1. Forschungskommunikation
Die universitäre Lehre folgt - vom speziellen Fall der Didaktik abgesehen - der Forschung (und nicht etwa umgekehrt). Mit der Frage, was unter Forschung zu verstehen sei, brauchen wir uns nicht lange aufzuhalten. Einen guten Hinweis gibt bereits die Herkunft der englischen Bezeichnung research, die - wie jedes gute englische Wort - aus dem Fra. stammt, nämlich aus recherche, das wiederum vom Verb rechercher mit der ursprünglichen Bedeutung 'wiederholt, dauerhaft suchen' abgeleitet wurde. In diesem Sinn lässt sich Forschung immer noch als Suche nach fehlenden, bzw. adäquaten Wissensbeständen umschreiben: Forschung sucht methodisch nachvollziehbare Antworten auf theoretisch begründete Fragen.
Der Drang nach Wissenvermehrung, d.h. nach Forschung ist zweifellos eine anthropologische Konstante, wie Michel de Montaigne (Bd. III, Kap. 13, De l'experience) in Fortführung eines aristotelischen Prinzips 1 festgestellt hat:
IL N'EST desir plus naturel que le desir de cognoissance. ('Es gibt kein natürlicheres Verlangen als das nach Wissen.')
Alles andere als konstant sind jedoch die Rahmenbedingungen der Forschung, denn sie sind massivem historischen Wandel unterworfen; dazu gehören die Institutionen, die Finanzierungswege und nicht zuletzt die Formen der Kommunikation. Vor allem letztere wurden seit dem Aufkommen der Neuen Medien revolutioniert: Die Gutenberg-Galaxis (vgl. McLuhan 1962) strebt mit zunehmender, rasanter Geschwindigkeit auseinander, da die Gravitationskraft ihres Fixsterns, des gedruckten Buchs, immer schwächer wird; auch von der ehemaligen Leuchtkraft ist nurmehr ein matter Schimmer geblieben. In Forschungsprojekten, die mit Webtechnologie operieren, verläuft die Wissenschaftskommunikation jedenfalls nach vollkommen anderen Regeln (vgl. Krefeld 2017c), die hier nicht im Einzelnen ausbuchstabiert werden müssen. Es reicht im Hinblick auf die Lehre auf die vollkommen veränderte Realität der Publikation hinzuweisen. Die traditionelle Kommunikation von Forschungsergebnissen lässt sich wie folgt schematisieren:
