If you can just get your mind together
then come across to me
We'll hold hands an' then we'll watch the sun rise
from the bottom of the sea
But first
Are You Experienced?
(Jimi Hendrix, Are You Experienced, 1967)
1. Hinführung
Das Projekt DAHPN - Datenbank "Althebräische Personennamen" baut mit der Analyse der biblisch-hebräischen Personennamen auf dem Datenbestand des Projekts BHt - Biblia Hebraica transcripta (siehe dazu Riepl 1999 und Riepl 2016) auf und ergänzt diesen um eine Sammlung und Analyse der epigraphisch-hebräischen Personennamen. Beide Projekte nutzen die gleiche Datenbank bhtdb30, erschliessen den Datenbestand aber über zwei verschiedene webbasierte Benutzerschnittstellen, nämlich bht und dahpn. Jede übernimmt dabei ihre jeweils spezifischen Aufgaben. Zugleich ist dahpn mit der Suchfunktion von bht verknüpft und ermöglicht damit für alle biblisch belegten Personennamen die Ausgabe einer Satzkonkordanz sowie von dort aus die Anzeige des gesamten Kontextes.
Webapplikationen, die mit Hilfe von Web- und Datenbanktechnologien Wissen in Datenbanken zugänglich machen und für Wissenschaft und Gesellschaft erschliessen, sind nach ersten Versuchen ungefähr Mitte der 1990er Jahre aus dem heutigen Wissenschaftsbetrieb nicht mehr wegzudenken. Das Projekt BHt war im DFN-geförderten Projekt "MultiMAP/2 - Netzzugang und Netzbetrieb für das muldimediale Datenbanksystem MulitMAP" (siehe Specht/Zirkel 1999) von 1996 bis 1998 Teil dieser Entwicklung, die damals in einer ersten Webapplikation MultiBHT Text- und Analysedaten mehrerer sprachlicher Ebenen präsentierte, sowie Such- und Kommentarfunktionen bereitstellte. Damit war erstmals ein Online-Zugang nicht nur zu den transkribierten Texten, sondern zugleich - auch durch die User kommentierbar - ein Lexikon mit Satzkonkordanz geschaffen. Im Hinblick auf das Projekt VerbaAlpina ist interessant, dass der Ausgangspunkt 1995 eine multimediale Anwendung war, die Informationen in Datenbanken auf Kartenmaterial (daher der Titel MultiMAP) verknüpfen und darstellen sollte, wobei damals die Referenzierung noch nicht über Geodaten, sondern anhand der Bildkoordinaten der Karten erfolgte.
Seit den 1990er Jahren haben sich zum einen die Webtechnologien und zum anderen die damit geschaffenen Webapplikationen schnell, grundlegend und umfassend weiterentwickelt. Umfangreiche Erfahrungen im Umgang mit Webapplikationen sind daher sowohl auf Seiten der Entwickler als auch auf Seiten der Fachwissenschaftler, der Anwender und der wissenschaftlichen Community erforderlich. Mit dem Songtitel "Are you experienced" von Jimi Hendrix, das auf dem gleichnamigen Studioalbum 1967 veröffentlicht wurde, können wir uns in übertragener Weise fragen: Sind wir erfahren genug, um die zur Verfügung stehenden digitalen Mittel optimal und nachhaltig zu nutzen? Sind wir bereit, uns auf die Funktionen- und Perspektivenvielfalt und die damit verbundenen Veränderungen, die die digitale Welt mit sich bringt, vollends einzulassen? Zumal mit dem Einsatz von Webapplikationen ein grundlegender Paradigmenwechsel verbunden ist, der Vertrauen in die Technologie und die Menschen dahinter erfordert. Auch hier lässt sich die Erfahrungswelt von Jimi Hendrix passend übertragen: "We'll hold hands an' then we'll watch the sun rise from the bottom of the sea".
2. Das Projekt DAHPN
2.1. Beteiligte und Projektphasen
DAHPN ist ein DFG-gefördertes Gemeinschaftsprojekt der Julius-Maximilians-Universität Würzburg, der Hochschule für Jüdische Studien Heidelberg und der Ludwig-Maximilians-Universität München. Projektverantwortliche waren Prof. Dr. Hans Rechenmacher, Prof. Dr. Viktor Golinets und Dr. Lic. Theol. Annemarie Frank. Die informatischen Arbeiten wurden durch die IT-Gruppe Geisteswissenschaften an der Ludwig-Maximilians-Universität München durchgeführt.
