacht werden können. Exemplarisch soll dies anhand zweier Fallstudien zum Unterengadinischen (vallader) geschehen, deren Datenbasis aus Online-Ausgaben der brom. Tageszeitung La Quotidiana sowie aus Fernseh- und Radiosendungen der öffentlich-rechtlichen Radiotelevisiun Svizra Rumantscha (RTR) stammt. Konkret untersucht wird zum einen die Konkordanz prädikativer Adjektive (n = 254), zum anderen das phonetische Korrelat der palatalen Affrikaten /t͡ɕ/ und /t͡ʃ/ (n = 129). Die Tatsache, dass die herangezogenen brom. digitalen Medien lediglich einige vorsichtige qualitative, kaum aber quantitative Aussagen hinsichtlich der untersuchten Phänomene erlauben (fehlende Adjektivkonkordanz ist dokumentierbar; es gibt erste Hinweise für den Zusammenfall der beiden palatalen Affrikaten), motiviert schließlich das zweite Ziel des Beitrags: die Formulierung einiger Vorüberlegungen, die den Ausgangspunkt für die Schaffung des ersten dezidiert brom. Online-Korpus bilden können. Der Beitrag gliedert sich wie folgt: Kapitel gibt zunächst einen ersten Überblick sowohl über die sprachliche Situation als auch über die digitale Medienlandschaft Romanischbündens und die bereits zur Verfügung stehenden digitalen sprachwissenschaftlichen Ressourcen, die zur Erforschung des Bündnerromanischen eingesetzt werden können. In der Folge präsentieren Kapitel und Kapitel Methodologie und Ergebnisse der beiden Fallstudien. In Kapitel werden schließlich erste Überlegungen vorgestellt, deren Berücksichtigung uns im Rahmen der Planung und Erstellung eines brom. Online-Korpus notwendig erscheint. Kapitel fasst die wichtigsten Punkte des Beitrags zusammen.
2. Bündnerromanisch und seine digitalen Ressourcen
Das vorliegende Kapitel ist dreigeteilt. Eingangs stellt Abschnitt das in den empirischen Studien in Kapitel und untersuchte Idiom Unterengadinisch sowie die soziolinguistische Situation des Bündnerromanischen im größeren Kontext des Rätoromanischen vor. In der Folge geht Abschnitt auf die bereits bestehenden digitalen sprachwissenschaftlichen Ressourcen ein, die eine Untersuchung dieser romanischen Sprache ermöglichen. In Abschnitt schließlich werden die brom. Online-Medien vorgestellt, deren Eignung für linguistische Untersuchungen in der Folge erprobt werden soll.
2.1. Rätoromanisch – Bündnerromanisch – Unterengadinisch: ein Überblick
Das Rätoromanische – und damit auch das Bündnerromanische (brom.), zu dem wiederum das Unterengadinische (ue.) gehört –1 ist eine italoromanische Minderheitensprachfamilie, die in drei heute geographisch unverbundenen Sprachräumen von insgesamt rund 500.000 Sprechern und Sprecherinnen gesprochen wird. Neben dem Bündnerromanischen im südostschweizerischen Kanton Graubünden (ca. 60.000 Sprecher:innen; LR 2015, 30) gehört auch das im norditalienischen Grödner-, Gader-, Buchenstein- und Fassatal sowie in Cortina d'Ampezzo gesprochene Dolomitenladinische (ca. 30.000 Sprecher:innen; Ethnologue; vgl. hier) zum Rätoromanischen. Zahlenmäßig mit Abstand am stärksten ist jedoch die „dritte Säule“ des Rätoromanischen, nämlich das in der gleichnamigen nordostitalienischen Region beheimatete Friaulische (400.000–600.000 Sprecher:innen; ARLeF 2015). In Abbildung 1 wird die geographische Situierung der rätoromanischen Sprachen dargestellt:

Geographische Situierung der rätoromanischen Sprachen (Quelle: Wikimedia Commons).
{kind=link}
Das in Abbildung 1 grün hinterlegte Bündnerromanische untergliedert sich wiederum in fünf sog. Idiome: das Surselvische (brom. sursilvan) im Vorderrheintal, das Sutselvische (brom. sutsilvan) im Hinterrheintal, das Surmeirische (brom. surmiran) in Mittelbünden (Oberhalbstein und Albulatal), das Oberengadinische (brom. puter) und das – in diesem Beitrag näher betrachtete – Unterengadinische (ue.; brom. vallader). Alle Idiome, die taxonomisch über den Ortsmundarten stehen, verfügen seit den 1920er bis 1960er Jahren über eine jeweils eigene, bis heute gültige Schriftnorm (Grünert 2005). Diese Normen sind insofern historisch gewachsen, als sie das Ergebnis eines jahrzehntelangen Herausbildungsprozesses sind, dessen Ursprünge in der frühen zweiten Hälfte des 19. Jahrhunderts liegen (vgl. Darms 1989). Aus Abbildung 2 wird die räumliche Verteilung der fünf brom. Idiome innerhalb des Schweizer Kantons Graubünden ersichtlich:
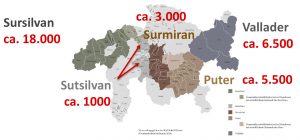
Geographische Situierung der fünf bündnerromanischen Idiome (Darstellung auf Basis von LR 2015, 50).
Die in Abbildung 2 angegebenen Zahlen spiegeln die Anzahl derjenigen im farblich hinterlegten Gebiet ansässigen Sprecherinnen und Sprecher wider, die im Zuge der eidgenössischen Volkszählung im Jahr 2000 angaben, Bündnerromanisch sei die von ihnen bestbeherrschte oder zumindest eine der von ihnen regelmäßig verwendeten Sprachen (vgl. LR 2015, 33). Die Summe der Zahlen in Abbildung 2 (= 34.000) stimmt nicht mit derjenigen von insgesamt 60.000 Bündnerromanischsprechenden (siehe oben) überein. Dies liegt darin begründet, dass letztere Zahl auch Sprecher:innen beinhaltet, die nicht im traditionellen Sprachgebiet, sondern anderswo in der Schweiz leben.2
Die Situation des Bündnerromanischen ist prekär. Und dies gilt – wenn auch in verschieden starkem Ausmaß – für alle fünf Idiome. Zumindest die prozentuale Sprecherzahl ist von 1990 bis 2015 wenngleich nicht dramatisch, so doch auch nicht unerheblich gesunken (LR 2015, 28–30). Bezüglich der absoluten Sprecherzahlen können keine eindeutigen Aussagen getroffen werden, da die über die Jahre erfolgten Erhebungen mit unterschiedlichen Frageformulierungen arbeiteten.3 Beispielhaft veranschaulicht den prozentualen Rückgang Abbildung 3 aus Furer Roveredo (2005, 42) anhand der Entwicklung der Verwendung des Bündnerromanischen als Familiensprache im traditionell romanischsprachigen Gebiet zwischen 1990 und 2000:
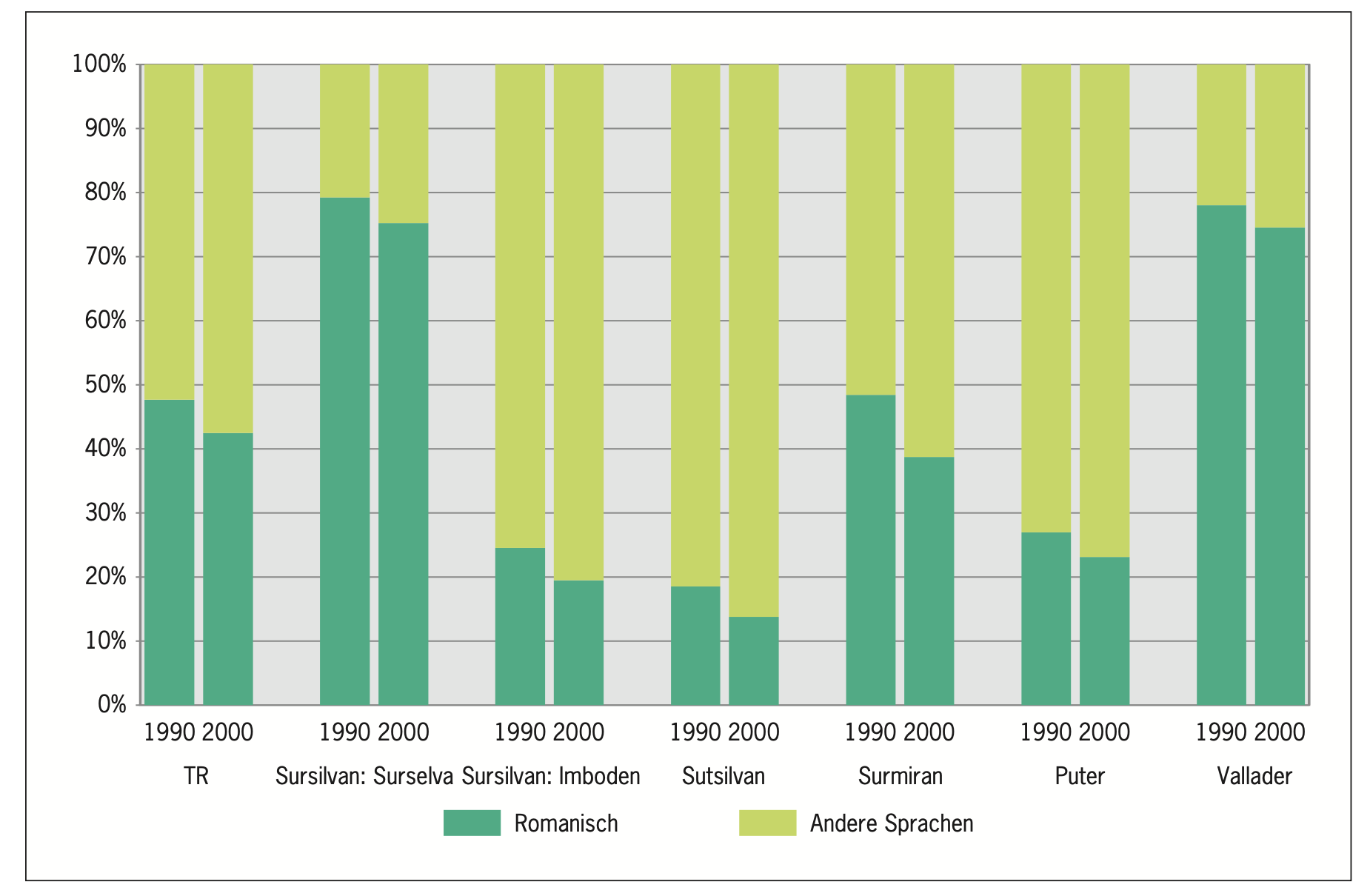
Bündnerromanisch als Familiensprache im traditionellen Sprachgebiet (TR); 1990 vs. 2000.