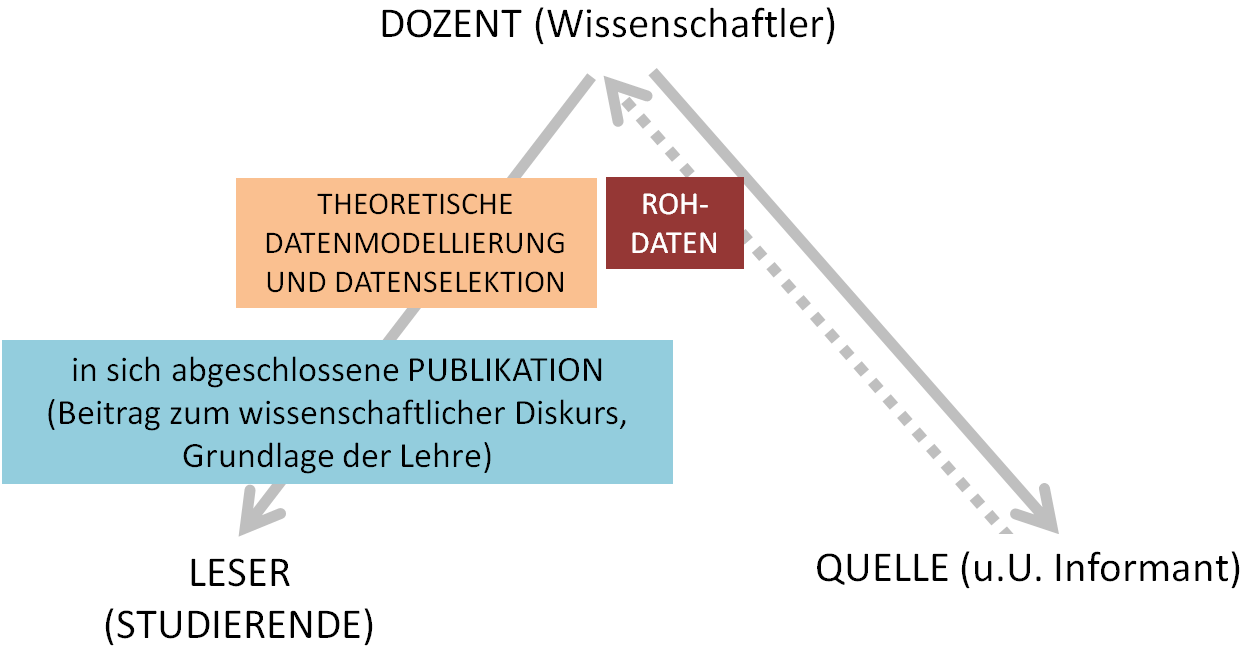
Forschungskommunikation auf der Grundlage gedruckter Texte
Publikationen, die für den Druck konzipiert werden, sind gewissermaßen dingliche, objekthafte Endprodukte eines Forschungsprozesses. Ihre (kommerzielle) Herstellung und Distribution liegt in der Hand Dritter, der Verlage, und ihre Form entspricht spezifischen Gattungen, wie zum Beispiel einem Wörterbuch, einer Abhandlung, einer Anthologie, einem Atlas oder auch einem Lehrbuch.
Unter den Bedingungen des Web lässt sich der wissenschaftliche Diskurs im Rahmen von freier Zugänglichkeit (open access) und offenen Quellcodes (open source) etwa wie folgt schematisieren:
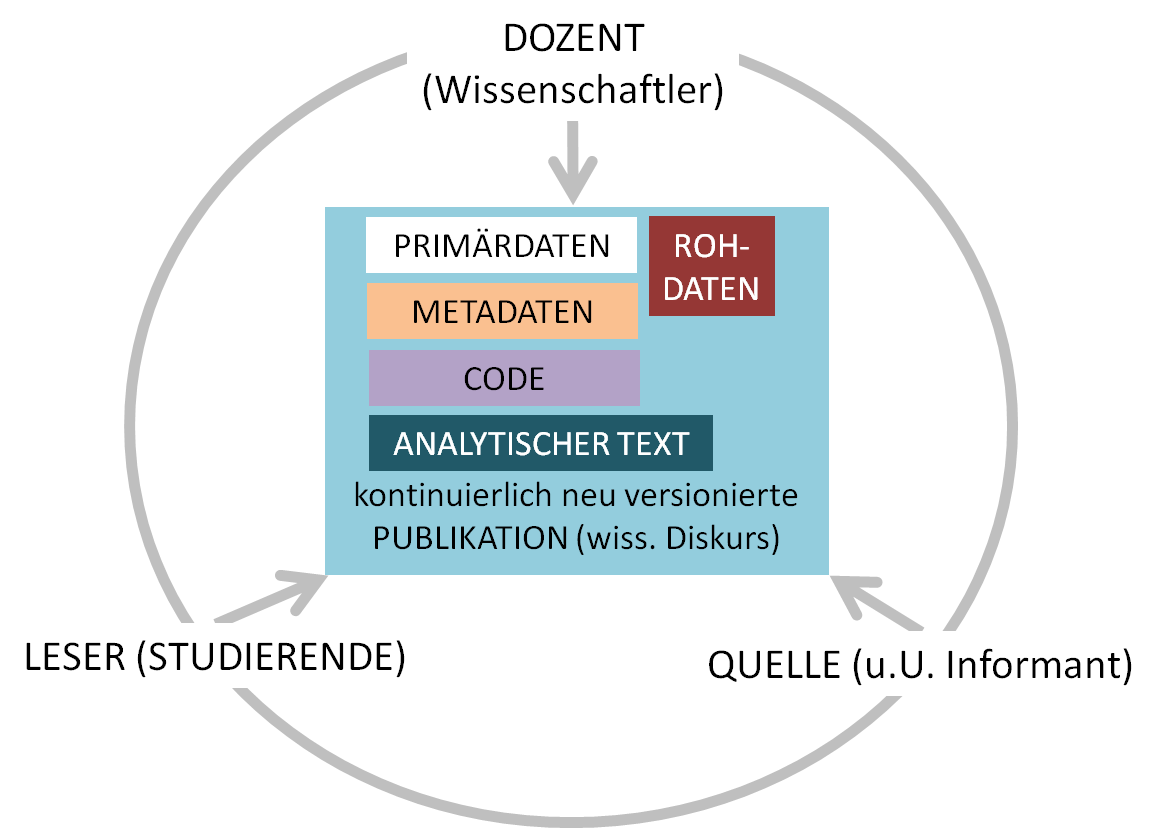
Webbasierte Forschungskommunikation
Unter diesen Bedingungen erweitert sich zunächst der Bereich des Publizierten, da außer dem analytischen Fließtext auch die Primär- und Metadaten also solche sowie speziell entwickelter Code veröffentlicht werden. Sodann sind die Gattungsgrenzen aufgehoben, allerdings ohne die sinnvolle Funktionalität der traditionellen Gattungen zu entwerten. So sind im Fall des DFG-Projekts VerbaAlpina zwar ein Wörterbuch (Lexicon Alpinum), eine Atlasdarstellung (Interaktive Karte) und analytischer wissenschaftlicher Text (Methodologie) als eigenständige Module angelegt; untereinander sind sie jedoch so verlinkt, dass von einer Funktion stets in eine andere gewechselt werden kann (♦).
Die teils beharrlichen Vorbehalte gegenüber Publikationen im Web werden durch ganz unterschiedliche Gründe getragen, die allesamt nicht substantiell, sondern akzidentiell zu sehen sind. Am schwersten wiegt das Argument der prekären Nachhaltigkeit (vgl. dazu Krefeld & Lücke 2017), das durch ein Paket konzertierter Maßnahmen bewältigt werden kann:
- die Schaffung textstabiler und insofern dauerhaft zitierfähiger Versionen;