Eine erste Projektphase widmete sich von 2014 bis 2017 der Analyse aller biblisch-hebräischen Personennamen. Das Projekt erhielt eine erste Verlängerung von 2018 bis 2021, um die epigraphisch-hebräischen Personennamen zu bearbeiten. Eine zweite Verlängerung, die die künstlich-literarischen Namen, primären Orts- und Kollektivnamen, hebräischen Namen von Nicht-Israeliten und nichthebräischen Namen von Israeliten und Nicht-Israeliten behandeln sollte, wurde nicht bewilligt. An die beiden Vorgängerprojekte möchte nun ein 2022 beantragtes Projekt "Datenbankmodul 'Nordwestsemitische Personennamen in Babylonien" (Annemarie Frank) anschließen.
2.2. Voraussetzungen und Workflow
Bei der Transkription und Digitalisierung der biblischen Texte im Projekt BHt wurden sämtliche Eigennamen (Gottesnamen, Personennamen, Kollektivnamen, Ortsnamen) zunächst nicht berücksichtigt. Ihre Eingabe erfolgte in einer Transliteration der Konsonanten in Großbuchstaben. Im weiteren Projektverlauf erhielten die Eigennamen nur eine rudimentäre Analyse nach wenigen Kriterien (u.a. Geschlecht des Namensträgers, Bauform, Morphologie, Syntax, Sprache und Übersetzung). Der in der Datenbank bhtdb30 abgelegte Datenbestand bildete die Grundlage für die erste Projektphase von DAHPN.
Aus der Datenbank bhtdb3.0 wurden sämtliche Daten der Personennamen jeweils alphabetisch nach Anfangsbuchstaben in je einer Datei mit festem 19-zeiligem Schema, teils mit vorbesetzten Werten aus der Datenbank, teils mit Platzhaltern gespeichert. Anhand dieser ASCII-Dateien wurden die Daten durch die Projektteams in Würzburg und Heidelberg korrigiert und ergänzt. Anschließend übernahm die IT-Gruppe Geisteswissenschaften die automatisierte formale Abstimmung der Datensätze, ihren Datenimport und die Weiterverarbeitung in der Datenbank. Daneben entwickelte die IT-Gruppe Geisteswissenschaften die digitale Benutzerschnittstelle dahpn, die in einer ersten Version (Samuel Teuber, Filip Hristov, Axel Wisiorek) in die BHt-Website integriert war, in einer zweiten Version (Tobias und David Englmeier) als eigenständiges System realisiert wurde.
2.3. Datenbestand und Technik
Die Anzahl der Datensätze beträgt 1.831 bei den biblischen, 697 bei den epigraphischen Personennnamen. Die Daten werden in der Datenbank bhtdb30 in mehreren Tabellen abgelegt und nach Versionen benannt, die den Bearbeitungsstand zu einem festgelegten Zeitpunkt wiedergeben. Alle Zitierversionen bleiben zitierbar erhalten. Die Arbeitsversion ist intern nur den Projektmitarbeiterinnen und -mitarbeitern zugänglich.
| Datenbanktabellen (biblisch/epigraphisch) | Version | Anzahl Datensätze |
| en_xxx / en_epi_xxx | Arbeitsversion | 1.831 / 697 |
| en_211 / en_epi_211 | Version 2021 / 1 (Zitierversion) | 1.831 / 697 |
| en_201 / en_epi_201 | Version 2020 / 1 (Zitierversion) | 1.831 / 697 |
| *_converted | Datenbankinterne Tabellen mit aus Betacode konvertierten Unicode-Zeichen |
Nur diejenigen Datensätze, deren Bearbeitung abgeschlossen ist, sind durch ein Flag zur Publikation freigegeben. Daraus erklärt sich eine mögliche Differenz zwischen der o.g. Anzahl der Datensätze und der durch die Export-Funktion insgesamt erhältlichen Anzahl an Datensätzen.
Technische Grundlage des Projekts bilden die relationale Datenbank MySQL und das Contentmanagementsystem WordPress mit zusätzlich entwickelten projektspezifischen Plugins. Alle Module sind in responsivem Design implementiert.