An den in jedem Fall prozentual rückläufigen Sprechendenzahlen des Bündnerromanischen ändert auch diejenige Tatsache wenig, dass neben den einzelnen Schriftnormen der fünf Idiome (siehe oben) mit dem 1982 durch den Zürcher Romanisten Heinrich Schmid auf Initiative der Lia Rumantscha4 entwickelten Rumantsch Grischun zusätzlich ein überidiomatischer Standard existiert (vgl. Schmid 1982).5 Zumindest als Schulsprache jedoch ist das Rumantsch Grischun heute – nach großer anfänglicher Euphorie – gescheitert (vgl. LR 2015, 53 ff.).6 Dennoch ist festzuhalten, dass die brom. Sprachgemeinschaft dem Rumantsch Grischun nicht per se ablehnend gegenübersteht, obschon es sie in verschiedene Lager spaltet (vgl. LR 2015, 60 f.). Sowohl Bund und Kanton als auch die Lia Rumantscha verwenden es üblicherweise für die schriftliche Kommunikation mit der bündnerromanischsprachigen Bevölkerung. Zumindest teilweise trifft dies auch auf die Medien zu. Diese werden, mit besonderem Fokus auf den digitalen Formaten, in Abschnitt vorgestellt. Zunächst jedoch wird ein kurzer Überblick über bereits vorhandene digitale sprachwissenschaftliche Ressourcen des Bündnerromanischen gegeben.
2.2. Digitale sprachwissenschaftliche Ressourcen des Bünderromanischen
Anders als bei den größeren Sprachen der Romania, sind der wissenschaftlichen Untersuchung des Rätoromanischen klare Grenzen gesetzt, was in erster Linie mit dem Fehlen von elektronischen sprachwissenschaftlichen Ressourcen zu tun hat. So steht man als ForscherIn zunächst vor der Frage, mit welchen sprachlichen Daten gearbeitet arbeiten kann bzw. wie diese beschafft werden können, und weiterhin, welche linguistischen (Hilfs-)Werkzeuge (Grammatiken, Wörterbücher, Konjugationstabellen, etc.) (online) zur Verfügung stehen. Das Rätoromanische hat zwar umfangreiche Online-Wörterbücher für alle Idiome und Rumantsch Grischun, die teils sogar Verbtabellen enthalten (so z. B. das Dicziunari vallader für das Unterengadinische auf der Seite der Uniun dals Grischs), und auch die bisher erschienenen Teile des idiomübergreifenden Dicziunari Rumantsch Grischun (DRG) sind seit 2018 online konsultierbar; darüber hinaus fehlen aber andere Hilfsmittel wie Korpora, umfangreiche deskriptive Grammatiken, alignierte Textdatenbanken7 und Analysewerkzeuge wie z. B. Texterkennungssoftware für die automatisierte Digitalisierung gedruckter Texte (OCR) oder morphologische Segmentierer, die für andere Minderheitensprachen in der Romania bereits zur Verfügung stehen oder erarbeitet werden (so z. B. für das Okzitanische ein mehrsprachiges paralleles Korpus im Rahmen des Projektes ParCoLaF, oder der morphosyntaktische Tagger TALISMANE (Vergez-Couret/Urieli 2015; Bernhard et al. 2018) im Rahmen des Projektes RESTAURE). Folglich kann das Bündnerromanische im Sinne von Bernhard et al. (2018, 3917) durchaus treffend als "low-resourced language" charakterisiert werden.
Die einzigen uns bekannten, allesamt sehr kleinen Online-Korpora zum Bündnerromanischen, die bereits existieren, sind das Swiss SMS Corpus (1120 SMS auf Bündnerromanisch; Stark/Ueberwasser/Beni 2009-2015) und das WhatsApp Switzerland-Korpust (frei zugänglich; Ueberwasser/Stark 2017) sowie weiterhin ein noch sehr kleines Korpus mit surselvischen Audio-Aufnahmen im Mozilla Common Voice-Projekt (Unterengadinisch soll folgen). Ein immerhin ca. 3,8 Millionen Wörter umfassendes Korpus (nur Rumantsch Grischun), das Worthäufigkeiten angibt, ist im Rahmen des An Crúbadán-Projektes (Scannell 2007), das das Ziel hat, online frei verfügbare Texte zur Erstellung von Korpora für Minderheitensprachen zu nutzen, entstanden.
In Ermangelung bestehender (Online-)Korpora soll im vorliegenden Beitrag mittels zweier Pilotstudien überprüft werden, ob – und wenn ja, inwiefern – stattdessen digital verfügbare brom. Medien für die linguistische Forschung nutzbar gemacht werden können. Es folgt deshalb im nächsten Abschnitt zunächst ein Überblick über die im Internet zugänglichen brom. Medien.
2.3. Bündnerromanische Online-Medien
Die aktuelle brom. Medienlandschaft ist, was in Anbetracht der geringen Sprechendenzahlen wenig überrascht, durchaus überschaubar.8 Nichtsdestotrotz ist sie – auch auf Grund massiver kantonaler und bundesschweizerischer Förderung – erstaunlich facettenreich, sowohl hinsichtlich der Print- als auch der audiovisuellen Produkte. Bezüglich letzterer ist zuvorderst die Radiotelevisiun Svizra Rumantscha (RTR) zu nennen, eine in Chur ansässige Tochter der Schweizerischen Radio- und Fernsehgesellschaft, die derzeit über ein Jahresvolumen von ca. 25 Millionen Schweizer Franken verfügt und deren Produktion von über 130 Vollzeitangestellten gesichert wird. Bereits seit 1925 sendet RTR vor allem brom. Radiosendungen. Bündnerromanische Fernsehsendungen hingegen produziert sie, ausgestrahlt über das deutschsprachige SRF, seit 1963: den Telesguard (ein Nachrichtenformat von 10-12 Minuten, das von Montag bis Freitag vor der Schweizerischen Tagesschau gesendet wird; im Sommer ersetzt durch das kürzere Sil Punct), die Cuntrasts (eine 25-minütige Kulturtalksendung, die jeweils sonntags erscheint) sowie den Minisguard (ein 10-12 minütiges, allsamstägliches Format für Kinder). Alle Produktionen der RTR sind in einer Mediathek zumindest für einen begrenzten Zeitraum online verfügbar. Bezüglich des Sprachgebrauchs bei RTR ist anzumerken, dass Sprecher:innen sowie Moderierende mündlich in aller Regel ihr eigenes Idiom verwenden, schriftlich (beispielsweise im Online-Portal RTR.ch oder für Untertitel und Einblendungen im Fernsehen) jedoch ausschließlich Rumantsch Grischun verwendet wird. Eine Ausnahme hierzu bilden die Radio-Nachrichten, die üblicherweise ebenfalls auf Rumantsch Grischun verlesen werden. Zusätzlich bietet auch das private Radio Südostschweiz mit Las Minutas Rumantschas eine kurze tägliche brom. Nachrichtensendung. Anders als die Formate der RTR ist diese jedoch online lediglich über den Livestream des Radio-Senders zugänglich.
Die in der ersten Hälfte des 20. Jahrhunderts relativ große Zahl an brom. Zeitungen bzw. Zeitungen mit brom. Anteil (siehe Fn. 8) hat sich in der Gegenwart deutlich verringert. Zunächst ist die seit 1997 bestehende und von Montag bis Freitag erscheinende La Quotidiana mit Sitz in Chur zu nennen, die aus der Fusion der Gasetta Romontscha, des Fögl Ladin, der Casa Paterna/La Pùnt und der bündnerromanischen Seite des Bündner Tagblatts hervorgegangen ist. Das zur Somedia-Gruppe gehörende Blatt mit einer Auflage von täglich rund 4000 Exemplaren veröffentlicht Artikel sowohl auf Rumantsch Grischun als auch in allen fünf Idiomen. Bezüglich letzterer ist das Surselvische deutlich überproportional vertreten, was dann schließlich auch zeitigt, dass La Quotidiana hauptsächlich in der Surselva gelesen wird. Die grischunsprachigen Artikel stammen seit 2018, auch auf Grund wiederkehrender Finanzierungsprobleme, vor allem von der bereits erwähnten RTR. La Quotidiana ist gänzlich digital verfügbar, ein Angebot, das jedoch kostenpflichtig ist. Die einzige der traditionellen bündnerromanischsprachigen Tageszeitungen, die nach der Gründung von La Quotidiana eigenständig geblieben ist, ist die in Savognin ansässige La Pagina da Surmeir (Auflage 1700), die keine Online-Ausgabe besitzt. Zuletzt sei noch die dreimal wöchentlich erscheinende Engadiner Post/Posta Ladina mit Sitz in St. Moritz erwähnt. Das mehrheitlich deutschsprachige Blatt (Auflage in der Regel ca. 7500) publiziert auf zwei bis drei Seiten Artikel auf Ober- und Unterengadinisch, die mit Ausnahme der Artikel der letzten sieben Tage auch online in einem Archiv als PDF-Dateien gratis zur Verfügung stehen. Sowohl La Quotidiana als auch La Pagina da Surmeir und Engadiner Post/Posta Ladina werden von der 1996 gegründeten Agentura da Novitads Rumantscha, einer kantonal und bundesschweizerisch finanzierten Nachrichtenagentur mit Sitz in Chur, unterstützt. Ende 2019 wurde diese zur neuen Fundaziun Medias Rumantschas umstrukturiert (Link 1; Link 2).
Die einzige uns bekannte online verfügbare bündnerromanischsprachige Zeitschrift im klassischen Sinne ist das ehemalige Jugendmagazin Punts, in welchem die Giuventetgna Rumantscha (GiuRu) von 1994 bis 2011 in insgesamt 199 Ausgaben Artikel zu einer Vielzahl jugendrelevanter Themen in den einzelnen Idiomen und auf Rumantsch Grischun publizierte. Alle Ausgaben sind bis heute als PDF-Dateien kostenlos downloadbar. Daneben ist die Satirezeitung Il Chardun (1971–2015) aus dem Unterengadin zu nennen, die zunächst als monatliche Zeitschrift, dann als Seite in La Quotidiana und schließlich nur noch online erschien. Auch sie ist auf ihrer noch immer bestehenden Internetpräsenz – zumindest in Teilen – weiterhin einsehbar. Eine Besonderheit ist, dass viele der Texte auch als von ihren VerfasserInnen gelesene Aufnahmen zur Verfügung stehen.
Neben der Tagespresse und den "traditionellen" audiovisuellen Medien sind als dritter Pfeiler der aktuellen digitalen brom. Medienlandschaft verschiedene Online-Blogs und ähnliche Formate zu nennen. So betreibt die bereits mehrfach erwähnte RTR ein Facebook-Portal (seit 2006 mit eigener Redaktion), das täglich Videoclips und Kurznachrichten auf Rumantsch Grischun (schriftlich und mündlich) als auch in den fünf Idiomen (nur mündlich) veröffentlicht. Die Plattform battaporta.ch, die kürzere Filme zu aktuellen Lifestylethemen für jüngere Zielgruppen anbietet, wird ebenfalls von RTR verantwortet. Die wie die Tageszeitung La Quotidiana zur Somedia-Gruppe gehörige Datenbank chattà.ch (dt. 'gefunden.ch') bietet seit 2007 enzyklopädische Artikel auf Rumantsch Grischun zu verschiedenen wissenschaftlichen Themen, von denen jeweils freitags einer in La Quotidiana abgedruckt wird. Die brom. Wikipedia ist meist auf Rumantsch Grischun (Artikelanzahl nicht ermittelbar), z. T. aber auch in den verschiedenen Idiomen verfasst (338 Artikel; ca. 85 % auf Surselvisch oder Oberengadinisch; Stand 29.3.2020). Als letztes digitales "Alternativformat" sei außerdem auf die auf Spendenbasis funktionierende Blog-Seite latabla.ch hingewiesen. Vor allem freie Journalisten und Journalistinnen, aber auch Jugendorganisationen u. a. veröffentlichen hier sowohl auf Rumantsch Grischun als auch in den verschiedenen Idiomen Artikel, die meist kulturelle Thematiken zum Inhalt haben.