- die Auszeichnung mit Metadaten, die sowohl durch Suchmaschinen wie in Bibliothekskatalogen leicht auffindbar sind;
- die Ablage auf institutionell betriebenen Servern mit zuverlässiger Aussicht auf langfristige Verfügbarkeit (große Rechenzentren).
Ein Format, das diesen Ansprüchen genügen kann, wurde an der LMU in Zusammenarbeit mit der UB mittlerweile entwickelt. Es ist so angelegt, dass die jeweilige textstabile Version in der URL angezeigt wird und weiterhin durch die Nummer eines Abschnitts, auf den man sich bezieht, oder den man wörtlich zitiert, spezifiziert werden kann. Hier die empfohlene Zitierweise eines Artikels in der 7. Version (...v=7):
- Thomas Krefeld & Stephan Lücke (2017): Nachhaltigkeit – aus der Sicht virtueller Forschungsumgebungen. Korpus im Text. Version 7 (10.03.2017, 12:27). url: http://www.kit.gwi.uni-muenchen.de/?p=5773&v=7
sowie die URL seines ersten Abschnitts (...p:1):
Der soeben zitierte Text wurde in unserer Publikationsplattform Korpus im Text (KiT) veröffentlicht, die nicht zuletzt für die Lehre relevant ist. Ein Lehrbuch, in das vielfältige Forschungserfahrungen eingeflossen sind, sowie mehrere wissenschaftliche Arbeiten und Artikel stehen hier bereits zur Verfügung; ein weiteres Lehrbuch, einige Dissertationen und andere, auch umfangreiche wissenschaftliche Vorhaben werden vorbereitet (♦). Darüberhinaus bietet auch DH-Lehre spezifische Publikationsmöglichkeiten mit engem Bezug zur Lehre, nämlich für exzellente Abschlussarbeiten einerseits und für ausformulierte Vorlesungen andererseits.
2. Ein neues Kooperationsprinzip
Im Hinblick auf die Lehre ist jedoch vor allem von Bedeutung, dass sich mit der webbasierten Forschungs- und Wissenschaftskommunikation neue Horizonte der akademischen Zusammenarbeit von lehrenden Forschern und Lernenden auftun. Ganz selbstverständlich ergeben sich Kooperationen zwischen Dozenten, bzw. Forschungsprojekten und Studierenden einerseits und zwischen Studierenden untereinander andererseits. Dazu drei Beispiele.