3. Die Benutzerschnittstelle
Man erreicht die Startseite des Projekts unter folgenden URLs https://www.dahpn.gwi.uni-muenchen.de oder https://doi.org/10.24344/bht-dahpn. Im folgenden wird der Stand der Websitegestaltung zum 30. Juni 2022 referiert.
3.1. Startseite und Navigationsleiste
Die Startseite begrüßt die Benutzerinnen und Benutzer mit den wichtigsten Hinweisen und einem Anleitungsvideo.
In der Navigationsleiste oben rechts findet man eine Reihe von Hauptpunkten mit weiteren Unterpunkten bzw. Verweisen, die im folgenden tabellarisch dargestellt werden sollen.
| Hauptpunkt | Unterpunkt/Funktion | Typ/Bemerkung |
| Suche | Verbindung zur Datenbank und Erschließung des Datenbestandes | Template mit JavaScript und AJAX |
| Downloads | Benutzeranleitung | |
| User Guide | ||
| Morphologie, Syntax und Semantik Althebräischer Personennamen (MSSAP) | PDF/Monographie | |
| Lexikon hebräisch onomastisch belegter Verben (LHOV) | PDF/Monographie | |
| Literaturverzeichnis | ||
| Abkürzungen | Allgemeine Abkürzungen | |
| General Abbreviations | ||
| Literatur | ||
| Zitieren | Erläuterung zur Zitierweise | WordPress-Post |
| Veröffentlichungen | Zusammenstellung von Projektveröffentlichungen | WordPress-Post mit externen Links |
| Kontakt | Danksagungen | WordPress-Post |
| Impressum | WordPress-Post | |
| Datenschutzerklärung | WordPress-Post | |
| Aktuelles | Aktuelle Meldungen | WordPress-Post |
| --> BHt | Link auf BHt-Startseite: https://www.bht.gwi.uni-muenchen.de | Link |
| Login | Registierung und Anmeldung | WordPress-Funktion |
Mit Ausnahme des Moduls "Suche", das die eigentliche Kernfunktionalität (Erschießung der Daten) bereitstellt, repräsentieren alle anderen Punkte ganz überwiegend den diskursiven bzw. organisatorischen Teil des Forschungsprojektes.
Die Nutzung steht frei im Internet zur Verfügung. Registrierung und Anmeldung sind nur dann erforderlich, wenn zur wissenschaftlichen Diskussion der einzelnen Personennamenartikel die WordPress-interne Kommentarfunktion genutzt werden soll.
Das ebenfalls WordPress-interne Rollenkonzept ermöglicht über die Zuweisung der Rollen "Administrator", "Redakteur" und "Abonnent" einen nach bestimmten Aufgaben abgestuften Zugang und Umgang mit dem WordPress-Backend und dem Datenbestand.
Dabei hat die Rolle "Administrator" uneingeschränkten Zugriff auf alle Funktionen des WordPress-Backends einschließlich der Daten-, Benutzer- und Rollenverwaltung sowie zum Einsehen, Edieren und Konvertieren aller Datensätze der Arbeitsversion.
Die Rolle "Redakteur" hat keinen Zugang zu Verwaltungsfunktionen des WordPress-Backends, berechtigt aber zum Einsehen, Edieren und Konvertieren aller Datensätze der Arbeitsversion.
Die Rolle "Abonnent" erhalten alle registrierten Personen zur Einsicht und Eingabe von Kommentaren.
Eine Funktion zur Eingabe neuer Datensätze ist über das WordPress-Frontend auf Grund des oben geschilderten Workflows nicht realisiert worden, ist aber dringendes Desiderat und in einer neuen Projektphase vorgesehen.
3.2. Das Datenbankmodul "Suche"
Die Vorstellung des Datenbankmoduls, das den eigentlichen Kern des gesamten Systems darstellt, kann im Folgenden anhand des unangemeldeten Modus geschehen. Es stellt damit die Perspektive des Endbenutzers dar, der mit dem publizierten und versionierten Datenbestand arbeiten kann.
Im angemeldeten Modus und in Verbindung mit den Rollen "Administrator" oder "Redakteur" wird dem Lexikonartikel zusätzlich eine Edier- und Konvertierfunktion zugeschaltet, die Änderungen im Datenbestand ermöglicht und damit der Redaktion bzw. Edition der Lexikonartikel dient. Ein Abgleich bzw. eine Korrektur der Daten kann sich der Suchfunktion bedienen, um bestimmte Datensätze anhand bestimmter Kriterien zu finden und anschliessend zu edieren.