In den folgenden beiden Kapiteln soll anhand von Daten, die den beiden umfangreichsten digital verfügbaren brom. Medienformaten entstammen (also der Online-Ausgabe der Tageszeitung La Quotidiana sowie der Mediathek der RTR), mittels zweier Fallstudien am Beispiel des Unterengadinischen überprüft werden, ob digital verfügbare brom. Medien für die linguistische Forschung nutzbar gemacht werden können. Beide Pilotstudien adressieren Sprachwandelphänomene, die in der Literatur bislang nur anekdotisch erwähnt wurden (Fallstudie 1) oder aber bereits in Laborstudien experimentell belegt werden konnten (Fallstudie 2). Im diesem Aufsatz steht nun die Replizierbarkeit der vorliegenden Ergebnisse bzw. die Belegbarkeit der Phänomene anhand von Medien-Daten im Vordergrund.
3. Fallstudie 1: Genus- und Numeruskonkordanz prädikativer Adjektive im Unterengadinischen
In der ersten Fallstudie, die überprüft, ob digitale bündnerromanische Medientexte für sprachwissenschaftliche Untersuchungen genutzt werden können, wird die morphologische Genus- und Numeruskonkordanz prädikativer Adjektive im Unterengadinischen untersucht. Anhand von 254 Belegen aus der Online-Ausgabe der Tageszeitung La Quotidiana (siehe Abschnitt ) wird gezeigt, dass eine fehlende Konkordanz anhand dieser Datenbasis qualitativ dokumentierbar ist. Weitere Aussagen sind jedoch ohne disproportionalen Aufwand nicht gesichert zu treffen. Abschnitt gibt zunächst einen Überblick über prädikative Adjektive im Unterengadinischen. Abschnitt stellt die Methodologie der Fallstudie vor. Abschnitt präsentiert und diskutiert deren Ergebnisse.
3.1. Prädikative Adjektive im Unterengadinischen
Wie in allen romanischen Sprachen kongruieren ue. prädikative Adjektive, anders als im Deutschen, obligatorisch in Genus und Numerus mit ihrem Bezugsnomen (vgl. Ganzoni 1983, 55). Ganzoni gibt allerdings lediglich Beispiele mit der Kopula esser sein.9 Beispiel (1) aus dem brom. Teil der Tageszeitung Engadiner Post/Posta Ladina (Ausgabe vom 14.3.2020; siehe auch Abschnitt ) mit render machen zeigt, dass Genus- und Numeruskonkordanz prädikativer Adjektive auch mit anderen Kopulae mindestens möglich ist. Das prädikative Adjektiv attents aufmerksam.{/scm.pl}, das sich auf einen pluralischen Referenten ans uns bezieht, kongruiert mit diesem in Genus und Numerus:
Avant duos ons ans han els rendü attents ch=i survegnan difficultats ...
vor zwei Jahren {/sc1pl.akk} haben sie gemacht aufmerksam.{/scpl} dass=sie bekommen Schwierigkeiten ...
Vor zwei Jahren haben sie uns darauf aufmerksam gemacht, dass sie Schwierigkeiten bekommen ...
Trotz der oben dargelegten Verhältnisse – normativ obligatorische Genus- und Numeruskonkordanz prädikativer Adjektive mit esser sein und möglicherweise auch mit anderen Kopulae – scheinen Sprecherinnen und Sprecher des Unterengadinischen morphologische Konkordanzmerkale nicht immer zu realisieren. Neben der anekdotischen Erwähnung des Phänomens in Weinreich (1953, 39) zeigt dies auch Beispiel (2), ein Hörbeleg aus dem Lied "Veglias Spranzas" (dt. alte Hoffnungen) der aus Zernez stammenden ue. Rock-Band Rebels. Hier ist das prädikative Adjektiv creschü erwachsen morphologisch maskulin Singular (≠ m.pl: creschüts), obwohl ein (kovertes) pluralisches Subjekt wir vorliegt; die Kopula ist gnir werden:
T=algordast eir tü? Co cha faivan plans ed eschan gnits creschü
dich=erinnerst auch du als dass wir.machten Pläne und sind geworden erwachsen.{/scm.sg}
Erinnerst Du Dich auch? Wie wir Pläne machten und erwachsen geworden sind.
Dass (2) – genauso wie einige weitere von uns gefundene Beispiele ohne morphologische Konkordanz – der Nähesprache entstammt, könnte ein Hinweis dafür sein, dass derartige Kommunikationsbedingungen eine fehlende morphologische Konkordanz begünstigen.
3.2. Daten und Annotation
Um zu prüfen, ob die morphologische Genus- und Numeruskonkordanz ue. prädikativer Adjektive (siehe Abschnitt ; (1) vs. (2)) anhand digitaler Medien untersuchbar ist, wurden im Zeitraum vom 18.1.2019 bis 18.2.2019 manuell alle prädikativen Adjektive aus dem unterengadinischsprachigen Teil der Online-Ausgabe von La Quotidiana (siehe Abschnitt ) extrahiert (n = 254). Die 254 extrahierten Belege wurden in einer Filemaker-Datenbank nach folgenden sechs Kriterien annotiert:
- Genus und Numerus (Adjektiv): [m.sg], [f.sg], [m.pl], [f.pl]
- Genus und Numerus (Bezugsnomen): [m.sg], [f.sg], [m.pl], [f.pl]
- Adjektivposition: [pränominal], [postnominal]
- Kopula esser: [+], [–]
- Zitierte direkte Rede: [+], [–]
- SprecherIn: offene Liste; entweder Journalist oder Journalistin oder, wenn Kriterium 5 = [+ zitierte direkte Rede], Name des/der Zitierten
Annotationskriterien 1 und 2 dienen, in Kombination, der Überprüfung, ob ein extrahiertes prädikatives Adjektiv morphologisch in Genus und Numerus mit seinem Bezugsnomen kongruiert oder nicht (= abhängige Variable "± Konkordanz"; Werte: [+] vs. [–]). Kriterium 2 dient zudem der Identifikation singularischer, maskuliner Bezugsnomen, da Belege mit solchen in der weiteren Quantifikation nicht beachtet werden können. Der Grund hierfür ist, dass die singularische, maskuline Form die morphologisch unmarkierte Form ue. Adjektive ist. Singularische, maskuline Bezugsnomen lassen also keine Rückschlüsse auf morphologische Genus- und Numeruskonkordanz ue. prädikativer Adjektive zu. Annotationskriterien 3–6 erfassen Prädiktorvariablen (= unabhängige Variablen). Annotationskriterium 3 ist deshalb relevant, weil denkbar ist, dass eine pränominale Adjektivposition – besonders, wenn noch weitere Elemente zwischen Adjektiv und Bezugsnomen stehen – im Vergleich zu postnominalen Adjektiven die Wahrscheinlichkeit einer morphologischen Konkordanz verringert, weil das Bezugsnomen zum Zeitpunkt der Adjektivrealisierung noch unrealisiert ist. Annotationskriterium 4 ist insofern wichtig, als die beiden uns bekannten ue. Grammatiken lediglich für die Kopula esser sein eine eindeutige Aussage hinsichtlich der normativ obligatorischen morphologischen Genus– und Numeruskonkordanz prädikativer Adjektive zulassen (siehe oben) und auch, weil zumindest einige der Fälle mit anderen Kopulae als esser sog. raising to object-Konstruktionen sind (z. B. Beispiel (1)), syntaktisch also anders zu analysieren sind als Kopulakonstruktionen mit esser sein. Annotationskriterium 5 dient der Feststellung, ob sich tendenziell nähesprachliche Äußerungen (= [+ zitierte direkte Rede]) hinsichtlich der morphologischen Genus-/Numeruskonkordanz prädikativer Adjektive anders verhalten als distanzsprachliche Äußerungen (= [– zitierte direkte Rede]) (vgl. nähesprachliches und konkordanzloses Beispiel (2)). Dies ist denkbar, da nicht-präskriptives Sprachverhalten häufig zunächst nähesprachlich auftritt und erst von hier aus (unter Umständen) in die Distanzsprache vordringt (vgl. z. B. zum Ausbleiben der Genus- und Numeruskonkordanz frz. Partizipien im analytischen Perfekt Koch/Oesterreicher 2011, 169; für eine diastratische Interpretation, vgl. aber auch Stark/Riedel 2013). Annotationskriterium 6 schließlich ist nötig, weil die extrahierten Okkurrenzen ue. prädikativer Adjektive zum Teil von den gleichen SprecherInnen stammen – sie also nicht voneinander unabhängig sind – und es aber gleichzeitig möglich ist, dass sich ue. Sprecherinnen und Sprecher bezüglich der morphologischen Genus– und Numeruskonkordanz prädikativer Adjektive voneinander unterscheiden.
3.3. Ergebnisse und Diskussion
In diesem Abschnitt werden die Ergebnisse der Fallstudie zur morphologischen Konkordanz prädikativer Adjektive im Unterengadinischen präsentiert und diskutiert. Zunächst werden die deskriptiv-statistischen Ergebnisse hinsichtlich der vier unabhängigen Variablen vorgestellt. Dies zeigt, dass in ue. digitalen Medien fehlende Genus- und Numeruskonkordanz prädikativer Adjektive für pränominale und postnominale Adjektive, für verschiedene Kopulae einschließlich esser sein, für zitierte direkte Rede und journalistische Originalproduktionen sowie für verschiedene Sprechende belegbar ist. In einem zweiten Schritt wird versucht, auf Basis der deskriptiven Ergebnisse inferentiell-statistisch zu bestimmen, welche Faktoren Einfluss auf die morphologische Konkordanz ue. prädikativer Adjektive haben. Der einzige hieraus hervorgehende statistisch signifikante Faktor ist die Prädiktorvariable "Kopula". Probleme dieser Analyse werden ebenfalls besprochen.
In Tabelle 1 werden die deskriptiv-statistischen Ergebnisse der in Abschnitt dargestellten Fallstudie zur morphologischen Genus- und Numeruskonkordanz ue. prädikativer Adjektive in Abhängigkeit von Genus und Numerus des Bezugsnomens präsentiert. Die jeweilige Prozentzahl in Klammern bezieht sich auf Okkurrenzen, bei denen die Genus– und Numeruskonkordanz am prädikativen Adjektiv morphologisch markiert ist:
| Bezugsnomen Genus | Total 1 | |||
| Mask. | Fem. | |||
| Bezugsnomen Numerus | Sg. | 105 (n/a) | 66/69 (96 %) | 174 |
| Pl. | 42/47 (89 %) | 33/33 (100 %) | 80 | |
| Total 2 | 152 | 102 | 254 | |
Morphologische Konkordanz prädikativer Adjektive nach Genus/Numerus des Bezugsnomens.
| [pränominal] | [postnominal] | ||
| Morphologische Konkordanz | [+] | 17 (94,4 %) | 124 (94,6 %) |
| [–] | 1 (6,6 %) | 7 (5,4 %) | |
Morphologische Konkordanz prädikativer Adjektive gemäß Position des Adjektivs.