Beispiel (1): Kooperation zwischen Projekten und Studierenden
Im Rahmen einer Master-Arbeit wurden von Myriam Abenthum lexikologische Kommentare verfasst, die nach Revision durch die Projektleiter in das Wörterbuchmodul des Projekts VerbaAlpina übernommen wurden.
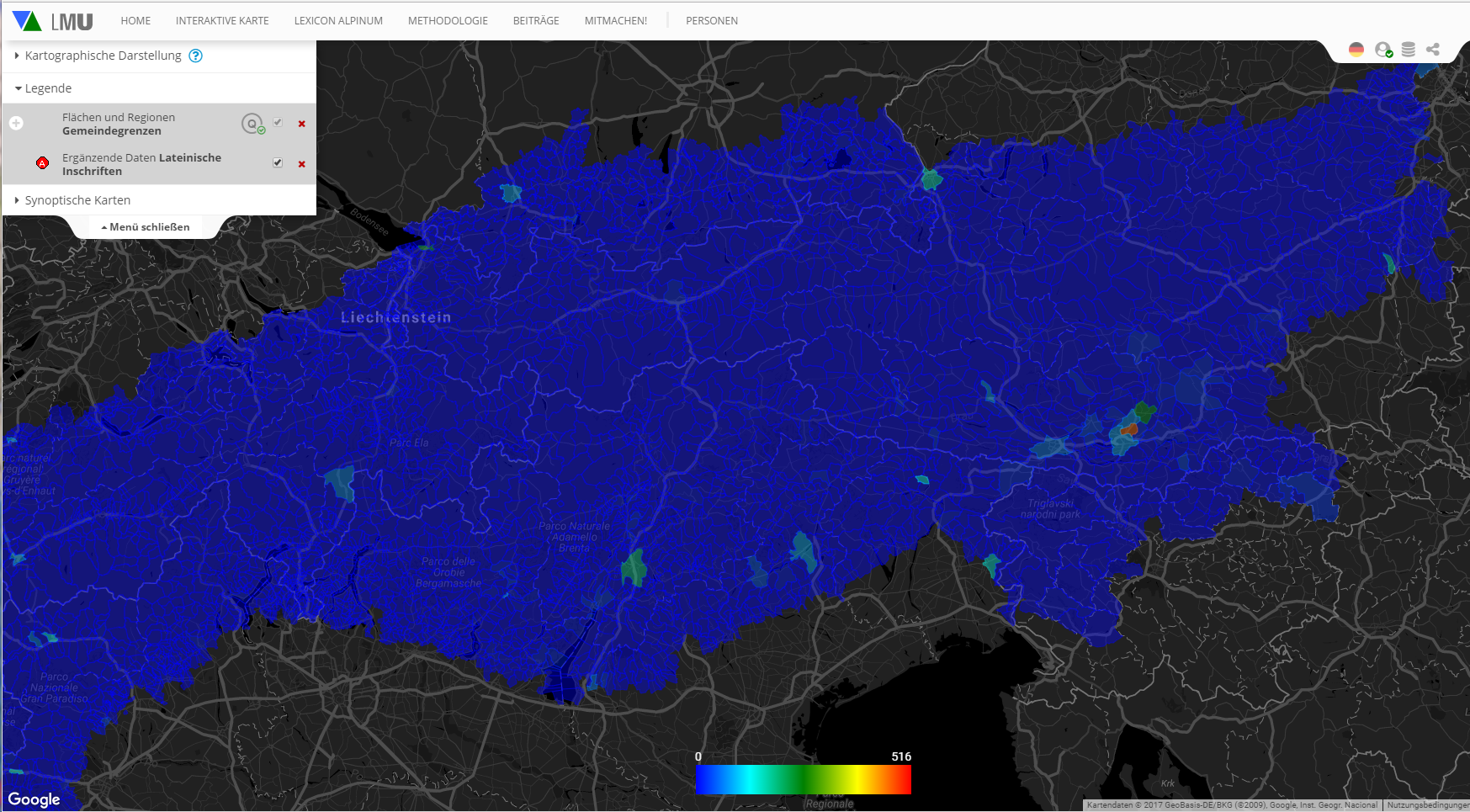
Beispiel (2): Kooperation zwischen Doktoranden und BA-Studierenden zur Toolentwicklung
Etwa ein Drittel der sprachwissenschaftlichen DoktorandInnen unserer Graduiertenschule nimmt die Lehre der ITG in Anspruch und stützt ihre Dissertation auf relationale Datenbanken (♦); die Themenbereiche sind sehr unterschiedlich und die BetreuerInnen weit gestreut. Darunter ist ein ebenso innovatives wie methodisch richtungsweisendes Projekt von Sebastian Lasch zur Erfassung und Analyse von Graffiti im Stadtgebiet Roms. Bei der kartographischen Visualisierung der ca. 3000 Graffiti werden Instrumente zur Darstellung quantitaiver Verhältnisse zum Einsatz kommen, die für VerbaAlpina entwickelt wurden (insbesondere eine heatmap). Aber eine nicht geringe Schwierigkeit bei der Datenerfassung und -verarbeitung besteht darin, die unterschiedlichen Information so aufzunehmen, dass jedes Zeichen einzeln mit spezifischen Metadaten und drüberhinaus auch im Kontext der Gesamtäußerungen und ihrer Abfolge wiedergeben werden kann. Das folgende Photo zeigt:
{kind=link}
- von einer Hand den grünen Text Stalin c'è ('Stalin ist da') mit zwei grünen Hammer & Sichel-Symbolen;
- von einer zweiten Hand zwei schwarze Zusätze, die den grünen Text negieren: Stalin non c'è più ('Stalin ist nicht mehr da');