3.2.1. Übersicht
Bei einem Klick auf den Hauptpunkt "Suche" startet das Datenbankmodul mit dem Laden aller Daten und bietet eine tabellarische Übersicht aller Personennamen, zunächst mit nur wenigen ausgewählten Kriterien: Hebräische Kontextform (leer bei epigraphischen Namen), Transliteration, Übersetzung und Einheitsübersetzung.
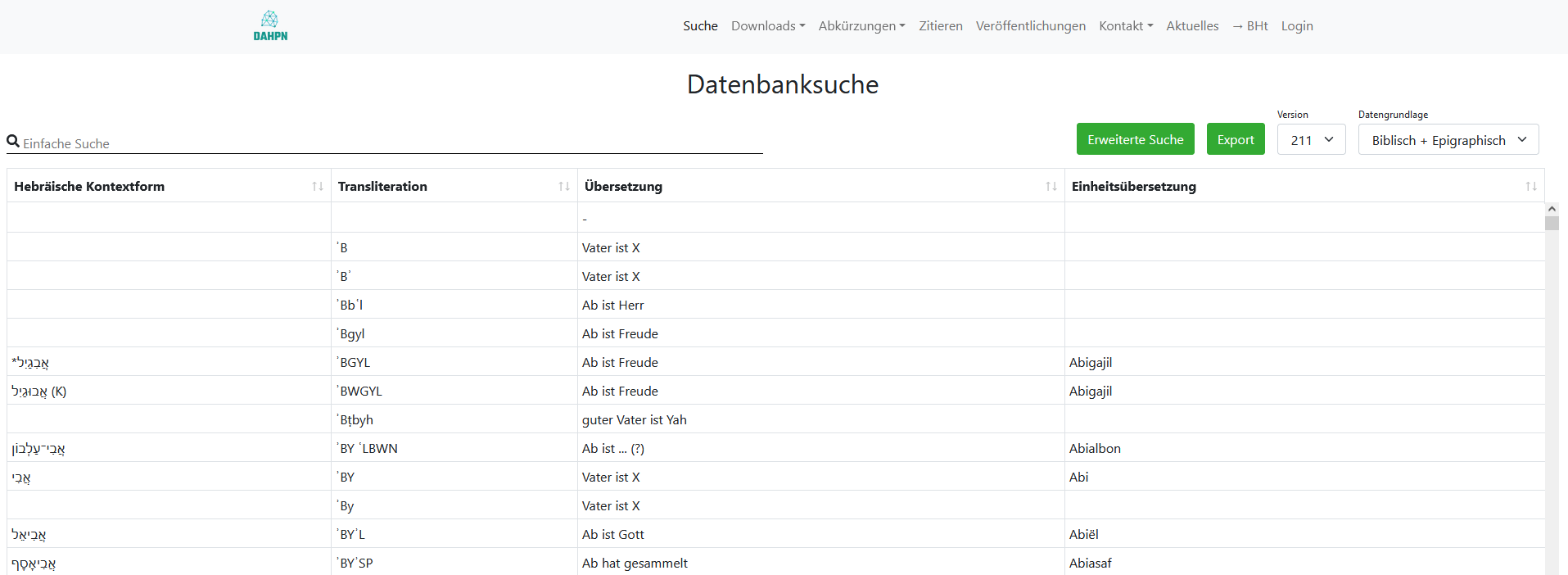
DAHPN: Datenbanksuche
Von hier aus erschließen verschiedene Funktionen (Sortierung und Filterung) den Datenbestand unter verschiedenen Perspektiven. In dieser Hinsicht geht eine digitale Benutzerschnittstelle wie DAHPN weit über die Möglichkeiten eines Printmediums hinaus. In tradtionellen Publikationsformen wie z.B. "Buch" oder "Lexikon" werden Daten überlicherweise nur eher statisch durch alphabetische Anordnung von Stichwörtern (hier Namen) oder systematische Anordnung nach Inhalt oder Analysekriterium in linearer Abfolge und in der Regel mit zusätzlichen Registern, Indizes oder Verzeichnissen meist zu Namen, Sachen und Literatur erschlossen (vgl. Noth 1928/1980 und Rechenmacher 1997). Demgegenüber bietet DAHPN durch beliebige Kombinierbarkeit der Suchkriterien und deren zusätzliche Sortierbarkeit einen dynamischen und flexiblen Zugang zum gesamten Datenbestand. Der Gegenstand steht damit im Mittelpunkt und kann je nach Forschungsinteresse unter verschiedenen Gesichtspunkten betrachtet werden.