Beispiel (3) illustriert die fehlende Genus- und Numeruskonkordanz für postnominale Adjektive (Bezugsnomen: ils disturbis [m.pl], prädikatives Adjektiv: pitschen [m.sg]). Beispiel (4) gibt die einzige Okkurrenz mit pränominalem Adjektiv (Bezugsnomen: la buna cumpagnia [f.sg], prädikatives Adjektiv: important [m.sg]):
[El accentuescha]: "[...] tegnond ils disturbis per mansteranza, commerzi e turischem plü pitschen pussibel"
er hebt.hervor [...] haltend die Störung.{/scm.pl} für Gewebe Handel und Tourismus so klein.{/scm.sg} möglich
Er hebt hervor: "[...] indem wir die Störungen für Gewerbe, Handel und Tourismus so klein wie möglich halten."
"Però güst uschè important es eir la buna cumpagnia", manzuna Koller.
aber genau so wichtig.{/scm.sg} ist auch die gute.{/scf.sg} Gesellschaft.{/scf.sg} erwähnt Koller
"Aber genauso wichtig ist auch die gute Gesellschaft", erwähnt Koller.
Konkordanzlose Okkurrenzen sind sowohl mit der Kopula esser sein als auch mit vier anderen Kopulae belegt (Annotationskriterium 4): gnir werden, render machen (2 Okkurrenzen), tgnair 'halten' (2 Okkurrenzen), tour 'nehmen'. Gleiches gilt sowohl für zitierte direkte Rede als auch für Passagen, die der Journalist oder die Journalistin selbst verfasst hat (Annotationskriterium 5). Dies zeigen die Tabellen 3 bzw. 4:
| Kopula esser | Andere Kopula |
||
| Morphologische Konkordanz | [+] | 129 (98,5 %) | 12 (66,7 %) |
| [–] | 2 (1,5 %) | 6 (33,3 %) | |
Morphologische Konkordanz prädikativer Adjektive nach Kopula.
| Zitierte direkte Rede [+] | Zitierte direkte Rede [–] | ||
| Morphologische Konkordanz | [+] | 33 (91,7 %) | 108 (95,6 %) |
| [–] | 3 (8,3 %) | 5 (4,4 %) | |
Morphologische Konkordanz prädikativer Adjektive gemäß "zitierte direkte Rede".
In den Beispielen (3) und (4) wurden bereits zwei Okkurrenzen nicht konkordanter prädikativer Adjektive für esser sein und tgnair halten gezeigt. Beispiele (5) und (6) beinhalten zwei weitere nicht-konkordante Fälle mit anderen Kopulae als esser, nämlich mit render machen (5) und gnir werden (6). Beispiel (6) entstammt – wie bereits (4), nicht aber (3) – zitierter direkter Rede; Bei Beispiel (5) handelt es sich um eine Produktion der Journalistin:
Ils collavuratuors da la TESSVM rendan attent a lur giasts ch=i ...
die Mitarbeiter von der TESSVM machen aufmerksam.{/scm.sg} {/scdom} ihre Gast{/scm.pl} dass=es [...]
Die Mitarbeiter der TESSVM machen ihre Gäste darauf aufmerksam, dass es ...
"L=idea es da referir e discutir davart temas ed intops chi=ns inscuntran cun gnir vegl", disch Koller.
die=Idee ist zu referieren und diskutieren über Themen und Hindernisse die={/sc1pl.akk} begegnen mit werden alt.{/scm.sg} sagt Koller
"Die Idee ist es, über Themen und Hindernisse zu referieren und zu diskutieren, die uns begegnen, wenn wir alt werden", sagt Koller.
Hinsichtlich Annotationskriterium 6, "SprecherIn", ist Folgendes festzuhalten: Die achtkonkordanzlosen Okkurrenzen unter den 149 nicht maskulin-singularischen Belegen verteilen sich auf vier von insgesamt 33 Schreibenden bzw. Zitierten (Sprecher A = 2 Fälle; Sprecher B = 1 Fall; Sprecher C = 2 Fälle; Sprecherin D = 3 Fälle). Sprecher C und Sprecherin D liefern 5/8 (62,5 %) der konkordanzlosen Belege, was insofern nicht überrascht, als beide für La Quotidiana tätige JournalistInnen sind und gemeinsam auch 72 aller 149 relevanten Okkurrenzen (48,3 %) liefern.
Die "klassische" Methode, um auf Basis eines Datensatzes mit abhängigen Okkurrenzen zu ermitteln, welche Prädiktorvariablen den Wert einer abhängigen Variable in einer Gesamtbevölkerung wie beeinflussen, ist die gemischte logistische Regressionsanalyse. Diese kann jedoch hier nicht angewendet werden, da eine der Grundvoraussetzungen für gemischte logistische Regressionsmodelle nicht erfüllt ist: Die Zahl der Okkurrenzen für den seltensten Wert einer abhängigen Variable im analysierten Datensatz muss mindestens 10 Mal größer sein als die Summe aller Wertmöglichkeiten (level) aller fixed effect-Prädiktorvariablen (Levshina 2015, 257). Diese Summe ist in der vorliegenden Fallstudie 6 ( vgl. Abschnitt ; Annotationskriterien 3–5). Um eine gemischte logistische Regressionsanalyse durchführen zu können, müssten also mindestens 60 nicht-konkordante prädikative Adjektive im Datensatz enthalten sein. Diese Zahl erreicht unser Datensatz mit acht nicht annähernd (vgl. Tabelle 2).
Eine alternative inferentiell-statistische Methode, die in der empirischen Linguistik der letzten 10 Jahre vermehrt an Bedeutung gewonnen hat, ist die conditional inference tree-basierte random forest-Modellierung (Baayen/Tagliamonte 2012; Levshina 2015, 291 ff.). Sie ist robust gegenüber Datenknappheit und stellt keine Voraussetzungen wie die im vorigen Absatz für die gemischte binomiale logistische Regressionsmodellierung beschriebene. Das Grundprinzip conditional inference tree-basierter random forest-Modellierung, implementierbar in R mit dem Zusatzpaket party (Hothorn et al. 2006a; Hothorn et al. 2006b), ist – stark vereinfacht – das folgende: Der Algorithmus testet zunächst, welche Prädiktorvariable innerhalb des Datensatzes den Wert der abhängigen Variable statistisch signifikant und am stärksten beeinflusst. Dann wird der Datensatz auf Basis der Werte dieser Prädiktorvariable partitioniert. Derartige Partitionierungen werden so lange für alle Prädiktorvariablen wiederholt, bis keine weiteren statistisch signifikanten Partitionen des Datensatzes mehr möglich sind. In einem zweiten Schritt werden dann sog. random forests erstellt. Random forests bestehen aus einer frei wählbaren Anzahl mehrerer conditional inference trees, die allerdings jetzt lediglich auf einem randomisierten Subset des ursprünglichen Datensatzes basieren. Mittels sog. Permutation (deren Funktionsweise dem besser bekannten bootstrapping in Teilen ähnelt) werden nun wiederum conditional importance scores ermittelt. Diese ordnen die verschiedenen Prädiktorvariablen hinsichtlich ihrer Wichtigkeit für die Wertvorhersage der abhängigen Variable – und zwar nicht nur für den untersuchten Datensatz selbst, sondern auch für zukünftige, potentielle Daten (= inferentiell-statistisch).10
Abbildung 4 zeigt den auf Basis aller 149 nicht maskulin-singularischer Belege ue. prädikativer Adjektive erstellten conditional inference tree; "yes" steht für erfolgte morphologische Konkordanz, "no" für deren Ausbleiben:
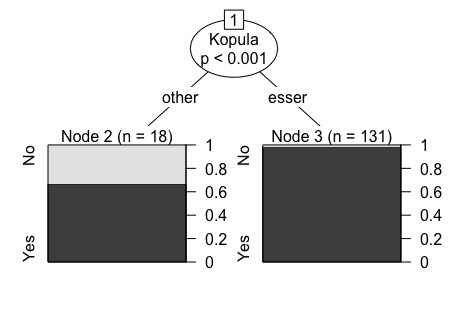
Conditional inference tree; alle 149 nicht maskulin-singularische Belege.
Wie in Abbildung 4 ersichtlich, ist innerhalb des Datensatzes lediglich die Kopula ein statistischer signifikanter Prädiktor für die Genus– und Numeruskonkordanz. Ist die Kopula nicht esser sein, so erhöht dies signifikant die Wahrscheinlichkeit für ein Ausbleiben der Konkordanz (Node 2 vs. Node 3). Die Wahrscheinlichkeiten, die den Prozentzahlen in Tabelle 3 entsprechen, können jeweils rechts neben den Box-Plots abgelesen werden. Auch die inferentiell-statistische random forest-Analyse, die auf 1000 subsetbasierten conditional inference trees beruht (mit mtry = 2; zu diesem Befehl, vgl. Levshina 2015, 297), bestätigt das Ergebnis aus Abbildung 4. Dies zeigt Abbildung 5, die die konditionelle Wichtigkeit der vier Prädiktorvariablen – unter Berücksichtigung der jeweils anderen drei Prädiktorvariablen – für die Genus- und Numeruskonkordanz der prädikativen Adjektive visualisiert. "Konditionell" bedeutet im Hinblick auf Abbildung 5 zudem, dass die abgebildeten absoluten Werte vernachlässigbar sind, weil die Aussagekraft der Grafik in der hierarchischen Beziehung der Werte zueinander begründet liegt.
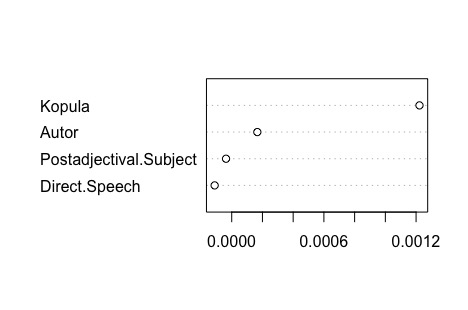
Random forest-basierte konditionelle Wichtigkeit der vier Prädiktorvariablen.
Die präsentierten Ergebnisse der conditional inference tree-basierten random forest-Modellierung sind keinesfalls frei von Problemen. So ist es beispielsweise denkbar, dass der/die jeweilige Journalist:in in zitierter direkter Rede präskriptive Korrekturen an ursprünglich konkordanzlosen Okkurrenzen durchgeführt hat. Ist dies der Fall, wäre die wirkliche Wahrscheinlichkeit von Nicht-Konkordanz für den Wert [+] des Prädiktors "zitierte direkte Rede" höher als diejenige, die Abbildungen 4 und 5 zugrundeliegt. Dies wiederum könnte die Entstehung neuer, in Abbildung 4 und 5 nicht erfasster Interaktionen zwischen zwei oder mehreren Prädiktorvariablen zur Folge haben und/oder die Wichtigkeit von "Kopula" vermindern. Damit werden die in diesem Kapitel präsentierten inferentiell-statistischen Ergebnisse angreifbar. Dieses Problem kann mit Daten aus medial schriftlichen digitalen ue. Medien aber nicht gelöst werden. Eine mögliche Alternative wäre freilich, große Mengen spontansprachlichen audiovisuellen Fernseh- und Radiomaterials zu analysieren, wo nachträgliche Korrekturen kaum möglich sind. Derartiges Material existiert zwar (siehe Abschnitt ), eine Erhebung, die akzeptable Belegzahlen liefert, ist aber bei jetziger Datenaufbereitungslage nahezu unmöglich. Dies zeigt unter anderem das folgende Kapitel, das die zweite Fallstudie zum Unterengadinischen vorstellt.