- eventuell von einer weiteren Hand (?) die Übermalung der Hammer & Sichel-Symbole durch faschistische Kreis & Kreuz-Symbole;
- die Übermalung von non und più mit dem offenkundigen Ziel sie unkenntlich zu machen und die Neagtion aufzuheben;
- dem Anschein nach zuletzt angebrachte weisse Übermalungen, ein weißes fachistisches Symbol über dem schwarz übermalten , ursprünglich grünen sowie eine unleserliche weiße Schrift über dem Namen Stalin.

Eine Wand mit Graffiti in Rom (Photo Sebastian Lasch)
Eine direkte Aufnahme dieser Daten in das relationale Modell, mit dem die ITG ausnahmslos arbeitet erschien möglich, jedoch reichlich umständlich. Just als diese Überlegungen angestellt wurden, tauchte ein Studierender der Informatik an unserem Institut (der Romanistik) auf, Daniel Pollithy, und bekundete sein Interesse, in seiner informatischen BA-Arbeit etwas zu entwicklen, das sich auf sprachliche Daten anwenden ließe. Ich skizzierte ihm das Problem und in Abstimmung mit der ITG und engem Austausch mit dem Doktoranden entstand ein außerordentlich nützliches Tool, das eine direkte Erfassung der Primärdaten und die Zuordnung von Metadaten in beliebige vielen Layern und ausgehend vom Photo selbst gestattet. Einen Eindruck der Bearbeitung (aus der Alpha-Version) gibt der folgende Screenshot:
Erfassung semiotischer Informationen auf Basis einer Photographie (Sebastian Lasch | Daniel Pollithy)
Das Datenschema zeigt, dass bei der Erfassung die syntakische Abfolge (FOLGT) unterschiedlicher Zeichentypen (TOKEN, SYMBOL), die zeitliche Abfolge (ÜBERDECKT), die Assoziation mit semantischen bzw. kognitiven Feldern (AKTIVIERT) sowie diverse semiotische und linguistische Metadaten berücksichtigt werden.