3.2.2. Lexikonartikel mit Verlinkung und Diskussion
Zunächst zu den Personennamenartikeln: Mit einem Klick auf eine ausgewählte Zeile der Übersichtstabelle erhält man zunächst die gesamten Einträge von Analyse- und Diskursdaten aus der Datenbank, jeweils tabellarisch nach dem gleichen Schema angeordnet, graphisch ähnlich einem Lexikonartikel gestaltet.
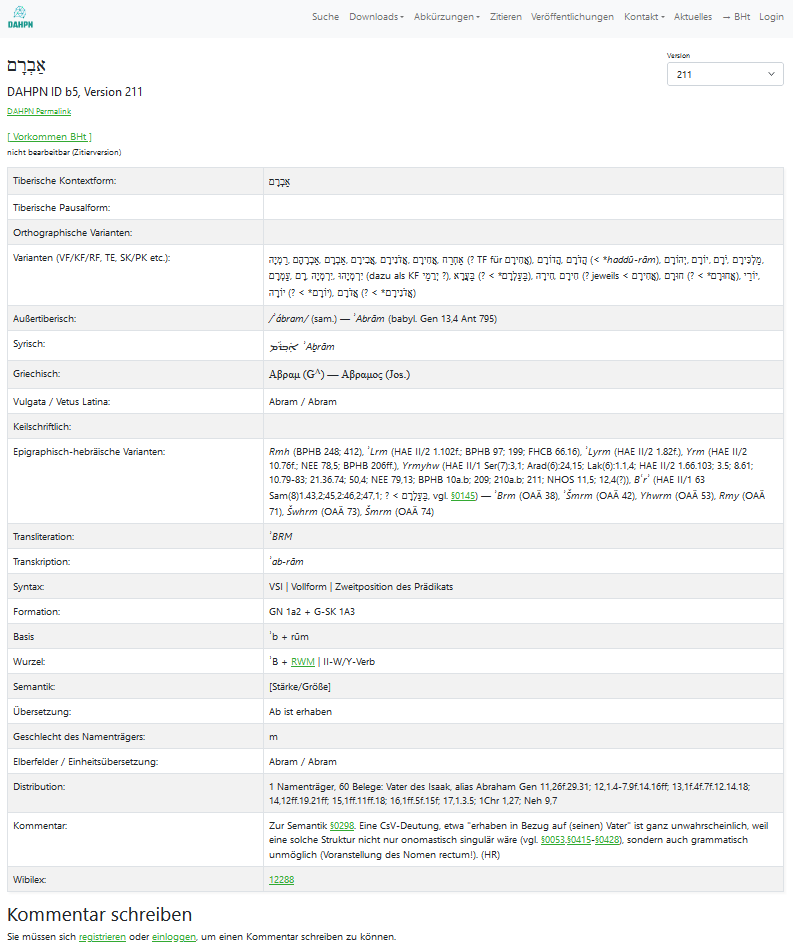
DAHPN: Lexikonartikel
Die Datensätze werden jeweils überschrieben mit der tiberischen Kontextform (eine Reminiszenz an die traditionelle Lexikonstruktur) und identifiziert durch eine DAHPN ID, eine eindeutige Identifikationsnummer, bestehend aus einer Ziffer, die den Buchstaben "b" für biblische Namen und "e" für epigrahische Namen folgt. Zusätzlich wird die Version des Datenbestandes genannt. Die Daten sind enthalten im automatisch generierten DAHPN Permalink:
https://doi.org/10.24344/bht-dahpn?urlappend=name/?id=5&type=bib&db=211
Die Link-Adresse kann kopiert und in andere digitale Publikationen eingefügt werden.
Für jeden Lexikonartikel kann rechts oben die Version ausgewählt werden.