4. Fallstudie 2: die palatalen Affrikaten /t͡ʃ/ und /t͡ɕ/ im Unterengadinischen
Die zweite Fallstudie widmet sich der Frage, ob es möglich ist, anhand der wenigen zur Verfügung stehenden digitalen audiovisuellen bündnerromanischen Medien ein bereits bekanntes Phänomen des lautlichen Sprachwandels einerseits (weiter) zu dokumentieren und andererseits zu überprüfen, ob diesbezüglich mithilfe von Labordaten gewonnene Ergebnisse auch mit online frei zugänglichen Spontan- oder Semispontandaten replizierbar sind. Es wird deutlich, dass dies – mit kleineren Einschränkungen – prinzipiell möglich ist, das Zusammentragen eines hinsichtlich aller Bedingungen mit Experimentaldaten vergleichbaren Korpus jedoch im besten Falle mit stark disproportionalem Zeitaufwand bewerkstelligt werden kann. Abschnitt des Kapitels führt in die Fragestellung ein, erläutert die notwendigen Hintergründe zur Phonologie des Unterengadinischen und umreißt Methodologie und Ergebnisse bereits bestehender Studien. Abschnitt beschreibt die sprachlichen Daten sowie die Methodologie der Pilotstudie. In Abschnitt folgen schließlich deren Ergebnisse und eine abschließende Diskussion.
4.1. Die palatalen Affrikaten im /t͡ʃ/ und /t͡ɕ/ im Unterengadinischen
Wie bereits in Abschnitt angesprochen, ist die Unterscheidung einer eigenen rätoromanischen Untergruppe, bestehend aus Friaulisch, Dolomitenladinisch und Bündnerromanisch, innerhalb der romanischen Sprachen in der Forschung umstritten (siehe Liver 2010, 15 ff. für eine zusammenfassende Darstellung der Diskussion). Sie geht zurück auf Graziadio Isaia Ascolis Saggi Ladini (1873), der sie in erster Linie anhand eines lautlichen Kriteriums, nämlich der Palatalisierung von lat. c (/k/) nicht nur vor /e/ und /i/, wie nahezu überall in der Romania, sondern auch vor /a/ vornahm. Dass sich die rätoromanischen Varietäten diesbezüglich im Gegensatz zum angrenzenden Italienischen parallel verhalten, zeigt Tabelle 5:
| ce, i | ca | |
| Latein | cena | casa |
| Italienisch | cena [t͡ʃ] | casa [k] |
| Unterengadinisch (brom.) | tschaina [t͡ʃ] | chasa [c/t͡ɕ] |
| Gadertalisch (dolomitenladinisch) | cëna [t͡ʃ] | ćiasa [t͡ɕ] |
| Friaulisch | cene [t͡ʃ] | cjase [c] |
| Lautlicher Kontext | Ergebnis | Unterengadinisch | Surselvisch | Bedeutung |
| -o, -ŭ | velarer Plosiv: [k] | cuort | cuort | kurz |
| -e, -i | post-alveolare Affrikate: [t͡ʃ] | tschêl
tschinch |
tschiel
tschun |
Himmel
fünf |
| -a, -ū | Palataler Plosiv bzw. palato-alveolare Affrikate: [c] ~ [t͡ɕ] | chan
chüna |
tgaun,
tgina |
Hund
Wiege |
- (stimmloser) palataler Plosiv, Trankription: [c], u. a. in Haiman/Benincà (1992), Liver (2010), Schmid (2010)
- (stimmlose) alveolo-palatale Affrikate, Trankription: [t͡ɕ], u. a. Taggart (1990)
Beide Varianten finden sich auch in Beschreibungen anderer Idiome ([t͡ɕ] für das Surmeirische beispielsweise in Anderson 2016). Dabei ist [c] innerhalb der Romanistik die traditionellere Transkriptionsweise, während der Gebrauch von [t͡ɕ] erst in neuerer Zeit aufgekommen ist. Letzterem werden wir uns auch für den verbleibenden Teil dieses Aufsatzes anschließen. Tatsächlich unterscheiden sich die beiden Laute phonetisch nur wenig. Während der erste in vielen Sprachen als Allophon von /k/ vor vorderen Vokalen auftreten kann, ist letzterer vor allem aus dem Polnischen bekannt (Jassem 2003). In jedem Fall können beide als typologisch stark markiert angesehen werden: Der palatale Plosiv [c] kommt in knapp 12 % der 451 in der UPSID-Datenbank (Maddieson/Precoda 1984) enthaltenen Sprachen vor; die alveolo-palatale Affrikate nur in unter 3 %. Darüber hinaus ist es in Bezug auf das Bündnerromanische letztendlich nicht nur möglich, sondern sogar wahrscheinlich, dass neben individueller Variation auch Unterschiede zwischen den Idiomen vorliegen (vgl. Schmid 2010, 188). Hinweise darauf, dass insbesondere das Surselvische im Vergleich zu den anderen Idiomen stärker zu einem palatalen Plosiv tendiert, finden sich in Brunner (1963).
Bedeutender als die konkrete phonetische Realisierung des entsprechenden Lautes ist für das brom. Sprachsystem zweifelsohne seine phonologische Bedeutung. So haben die beiden oben dargestellten Palatalisierungen nicht nur zwei unterschiedliche Laute, sondern auch zwei Phoneme hervorgebracht, wie beispielsweise die folgenden ue. Minimalpaare zeigen.
- lönch [løɲt͡ɕ] lange vs. löntsch [løɲt͡ʃ] weit
- (el, ella) chatta [ˈt͡ɕatɐ] (er, sie) findet vs. tschatta [ˈt͡ʃatɐ] Tatze
Zwar kommt insbesondere die alveolo-palatale Affrikate (/t͡ɕ/) im Unterengadinischen (und allgemein im Bündnerromanischen) häufig vor, die funktionale Auslastung der Opposition /t͡ɕ/ : /t͡ʃ/ ist jedoch äußerst gering, was sich u. a. darin zeigt, dass Minimalpaare trotz der obigen Beispiele sehr selten sind. Diese Tatsache – ebenso wie die hohe typologische Markiertheit und die geringe artikulatorische Distanz zwischen den beiden sich gegenüberstehenden Lauten – legt nahe, dass die Opposition früher oder später aufgegeben werden könnte (vgl. Penny 2000, 42-50). So haben zahlreiche oberitalienische Varietäten, die ursprünglich ebenfalls über ein Palatalphonem /t͡ɕ/ oder /c/ verfügten, dieses wieder verloren (Schmid 1956, 53-80). Den Zusammenfall eines solchen Palatallautes mit der post-alveolaren Affrikate im geographisch nicht allzu weit vom Engadin und Münstertal entfernten Nonstal etwa, der sich im Laufe des 20. Jahrhunderts vollzogen hat, beschreibt Politzer (1967, 49).
Hinweise auf einen solchen Zusammenfall von /t͡ɕ/ und /t͡ʃ/ auch im Unterengadinischen sind – neben den mittlerweile dazu entstandenen Arbeiten (siehe unten) – leicht zu finden. So deuten beispielsweise häufige Verwechslungen von orthographischem <ch> und <tsch>, wie man sie etwa in online publizierten Liedtexten finden kann, darauf hin, dass zumindest manche Sprecher des Unterengadinischen Schwierigkeiten haben, die durch diese Grapheme wiedergegebenen Phoneme klar zu unterscheiden. Ein Beispiel hierfür findet sich im Text des Liedes „Eu less crajer“ der Rock-Band Rebels, welcher unterhalb des Musikvideos bei YouTube transkribiert wurde:
In *chercha da mumaints am metti di per di
Tag für Tag mache ich mich auf die Suche (ue. tschercha) nach Momenten
Das auf lat. circare, eigentlich um etwas herumgehen, etwas umkreisen zurückgehende tschercha [ˈt͡ʃɛrtɕɐ] enthält durch regelmäßigen Lautwandel (vgl. Tabelle 6) zwei unterschiedliche aus lat. c- entstandene Phoneme, was sich auch in der heutigen Graphie widerspiegelt. Ein weiteres Beispiel enthält der Text des Liedes „Engiadina sur tuot!“ der engadinischen Death-Metal-Band Wacht, in welchem statt <löntsch (davent)> (weit) weg <lönch> lange geschrieben wird. Von einer nicht unbeachtlichen Häufigkeit des Phänomens zeugt auch die Tatsache, dass eine Überprüfung auf Rechtschreibfehler der insgesamt 337 auf Unterengadinisch verfassten SMS im online zur Verfügung stehenden Swiss SMS Corpus (Stark/Ueberwasser/Beni 2009-2015) eine Anzahl von 13 Verwechslungen von <tsch> und <ch>, die auf vier verschiedene Verfasser und Verfasserinnen zurückgehen, ergeben hat. Die Auszüge in (8) – (10) zeigen drei Beispiele:
eu n'ha discurrü e *chellas han tadlà
(Beleg 25388)
Ich habe gesprochen und die anderen (ue. tschellas) haben zugehört.
Vain mangia bain quia a basilea e jain amo baiver *altsch.
(Beleg 25066)
Wir haben gut gegessen hier in Basel und gehen noch etwas (ue. alch) trinken
Vain sten *patschific
(Beleg 25079)
Wir haben es ziemlich lässig (ue. pachific).
Neben diesen schriftlichen Hinweisen liegen mit Schmid (2010), Schmid/Grimaldi (2011) und Schmid/Negrinelli (2018) – wie bereits erwähnt – mittlerweile mehrere Studien vor, die das Phänomen anhand experimenteller Daten untersuchen. Während sich die erste von diesen der akustischen Analyse der Phoneme /c ɟ t͡ʃ d͡ʒ k ɡ j/ bei drei Unterengadinisch-Sprecherinnen unterschiedlichen Alters widmet und Schmid/Grimaldi (2011) diese Datenbasis um zwei weitere, jüngere Sprecherinnen erweitert, liegt der Fokus in Schmid/Negrinelli (2018) stärker nur auf der Opposition zwischen /c/ und /t͡ʃ/. Zudem ist die untersuchte Gruppe mit zehn eher älteren Sprechern beiderlei Geschlechts aus den Orten Müstair und Santa Maria im Münstertal größer.11 Ein klarer Vorteil aller drei Untersuchungen ist, dass die sprachlichen Daten aller Sprecherinnen und Sprecher durch die stark kontrollierte Erhebungsweise gut vergleichbar sind: Verwendet wurde jeweils eine Serie von Wörtern, in denen das entsprechende Zielsegment wortinitial und vor einem von sieben Vokalen stand. Diese mussten zunächst von den Teilnehmenden selbst aus dem Deutschen übersetzt und dann dreimal in einem Trägersatz nach dem bestimmten Artikel (d. h. nach /a/ oder /l/) gelesen werden.