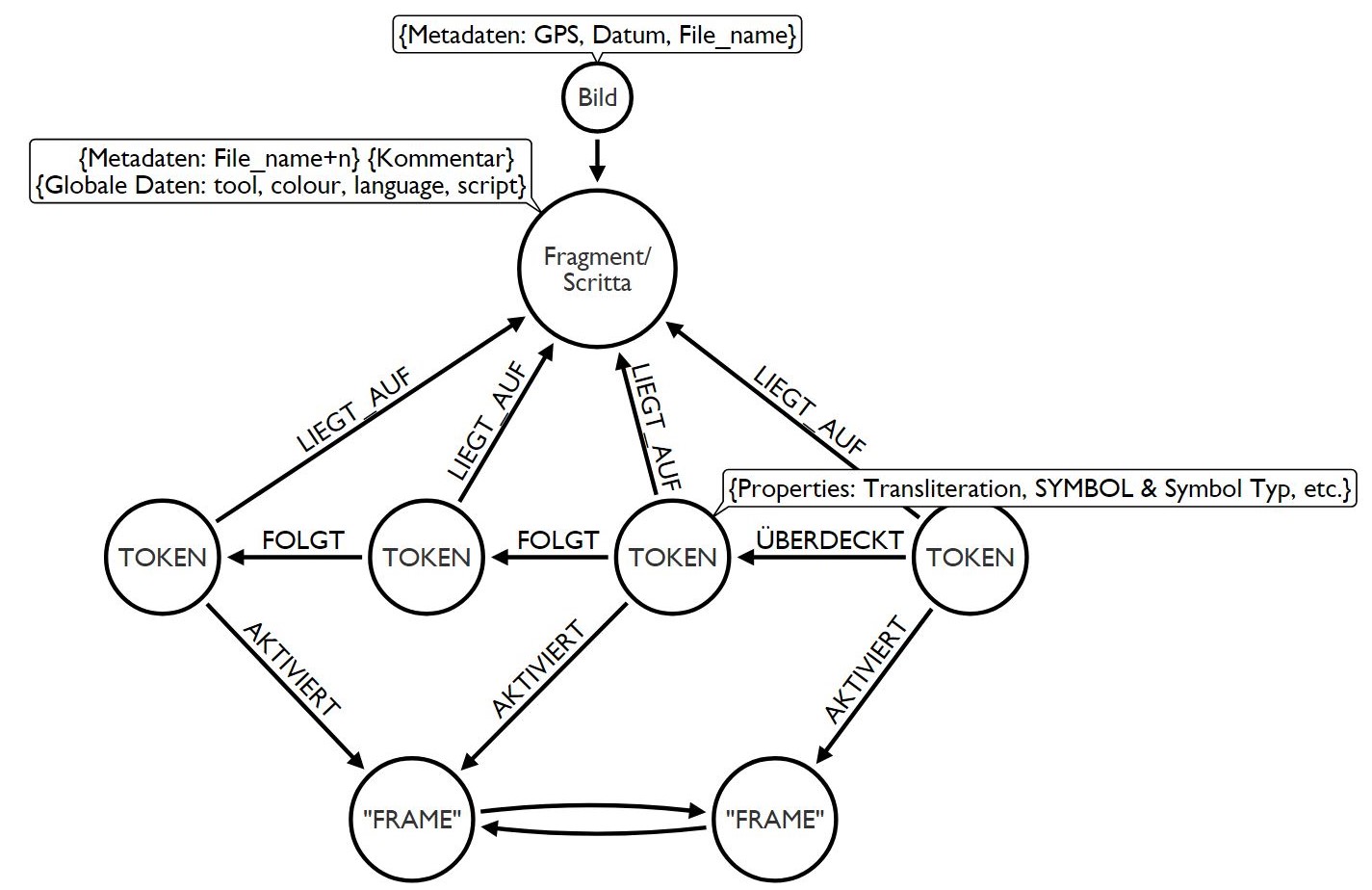
Daten Modell für die Erfassung von Graffit (Sebastian Lasch | Daniel Pollithy)
Eine syntaktische spezifizierte Verknüpfung ('follows') zeigt der folgende Screenshot:
Syntaktische Relation zwischen semiotischen Einheiten (Sebastian Lasch | Daniel Pollithy)
Für das präsentierte Tool wurde zwar ein graph database verwandt (die Community-Edition der Neo4j GraphDB); es gestattet jedoch den Export der erfassten Daten in das übliche relationale Modell (MySQL) der ITG . Nach Fertigstellugn der BA-Arbeit wird es dem DHVLab zur Verfügung gestellt und sich dort sicherlich als sehr nützlich für editorische, epigraphische und andere Projekte erweisen.