Darüber hinaus wird aus den Lexikonartikeln verlinkt auf die diskursiven Teile von DAHPN: Paragraphenangaben verweisen auf MSSAP, Wurzeleinträge auf LHOV. In einer eigenen Spalte wird außerdem verlinkt auf WiBiLex - Das Bibellexikon der Deutschen Bibelgesellschaft, sofern dort ein Namenseintrag vorhanden ist.
Naheliegend ist hier die Aufnahme weiterer Normdaten wie z.B. der QID von Wikidata, was in einer weiteren Projektphase vorgesehen ist.
Durch die Verknüpfung über die transliterierten Datenwerte der Tokens in DAHPN und BHt sowie durch die Filterung nach Personennamen in BHt können zu jeder Namensform deren Vorkommen in der BHt in Form einer Satzkonkordanz angezeigt werden.
BHt: Suche nach Token und Wortart
Von den einzelnen Belegen aus ist wiederum der gesamte Kontext in BHt erreichbar.
Unter jedem Lexikonartikel bietet DAHPN über die Kommentarfunktion von WordPress die Möglichkeit, eine wissenschaftliche Diskussion zu führen. Die Nutzung der Funktion ist angemeldeten Benutzerinnen und Benutzern vorbehalten.
3.2.3. Systematische Ordnung nach Analysekriterien
Zurück zur Übersicht (siehe oben Abb. 1): Neben dem Zugang über die einzelnen Lexikonartikel bietet das Modul "Datenbanksuche" die Möglichkeit, die Daten systematisch nach den verschiedensten Analysekriterien (siehe oben Abb. 2) zu filtern und zu sichten. Dies kann grundsätzlich nach allen Analysekriterien geschehen, die jeweils einzeln, in beliebiger Kombination und Anzahl in den Suchfeldern der erweiterten Suche (siehe unten Abb. 4) spezifiziert werden können.
Die Suche kann zunächst auf eine bestimmte Datengrundlage (Biblisch + Epigraphisch, Biblisch, Epigraphisch) und Version (211 oder 201) eingestellt werden. Ein Export der Daten im CSV-Format ist auf dieser Ebene jederzeit möglich. Der Datenexport erfolgt dabei immer nach den jeweils ausgewählten Kriterien der Datengrundlage, der Version und der zusätzlich unter "Erweiterte Suche" zumindest mit einem Häckchen am Icon "sichtbar" (Auge) ausgewählten Suchfelder.
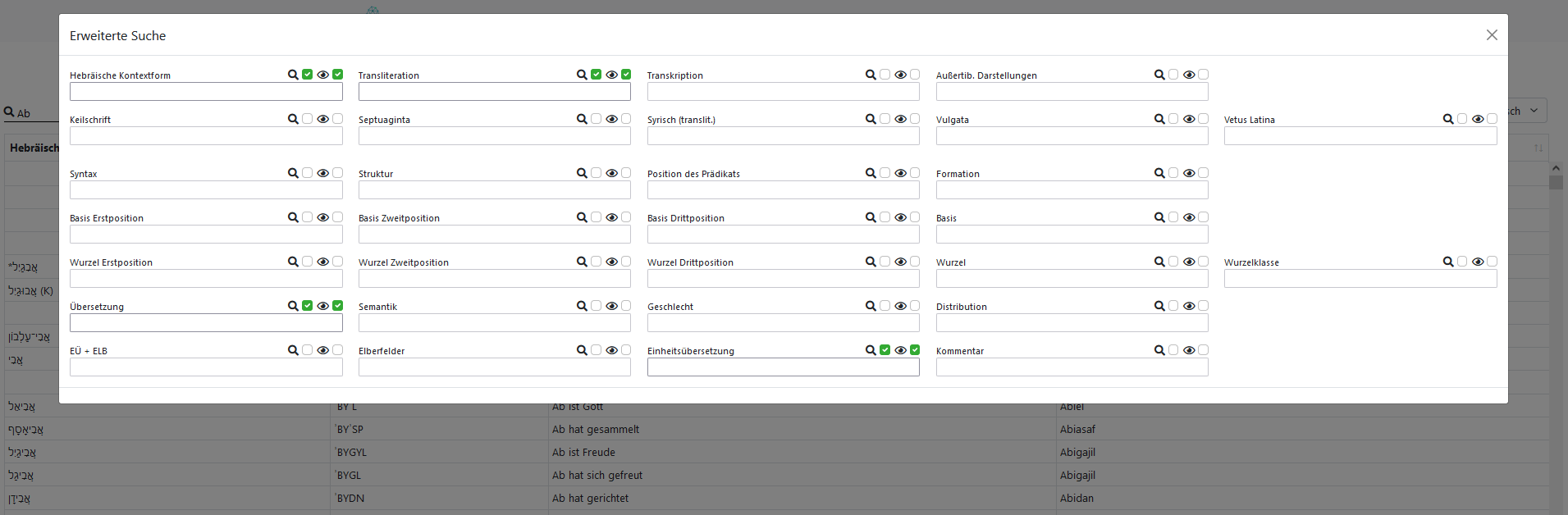
DAHPN: Erweiterte Suche - Suchfelder
Die wählbaren Suchfelder wiederum entsprechen den Spalten in den Datenbanktabellen. Werden alle Suchfelder markiert, wird auch der gesamte Bestand der Datenbank angezeigt und auf Wunsch auch exportiert.