Zur Unterscheidung der produzierten Laute untersuchte Schmid (2010) die folgenden akustischen Werte: Dauer der Verschlussphase und Verschlusslösung, Intensität und Schwerpunkt (engl. centre of gravity). Während sich in Bezug auf die ersten beiden Korrelate keine signifikanten Unterschiede zwischen Palatal und post-alveolarer Affrikate ergaben, wiesen die drei Sprecherinnen hinsichtlich des Schwerpunkts eine große Variation auf. Es handelt sich dabei um ein Maß des ersten spektralen Moments, das dazu dient, durch die Berechnung einer Art „Durchschnittsfrequenz“ aus dem aperiodischen akustischen Signal, den Klang von Frikativen (oder des frikativischen Anteils von Affrikaten) zu unterscheiden (vgl. Schmid/Grimaldi 2011, 52; Schmid/Negrinelli 2018, 505 f.; Gordon/Barthmaier/Sands 2002). Die Höhe des gemessenen Hertz-Wertes entspricht dabei der wahrgenommenen Tonhöhe der Verschlusslösung und korreliert mit der Position des Verschlusses auf der horizontalen Achse (Opposition: vorne vs. hinten).
Schmid/Grimaldi (2011) und Schmid/Negrinelli (2018) schließlich stützen ihre Untersuchung vornehmend auf die Analyse ebendieses Schwerpunktes. Sie finden heraus, dass sich die durchschnittlichen Schwerpunkte von /c/ und /t͡ʃ/ zwischen den Teilnehmenden stark unterscheiden, während die Durchschnittswerte der beiden Laute sprecherintern meist kaum voneinander abweichen. Obgleich der Abstand bei den ältesten Sprechern etwas größer ist, scheint nur eine einzige, nämlich die älteste Sprecherin in Schmid/Negrinelli (2018), die beiden Laute klar zu unterscheiden. Hierauf basierend schlussfolgern die Autoren, dass der Zusammenfall der beiden (ehemaligen) Phoneme im Münstertal bereits nahezu gänzlich vollzogen ist.
4.2. Daten und Methodologie
Um probeweise zu untersuchen, ob der in den oben beschriebenen akustischen Experimenten belegte, weitgehende Zusammenfall von /t͡ʃ/ und /c/ bzw. /t͡ɕ/ im Unterengadinischen auch anhand online zugänglicher Sprachdaten gezeigt werden kann, wurde eine Reihe von Fernseh- und Radioproduktionen aus Play RTR, der Mediathek der SRG-Tochter RTR (vgl. Abschnitt ), ausgewählt, in denen Unterengadinisch-SprecherInnen zu Wort kamen. Es handelte sich dabei um zwei Auszüge aus der Nachrichtensendung Telesguard sowie insgesamt fünf unterschiedliche Radio-Beiträge aus den Formaten Da num e da pum, Marella, Il chavazzin dal di und La cifra, die im Frühjahr und Herbst 2019 ausgestrahlt wurden. Die darin enthaltenen stimmlosen post-alveolaren und alveolo-palatalen Affrikaten wurden unabhängig von ihrer Position im Wort in Praat TextGrids annotiert (Boersma/Weenink 2020). In einem nächsten Schritt wurde mithilfe eines Skripts (Rentz 2017) ihr erstes spektrales Moment, d. h. ihr Schwerpunkt (engl. centre of gravity), bestimmt, da dieser Wert sich in den bestehenden Studien als am besten zur Unterscheidung der fraglichen Laute geeignet erwiesen hatte (siehe Abschnitt ).
Insgesamt konnten auf diese Art und Weise Segmente von sieben Sprechern und Sprecherinnen untersucht werden. Dabei handelte es sich um drei Mitarbeiter und eine Mitarbeiterin von RTR, sowie drei Interviewpartner, die für öffentliche Institutionen wie den (im Engadin und Münstertal befindlichen) Schweizer Nationalpark oder das Tiefbauamt Graubünden arbeiteten. Ihr genaues Alter konnte nicht ermittelt werden, dürfte aber schätzungsweise grob zwischen 25 und 60 gelegen haben. In Bezug auf die Herkunftsorte der Teilnehmenden sind genauere Angaben möglich: Mit den Dörfern Guarda, Ardez, Sent und Ramosch ist hier mehr oder minder das Zentrum des Unterengadins um das Städtchen Scuol abgebildet.
4.3. Ergebnisse und Diskussion
Auf die in Abschnitt dargestellte Weise konnte eine Anzahl von insgesamt 129 ue. Affrikaten untersucht werden. Wie in Tabelle 7 dargestellt, war das Verhältnis zwischen post-alveolarer und alveolo-palataler Affrikate dabei nicht ausgewogen, da letztere im Unterengadinischen häufiger vorkommt als erstere; im untersuchten Datensatz beträgt das Verhältnis etwa 3:1.
| Anzahl | Prozent | |
| /t͡ɕ/ | 98 | 76 % |
| /t͡ʃ/ | 31 | 24 % |
| gesamt | 129 | 100 % |
| Segment | /t͡ɕ/ | /t͡ʃ/ |
| Mittelwert | 6123 Hz | 6024 Hz |
| Standardabweichung | 530 Hz | 700 Hz |
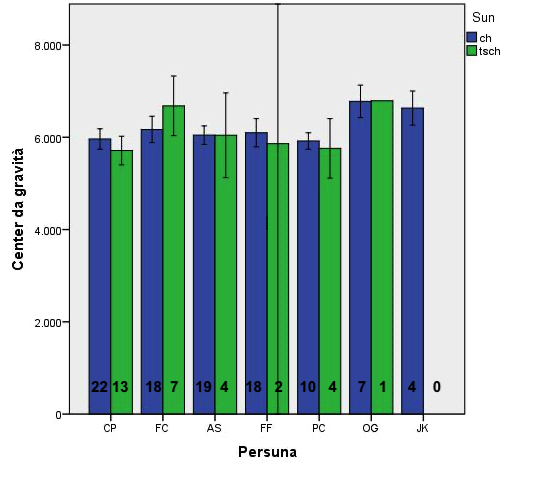
Schwerpunkt (erstes spektrales Moment) der alveolo-palatalen und der post-alveolaren Affrikate bei 7 Sprecherinnen und Sprechern des Unterengadinischen (in Hz).
- Hintergrundinformationen zu den Sprecher:innen sind oft nur teilweise oder sogar überhaupt nicht zugänglich (z. B. Beruf und Herkunftsort bekannt, Alter jedoch nicht). Darüber hinaus kann es aufgrund diatopischer Variation – selbst bei räumlich sehr kleinen Varietäten wie dem Unterengadinischen – ein Problem sein, wenn nicht alle Sprecher:innen einer Studie aus dem selben Ort kommen.
- Der zeitliche Aufwand ist hoch. Da keine Transkriptionen zur Verfügung stehen, müssen in der Regel große Datenmengen in Bezug auf den Untersuchungsgegenstand „durchgehört“ werden – oft vergebens (im vorliegenden Fall etwa viele mehrminütige Beiträge hinsichtlich post-alveolarer Affrikaten).
- Gute Sprachkenntnisse sind notwendig – was in Bezug auf Minderheitensprachen heute sicherlich nur die wenigsten Romanistinnen und Romanisten leisten können. Gerade für das Rätoromanische ist dieser Punkt in mehrerlei Hinsicht von Bedeutung: Zunächst enthalten die Medienprodukte von RTR gemeinhin eine bunte Mischung von fünf Idiomen + Dachsprache Rumantsch Grischun. In einem ersten Schritt muss folglich beim Hören das gewünschte Idiom sicher identifiziert werden können, bevor der entsprechende Redebeitrag „durchsucht“ werden kann. Weiterhin ist freilich auch für die fehlerfreie Transkription und/oder Annotation des Gesagten für dessen Verständnis nahezu unabdingbar.
- Es kann nicht gesteuert werden, was die zur Verfügung stehenden Sprachdaten beinhalten. Im vorliegenden Falle etwa war nicht nur das seltene Vorkommen der post-alveolaren Affrikate an sich ein Problem, sondern darüber hinaus auch die Tatsache, dass die untersuchten Segmente in völlig unterschiedlichen lautlichen Kontexten auftraten (beispielsweise in betonten und unbetonten Silben, am Wortanfang und Wortende, intervokalisch oder nach Konsonanten) und sich dies zusätzlich von SprecherIn zu SprecherIn stark unterschied. Dieses Problem könnte zwar möglicherweise durch eine beträchtliche Vergrößerung der untersuchten Datenmenge (und ggf. gezielte Auswahl von Test-Items) vermindert werden, dies brächte jedoch eine Beschränkung der Untersuchung auf die Sprache von Radio- und FernsehmoderatorInnen mit sich, die, wie oben ausgeführt, ebenfalls nicht unproblematisch ist.
Zusammenfassend lässt sich also festhalten, dass mess-phonetische Untersuchungen anhand von Sprachdaten aus Online-Medien zwar prinzipiell möglich sind, jedoch eine Vielzahl von Schwierigkeiten und Problemen mit sich bringen. Verlässliche Ergebnisse, die auch eine seriöse inferentiell-statistische Analyse zulassen, können mit angemessenem Aufwand sicherlich nur mithilfe von kontrollierten Experimentaldaten gewonnen werden. Zur qualitativen Dokumentation oder für Pilotstudien, die späteren Experimenten vorausgehen, hingegen bieten Online-Medien angesichts des Fehlens audiovisueller Korpora für Minderheitensprachen freilich eine wertvolle alternative Datenquelle.
5. Vorüberlegungen für ein digitales Korpus des Bündnerromanischen
In den Kapitel und wurde gezeigt, dass der Nutzung digitaler brom. Medien (vgl. Abschnitt ) für die sprachwissenschaftliche Forschung deutliche Grenzen gesetzt sind. Gleichzeitig existieren bis dato keine umfangreichen digitalen und für sprachwissenschaftliche Untersuchungen aufbereitete Korpora (vgl. Abschnitt ). In diesem Abschnitt, der geichzeitig den vorliegenden Beitrag beschließt, sollen deshalb erste Vorüberlegungen angestellt werden, die im Zuge einer Korpuserstellung für das Bündnerromanische beachtet werden sollten. Abschnitt präsentiert zunächst einen ersten, möglichen Rahmen zur Korpuserstellung. In diese Überlegungen fließen auch die Probleme ein, die im Zuge der empirischen Pilotstudien in Kapitel und aufgetreten sind. Abschnitt schließlich fasst – ohne Anspruch auf Vollständigkeit – die Quellen zusammen, aus denen das Sprachmaterial für ein digitales Korpus des Bündnerromanischen stammen könnte.
5.1. Aufbau und Anforderungen
Ziel des vorliegenden Abschnittes ist es, Anforderungen an ein zukünftiges, multimediales Korpus des Bündnerromanischen zu skizzieren, die sich einerseits aus den Problemen der hier durchgeführten Pilotstudien, die ohne ein solches Korpus auskommen mussten, und andererseits aus Vorüberlegungen allgemeinerer Art ergeben.
Zunächst sollte eine solche Datenbank online zugängig sein. Da sie idealerweise nicht nur der Forschungsgemeinschaft, sondern auch den Bünderromanen und Bündnerromaninen selbst (z. B. Lehrkräften) dienen soll, ist es überdies wünschenswert, den Zugang gänzlich kostenfrei zu ermöglichen. Eine leichte Bedienbarkeit muss nicht eigens erwähnt werden (zum technischen Aufbau und der Gestaltung von Suchmodalitäten und Abfragesystemen siehe z. B. Bubenhofer 2020).