Beispiel 3: Kooperation von Forschung Lehre im Bereich der Korpora und Repositorien
Ein letztes Beispiel illustriert eine gleichermaßen strategische wie strukturelle Form der Kooperation unserer Lehr- und Forschungsinfrastruktur. Sie besteht darin, Korpora, die für Dissertationsprojekte konzipiert, erhoben und strukturiert werden, nach Abschluss der Dissertation der Lehre (und natürlich weitere Forschung) zur Verfügung zustellen. Ein prototypisches Beispiel ist das italienische Whatsapp-Korpus, das Katharina Jakob im Rahmen einer Untersuchung über Medienbedingte Variation am Beispiel italienischer WhatsApp-Chats aufgestellt und mit einem soliden Datenbestand gefüllt hat, wie der folgende Screenshot zeigt:
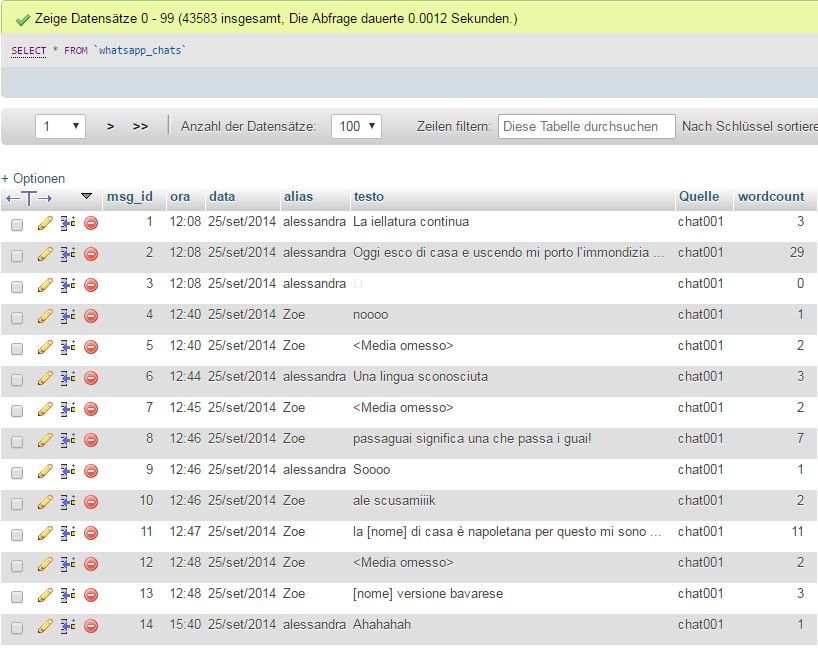
Allgemeine Ansicht der Datensätze im WhatsApp-Korpus von Katharina Jakob (Screenshot)
Diese spezifische Art des aktuellen Sprachgebrauchs zeichnet sich durch etliche, erst ansatzweise analysierte Besonderheiten aus, wie z.B. durch das systematische Fehlen des Aposthrophs nach der Kurzform des definiten Artikels vor vokalisch beginnendem Folgewort: il, la > l anstatt der Standardform l'; das folgende Bild zeigt die Abfrage und den Beginn der Trefferliste.