Zweifelsohne muss ein brom. Online-Korpus in mehreren Schritten entstehen, deren erster eine durchsuchbare reine Textdatenbank ist, die jedoch bereits möglichst umfassende Informationen zu Verfasser (Alter, Herkunft, sozioökonomische Informationen) sowie zur Entstehung des Textes (Quelle, Genre, Entstehungszeitraum, Veröffentlichung) enthalten sollte. Als Vorbild könnte hierfür z. T. die okzitanische Textdatenbank BaTelÒc (Bras/Vergez-Couret 2016) dienen, die in Zusammenarbeit mit Buchverlagen literarische Werke aus verschiedenen Dialekten durchsuchbar macht. Bereits auf dieser Stufe sollte klar zwischen den einzelnen Idiomen sowie Rumantsch Grischun unterschieden werden, was einerseits bedeutet, dass die jeweilige Varietät der enthaltenen Texte vermerkt und andererseits das Korpus gezielt nur in Bezug auf eine oder mehrere Varietäten durchsuchbar sein muss.
In einem nächsten Schritt sollten die Originaltexte dergestalt bearbeitet werden, dass beispielsweise Rechtschreibfehler wie sie in Online-Kommentaren oder SMS häufig sind (siehe Vorstudie in Abschnitt ) kein Hindernis mehr für das Finden eines möglichen Beleges sind, während gleichzeitig der Zugriff auf die ursprüngliche Orthographie weiterhin möglich sein muss.
Diese „Dopplung“ der Texte, in der sich Original und bearbeitete bzw. annotierte Version gegenüberstehen und gleichermaßen zur Verfügung stehen, würde sich ohnehin weiter verstärken, sobald die Funktionalität des Korpus idiomübergreifend erweitert werden sollte. Dafür schlagen wir zunächst eine Lemmatisierung der Texte auf Rumantsch Grischun vor. Eine Suchanfrage in der standardisierten Dachvarietät würde trotz orthographischer, morphologischer und teilweise auch lexikalischer Unterschiede Suchergebnisse aus allen Idiomen anzeigen. Bei einer Lemmatisierung könnten beispielsweise durch Eingabe des Infinitivs eines Verbes sämtliche Okkurrenzen desselben in allen grammatischen Wortformen und in allen Idiomen gefunden werden. Idealerweise sollte dann, in einem weiteren Arbeitsschritt, auch die Suche nach bestimmten Wortformen möglich sein. Dies hätte beispielsweise die Studie in Kapitel erheblich vereinfacht, weil alle nicht-maskulin-singularischen Adjektive einfach hätten identifiziert werden können. Hierfür wäre allerdings eine morphologische Annotation des Korpus genauso notwendig wie ein part of speech-liTagging. Der eventuelle spätere Einbezug weiterer Informationen, beispielsweise im Rahmen einer syntaktischen oder informationsstrukturellen Annotation, sollte von Anfang an mitgedacht werden.
Um diese Schritte so einfach und wenig arbeitsintensiv wie möglich umsetzen zu können, sollte unbedingt auf bestehende Werkzeuge für andere Sprachen zurückgegriffen werden. Gute Erfahrungen mit solchen Anpassungen bereits für andere Sprachen verfügbarer Programme und einem automatisieren Training der so geschaffenen Tools sind beispielsweise im Rahmen des Projektes RESTAURE mit dem morphosyntaktischen Analysierer/Parser TALISMANE (Vergez-Couret/Urieli 2015; Bernhard et al. 2018) gemacht worden, deren Ergebnis ein in Bezug auf morphologische Kategorien und parts of speech annotiertes Korpus des Okzitanischen von 12.000 Wörtern ist. Für das Bündnerromanische könnte sich beispielsweise die Anpassung von technischen Werkzeugen für das Italienische lohnen.
Eine Erweiterung/Ergänzung des Korpus um audio- (oder möglicherweise sogar audio-visuelle) Formate dürfte ungleich aufwändiger sein, da diese nur glücken kann, wenn sämtliche Audiodateien mit einem in gleicher Weise wie das Textkorpus annotierten und durchsuchbaren Transkript vorliegen. Des Weiteren muss zumindest bei längeren Audiodateien eine Möglichkeit geschaffen werden, Textstellen auch in der Datei unkompliziert identifizieren zu können. Hierfür ist eine Orientierung an Systemen wie TalkBank oder TEITOK (Janssen 2014–)) sinnvoll (als Beispiele mögen das hier zugängliche Emigranto-Korpus von Duran Eppler, sowie das judenspanische CoOrAJe von Quintana dienen). Auch das Corpus oral y sonoro del español rural (COSER) ermöglicht eine wenig arbeitsintensive Durchsuchung von Audio-Dateien. Sollten Videos integriert werden, kann das Korpus El parlar salat de la Costa Brava (Perea 2017) als Vorbild dienen. Bei entsprechender Umsetzung und Umfang des Korpus hätte dies beispielsweise die Studie in Kapitel deutlich erleichtert: Über eine Suche auf Rumantsch Grischun nach orthographischem <ch> und <tg> für die alveolo-palatale Affrikate und nach <tsch> für die post-alveolare könnten diese Laute deutlich leichter in entsprechenden Audiodateien identifiziert und nicht nur für das Unterengadinische sondern auch für andere Idiome untersucht werden. Ohne allzu großen Aufwand wäre es möglich gewesen, die lautlichen Kontexte, in denen die betreffenden Laute untersucht werden sollten, ähnlich einer Laborstudie klar zu definieren und einzuschränken und so qualitativ bessere und validere Ergebnisse zu erzielen.
Es ist indes klar, dass ein solches Unterfangen eines Korpus, das nicht nur brom. Texte, sondern darüber hinaus eine große Anzahl transkribierter Audiodateien enthält, nur im Rahmen eines Großprojektes realisiert werden kann.
5.2. Mögliche Quellen für Sprachmaterial
Im vorliegenden Abschnitt werden mögliche Quellen zusammengefasst, aus denen das in einem zu erstellenden digitalen Korpus des Bündnerromanischen enthaltene Sprachmaterial stammen könnte. Dies geschieht sowohl in Rückgriff auf Abschnitte und als auch unter Einschluss einiger weiterer, noch unbesprochener relevanter Quellen (siehe unten). Da die Aufbereitung medial mündlicher Quellen aufwändiger ist als diejenige medial schriftlicher (siehe Abschnitt ) sind beide Quelltypen in Tabelle 9 getrennt dargestellt:
| medial schriftlich | linguistisch aufbereitete Ressourcen (siehe Abschnitt 2.2) | Bünderromanischer Teil des WhatsApp-Nachrichten Korpus WhatsUp Switzerland? |
| Bünderromanischer Teil des SMS-Nachrichten Korpus The Swiss SMS Corpus | ||
| Bündnerromanischer Teil der für An Crúbadán gecrawlten Texte | ||
| digital verfügbare Tageszeitungen & Zeitschriften (siehe Abschnitt 2.3) | La Quotidiana | |
| Engadiner Post/Posta Ladina | ||
| Punts | ||
| Il Chardun | ||
| andere Online-Medienformate (siehe Abschnitt 2.3) | Kurznachrichten von RTR auf Facebook | |
| battporta.ch | ||
| chattà.ch | ||
| latabla.ch | ||
| Bündnerromanische Wikipedia | ||
| Sonstiges | Homepages von Gemeinden, Museen, Vereinen etc. (s. u.) | |
| Soziale Netwerke (Facebook, Twitter, u. a.) (s. u.) | ||
| E-Books von Verlagen (s. u.) | ||
| Eventuell bereits beim Dicziunari Rumantsch Grischun (DRG) digitalisiertes Material (siehe Abschnitt 2.2) | ||
| medial mündlich | Radio- und TV-Material von RTR (siehe Abschnitt 2.3) | |
| Mozilla Common Voice (siehe Abschnitt 2.2) | ||
| Filistuccas e Fafanoias (s. u.) | ||
6. Fazit
Forschende, die sich mit sprachlichen Eigenschaften von Minderheitensprachen beschäftigen, stehen oft der schwierigen Frage gegenüber, welche sprachlichen Daten sie in ihren Untersuchungen auswerten können, um das (in der Regel spärlich) vorhandene Wissen zu erweitern. Aufgrund des Fehlens grundlegender sprachwissenschaftlicher Ressourcen, wie z. B. von Wörterbüchern oder Korpora, ist für viele Minderheitensprachen die einzige Alternative zum Rückgriff auf gedruckte literarische Werke häufig noch immer nur die klassische Feldforschung, d. h. Arbeit vor Ort. Dennoch sind in den letzten Jahren die Chancen der Digitalisierung von manchen Sprachgemeinschaften genutzt worden, so dass eine Reihe von Onlinezeitungen und -Radiosendern in Minderheitensprachen entstanden ist (z. B. das okzitanische Jornalet oder das asturianische Portal Asturies.com sowie die Radiosender Voce nustrale (korsisch) und Onde Furlane (friaulisch)). Daneben verfügen manche Kleinsprachen, wie beispielsweise das Bündnerromanische im Schweizer Kanton Graubünden, sogar über eigene öffentlich-rechtliche Medienanstalten, wie z. B. Radio- und Fernsehsender.
Der vorliegende Beitrag beschäftigte sich deshalb beispielhaft anhand zweier Fallstudien zum Unterengadinischen mit der Frage, ob Sprachdaten aus online zugänglichen Massenmedien angesichts fehlender digitaler sprachwissenschaftlicher Ressourcen linguistisch nutzbar gemacht werden können. Dabei konnte gezeigt werden, dass schriftliches Sprachmaterial aus Zeitungen sowie Audiobeiträge aus Radio und Fernsehen es zwar erlauben, Belege für Sprachwandelprozesse zu finden, eine umfassende Untersuchung der entsprechenden Phänomene jedoch ohne disproportional großen Aufwand seitens der Forschenden kaum möglich ist. So konnte im Falle prädikativer unterengadinischer Adjektive belegt werden, dass deren overte Konkordanz mit dem zugehörigen Subjekt in schriftlichen Quellen zum Teil fehlt. Darüber hinaus wurden Hinweise darauf gefunden, dass dies insbesondere dann der Fall sein könnte, wenn andere Kopula als esser 'sein' verwendet werden. Beides legt die Vermutung nahe, dass das Phänomen (a) von nicht-prototypischen, d. h. weniger frequenten und semantisch markierten Kopula-Konstruktionstypen ausgeht, und (b), dass es, da es sich bereits in distanzsprachlichen und medial-schriftlichen Registern belegen lässt, im mündlichen Gebrauch schon weiter fortgeschritten sein dürfte. Die zweite Fallstudie hat den bereits in einigen Experimentalstudien untersuchten, voranschreitenden Zusammenfall der unterengadinischen Phoneme /t͡ɕ/ und /t͡ʃ/ anhand von mündlichen Sprachdaten aus Radio- und Fernsehsendungen nachvollzogen. Dabei wurde allerdings auch deutlich, dass diese nicht dieselbe Qualität und Zuverlässigkeit bieten wie laborphonetisches Datenmaterial.
Es lässt sich folglich einerseits festhalten, dass Online-Medien zwar gute Möglichkeiten zur qualitativen sprachwissenschaftlichen Dokumentation sowie für Pilotstudien bieten, sie jedoch andererseits keinen vollwertigen Ersatz für (digital verfügbare) sprachwissenschaftliche Ressourcen darstellen. Vor diesem Hintergrund hoffen wir mit Kapitel , das Vorüberlegungen zur Konzeption eines umfassenden Online-Korpus des Bündnerromanischen anstellte, einen möglichen Weg hin zur dringend notwendigen Erstellung eines solchen aufgezeigt zu haben. Es bleibt zu hoffen, dass auch die Untersuchung kleinerer Sprachen im Zuge der Digitalisierung bald einfacher wird und es so gelingt, ihre sprachlichen Schätze ans Licht zu bringen.
Bibliographie
- Anderson 2016 = Anderson, Stephen (2016): Romansh (Rumantsch), in: Adam Ledgeway & Martin Maiden (Hrsgg.), Oxford Guide to the Romance Languages, Oxford, Oxford University Press, 168–184.
- ARLeF 2015 = ARLeF (Hrsg.) (2015): Cunduzion Sociolinguistiche, Udine, Agjenzie Regionâl pe Lenghe Furlane (Link).
- Arquint 2017 = Arquint, Jachen Curdin (42017): Vierv Ladin: gramatica elementara dal rumantsch d’Engiadina Bassa, Zürich, editionmevinapuorger.
- Ascoli 1873 = Ascoli, Graziadio Isaia (1873): Saggi Ladini, in: Archivio Glottologico Italiano 1, 1–556.
- Baayen/Tagliamonte 2012 = Baayen, Harald / Tagliamonte, Sali A. (2012): Models, Forests and Trees of York English: Was/Were Variation as a Case Study for Statistical Practice, in: Language Variation and Change 24 (2), 135–178.
- Bernhard et al. 2018 = Bernhard, Delphine (2018): Corpora with Part-of-Speech Annotations for Three Regional Languages of France: Alsatian, Occitan and Picard, in: Proceedings of LREC 11, May 2018, Miyazaki, Japan.
- Boersma/Weenink 2020 = Boersma, Paul / Weenink, David (2020): Praat: Doing Phonetics by Computer [Computer Program]. Version 6.1.10 (Link).
- Bonzanini 2016 = Bonzanini, Marco (2016): Mastering Social Media Mining with Python, Birmingham, Packt.
- Bras/Vergez-Couret 2016 = Bras, Myriam / Vergez-Couret, Marianne (2016): BaTelÒc: A Text Base for the Occitan Language, in: Vera Ferreira & Peter Bouda (Hrsgg.), Language Documentation and Conservation in Europe, Honululu, University of Hawai'i Press, 133–149.
- Brunner 1963 = Brunner, Rudolf (1963): Zur Physiologie der rätoromanischen Affrikaten tsch und tg (ch): ein Beitrag zur Kenntnis von palatalen und palatalisierten Artikulationen, in: Paul Zinsli (Hrsg.), Sprachleben der Schweiz. Sprachwissenschaft, Namenforschung, Volkskunde, Bern, Francke, 167–173.
- Darms 1989 = Darms, Georges (1989): Bündnerromanisch: Sprachnormierung und Standardsprache, in: Günter Holtus, Michael Metzeltin und Christian Schmitt (Hrsgg.), Lexikon der romanistischen Linguistik, vol. 3, Tübingen, Niemeyer, 827–853.
- de Benito Moreno/Estrada Arráez 2016 = de Benito Moreno, Carlota / Estrada Arráez, Ana (2016): Variación en las redes sociales: datos twilectales, in: Revista de Lingüística Iberoamericana 28, 77–114.
- Ethnologue = Lewis, Paul M. (Hrsg.) (162009): Ethnologue, Dallas, SIL International (Link).
- Furer Roveredo 2005 = Furer Roveredo, Jean-Jacques (2005): Eidgenössische Volkszählung 2000. Die aktuelle Lage des Romanischen, Neuchâtel, Bundesamt für Statistik (Link).
- Ganzoni 1983 = Ganzoni, Gian Paul (1983): Grammatica ladina. Grammatica sistematica dal rumantsch da l'Engiadina Bassa per scolars e creschüts da lingua rumantscha e francesa, Chur, Uniun dals Grischs/Lia Rumantscha.
- Gordon/Barthmaier/Sands 2002 = Gordon, Matthew / Barthmaier, Paul / Sands, Kathy (2002): A Cross-linguistic Acoustic Study of Voiceless Fricatives, in: Journal of the International Phonetic Association 32, 141–174.
- Grünert 2005 = Grünert, Matthias (2005): Bündnerromanische Schriftnormen Volkssprachliche und neolateinische Ausrichtungen in Romanischbünden zwischen der Mitte des 19. Jahrhunderts und den 1930er Jahren, in: Vox Romanica 64, 64–93.
- Haiman/Benincà 1992 = Haiman, John / Benincà, Paola (1992): The Rhaeto-Romance Languages, London, Routledge.
- Holtus 1989 = Holtus, Günter (1989): Bündnerromanisch: externe Sprachgeschichte, in: Günter Holtus, Michael Metzeltin und Christian Schmitt (Hrsgg.), Lexikon der romanistischen Linguistik, vol. 3, Tübingen, Niemeyer, 854–871.
- Hothorn et al. 2006a = Hothorn, Torsten / Zeileis, Achim / Hornik, Kurt (2006): Unbiased Recursive Partitioning: A Conditional Inference Framework, in: Journal of Computational and Graphical Statistics 15 (3), 651–674.
- Hothorn et al. 2006b = Hothorn, Torsten / Buehlmann, Peter / Dudoit, Sandrine / Molinaro, Annette / van der Laan, Mark (2006): Survival Ensembles, in: Biostatistics 7 (3), 355–373.
- Jassem 2003 = Jassem, Wiktor (2003): Polish, in: Journal of the International Phonetic Association 33, 103–107.
- Koch/Oesterreicher 2011 = Koch, Peter / Oesterreicher, Wulf (2011): Gesprochene Sprache in der Romania: Französisch, Italienisch, Spanisch, Berlin, New York, De Gruyter.
- Levshina 2015 = Levshina, Natalia (2015): How to Do Linguistics with R. Data Exploration and Statistical Analysis, Amsterdam/Philadelphia, John Benjamins.
- Liver 2010 = Liver, Ricarda (22010): Rätoromanisch. Eine Einführung in das Bündnerromanische, Tübingen, Narr.
- LR 2015 = LR (Hrsg.) (2015): Facts Rumantschs, Cuira, Lia Rumantscha (Link).
- Maddieson/Precoda 1984 = Maddieson, Ian / Precoda, Kristin: Updating UPSID, vol. UCLA Working Papers in Phonetics, 74, 104-114, Unter dem angegebenen Link hat Henning Reetz hat die Originaldaten aus der „UCLA Phonological Segment Inventory Database“ (UPSID) für Abfragen frei zugänglich gemacht. (Link).
- Muschalik 2018 = Muschalik, Julia (2018): Threatening in English. A Mixed-Method Approach, Amsterdam/Philadelphia, John Benjamins.
- Penny 2000 = Penny, Ralph (2000): Variation and Change in Spanish, Cambridge, Cambridge University Press.
- Perea 2017 = Perea, Maria-Pilar (2017): Arxiu audiovisual del parlar salat de la Costa Brava, Barcelona, Universitat de Barcelona (Link).
- Politzer 1967 = Politzer, Robert L. (1967): Beiträge zur Phonologie der Nonsberger Mundart, Bregenz, Ruß.
- Rentz 2017 = Rentz, Bradley (2017): Praat Script (Measuring Duration, Centre of Gravity, Standard Deviation, Skewness, and Kurtosis).
- Scannell 2007 = Scannell, Kevin P. (2007): The Crúbadán Project: Corpus Building for Under-Resourced Languages, in: Cahiers du Cental 5.
- Schmid 1956 = Schmid, Heinrich (1956): Über Randgebiete und Sprachgrenzen, in: Vox Romanica 15, 19–80.
- Schmid 1982 = Schmid, Heinrich (1982): Richtlinien für die Gestaltung einer gesamtbündnerromanischen Schritsprache «Rumantsch Grischun», Cuira, Lia Rumantscha.
- Schmid 1998 = Schmid, Heinrich (1998): Wegleitung für den Aufbau einer gemeinsamen Schriftsprache der Dolomitenladiner, San Martin de Tor; Vich/Vigo di Fassa, Istitut Cultural Ladin «Micurá de Rü»; Istitut Cultural Ladin «majon di fascegn».
- Schmid 2010 = Schmid, Stephan (2010): Les occlusives palatales du Vallader, in: Maria Iliescu, Heidi M. Siller-Runggaldier und Paul Danler (Hrsgg.), Actes du XXVe Congrès International de Linguistique et de Philologie Romanes, Tübingen, Niemeyer, 185-194.
- Schmid 2020 = Schmid, Heinrich (2020): Heinrich Schmid. Ausgewählte Schriften zum Rätoromanischen. Intgins scrits davart il retorumantsch, Zürich, editionmevinapuorger, (herausgegeben von David Paul Gerards und Philipp Obrist).
- Schmid/Grimaldi 2011 = Schmid, Stephan / Grimaldi, Mirko (2011): Caratteristiche spettrali di ostruenti palatali in alcune varietà romanze, in: Barbara Gili Fivela (Hrsg.), Contesto comunicativo e variabilità nella produzione e percezione della lingua, Rom, Bulzoni, 48–58.
- Schmid/Negrinelli 2018 = Schmid, Stephan / Negrinelli, Stefano (2018): Ostruenti palatali in due varietà retoromanze a confronto Maréo e Jauer, in: Roberto Antonelli, Martin Glessgen und Paul Videsott (Hrsgg.), Atti del XXVIII Congresso internazionale di linguistica e filologia romanza: (Roma, 18-23 Iuglio 2016), vol. 2, Straßburg, ELiPhi, Éditions de linguistique et de philologie, 498–514.
- Stark/Riedel 2013 = Stark, Elisabeth / Riedel, Isabelle (2013): L’accord du participe passé dans les SMS francophones du corpus SMS suisse, in: Romanistisches Jahrbuch 63, 116–138.
- Stark/Ueberwasser/Beni 2009-2015 = Stark, Elisabeth / Ueberwasser, Simone / Beni, Ruef (2009-2015): Swiss SMS Corpus, University of Zurich (Link).
- Taggart 1990 = Taggart, Gilbert (1990): Dictionnaire du vocabulaire fondamental: romanche vallader – français et français – romanche vallader, Chur, Lia Rumantscha.
- Ueberwasser/Stark 2017 = Ueberwasser, Simone / Stark, Elisabeth (2017): What’s up, Switzerland? A Corpus-Based Research Project in a Multilingual Country, in: Linguistik Online 84, 105–126 (Link).
- Vergez-Couret/Urieli 2015 = Vergez-Couret, Marianne / Urieli, Assaf (2015): Analyse morphosyntaxique de l’occitan languedocien : l’amitié entre un petit languedocien et un gros catalan, in: TALARE 2015, June 2015, Caen, France.
- Videsott 2001 = Videsott, Paul (2001): La palatalizzazione di CA e GA nell’arco alpino orientale. Un contributo alla delimitazione dei confini dell’Italia linguistica dell’anno 1000, in: Vox Romanica 60, 25-50.
- Weinreich 1953 = Weinreich, Uriel (1953): Languages in contact: Findings and Problems, New York, Linguistic Circle of New York.
- Zentrum für Demokratie Aarau 2019 = Zentrum für Demokratie Aarau (2019): Massnahmen zur Erhaltung und Förderung der rätoromanischen und der italienischen Sprache und Kultur im Kanton Graubünden. Evaluationsbericht im Auftrag des BAK, vol. Studienberichte des Zentrums für Demokratie Aarau, 16, Aarau, Zentrum für Demokratie Aarau (Link).