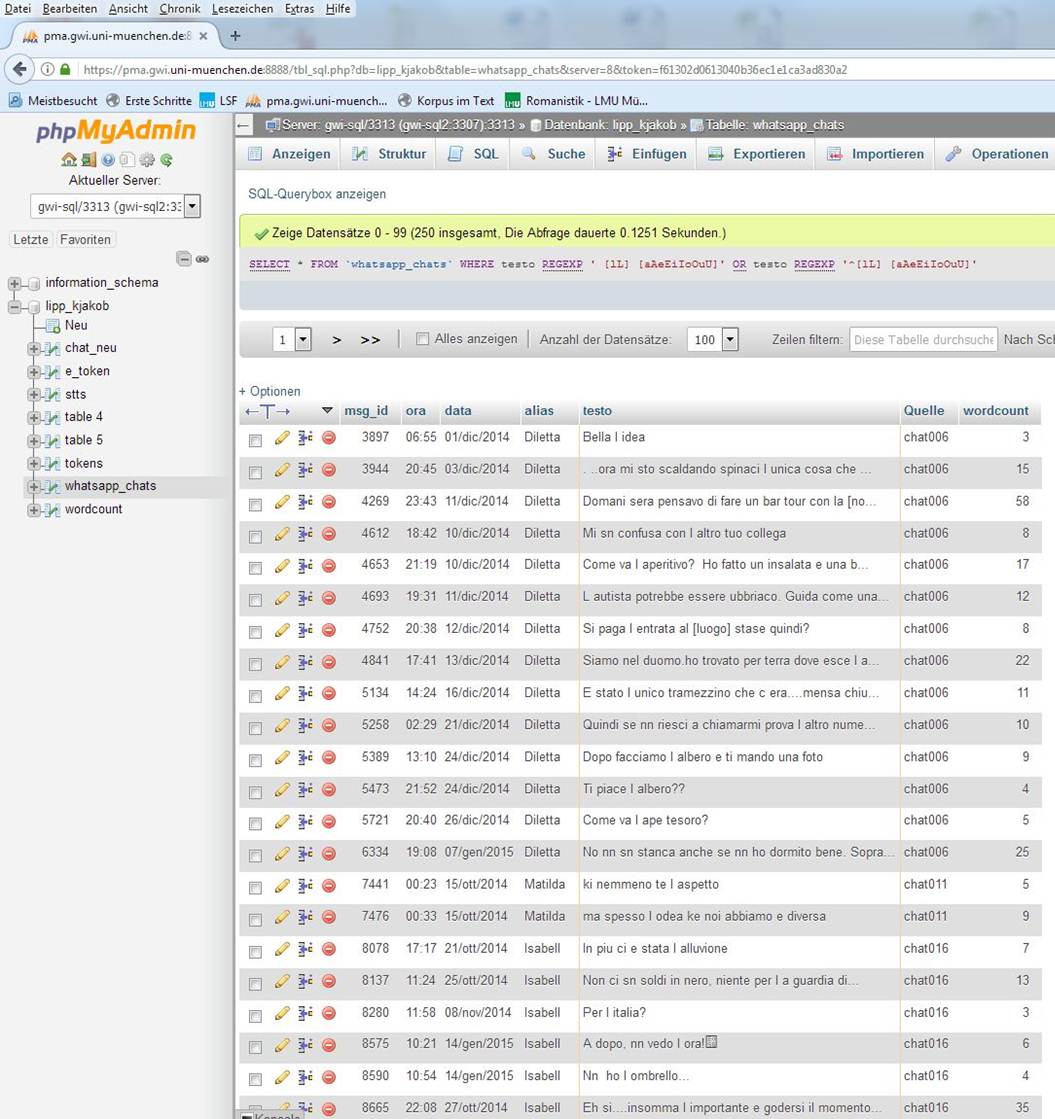
WhatsApp-Korpus - Ausschnitt aus Trefferliste bei Abfrage von fehlendem Apostroph bei bestimmtem Artikel (Katharina Jakob)
Das Korpus dokumentiert einen attraktiven Bereich der sprachwissenschaftlichen Lehre; es wird zweifellos schnell zum Gegenstand anderer studentischen Arbeiten werden, die es dann nicht nur verwenden, sondern gleichzeitig weiter ausbauen und womöglich differenzierter strukturieren sollen.
3. Forschungskommunikation dient der Aufklärung
Digitale Forschungskommunikation dient also, genauer gesagt, der digitalen Aufklärung, dem eigentlichen Unterrichtsziel unseres Studiengangs. Frei nach der berühmten Definition des preußischen Aufklärers Immanuel Kant2 ist digitale Aufklärung der Ausgang des Geisteswissenschaftlers aus seiner selbstverschuldeten digitalen Unorganisiertheit. Unorganisiertheit ist das Unvermögen, sich seiner eigenen Forschungsdaten ohne Abstimmung mit den Daten anderer zu bedienen. Selbstverschuldet ist diese Unorganisiertheit, wenn die Ursache derselben nicht am Mangel der Forschungsdaten, sondern der Bereitschaft liegt, sich seiner eigenen Daten ohne Abstimmung mit den Daten der Kommilitonen und Fachkollegen zu bedienen.