3.2.3.1. Sortierung
Ein wichtiges Instrument zur Datensichtung ist die Sortierfunktion, über die jede Ausgabespalte verfügt, sowohl auf- als auch absteigend. Schon allein eine Sortierung nach z.B. der Spalte "Übersetzung" unmittelbar nach Aufruf des Suchmoduls und ohne jeglichen Filter listet die Daten nach gemeinsamen Werten geordnet auf und verschafft einen Überblick z.B. über Schreibvarianten, ersichtlich z.B. aus der Spalte "Transliteration". In quantitativer Hinsicht vermittelt allein die Ansicht einer sortierten Liste einen oberflächlichen Eindruck von der Anzahl an Vorkommen gleicher Datenwerte. Die Sortierung kann in jeder weiteren einfachen oder erweiterten Suche bei jeder Spalte eingesetzt werden.
Naheliegend ist hier natürlich die Erweiterung um eine Gruppierungsfunktion, die identische Datenwerte zugleich zählt. Dies ist zusammen mit einer entsprechenden graphischen Visualisierung in weiteren Projektphasen vorgesehen.
3.2.3.2. Einfache Suche
Diese Funktion soll einen möglichst unkomplizierten Zugang zum Datenbestand ermöglichen. Dies kann z.B. durch Angabe eines Namens oder nur eines Bestandteils eines Namens geschehen. Es handelt sich hier um eine Volltextrecherche, die alle Datenbankfelder durchsucht.
3.2.3.3. Erweiterte Suche
Diese Funktion (siehe oben Abb. 4) bietet im Unterschied zur teils komprimierten Ansicht der Daten in den Lexikonartikeln (siehe oben Abb. 2) den detaillierten und unmittelbaren Zugang zu allen Daten in der Datenbank mit drei Ausnahmen: Auf die explizite Anwahl der Pausalform, der orthographischen Varianten und des Wibilex-Eintrages wurde verzichtet. Diese sind nur in den Lexikonartikeln einsehbar.
Jedes der insgesamt 30 Suchfelder ist mit zwei Schaltern ausgestattet, die durch ein Lupen- bzw. Augen-Icon repräsentiert werden und durch das Setzen eines Häckchen die Suche in der Spalte oder die Anzeige der Spalte in der Ergebnisansicht aktiviert. Nach einem Klick in das Suchfeld werden sämtliche Werte der Spalte in einem Dropdownmenu zur Auswahl angeboten. Ein Teil der Suchfelder erlaubt die Verwendung von regulären Ausdrücken. Die Suche verknüpft mehrere Suchfelder untereinander durch den Operator UND, mehrere Werte eines Feldes mit ODER. Details zur Suchfunktion, Beispiele und eine Beschreibung der einzelnen Datenbankfelder (Zeilen) enthält die Benutzeranleitung.
30 beliebig kombinierbare Suchfelder ermöglichen eine Vielfalt an Perspektiven auf die Gesamtheit der Daten, die damit im Mittelpunkt stehen und von vielen Disziplinen und unter vielen Gesichtspunkten gesichtet, verglichen und ausgewertet, aber auch diskutiert und weiter ergänzt werden können. Wie bereits oben erwähnt, lassen sich alle Spalten der Ergebnisansicht einzelnen (nicht kombiniert in einer bestimmten Reihenfolge von Spalten) sortieren.
Die Suchfelder erschließen folgende Daten:
- objektsprachliche Realisierungen hebräischer (tiberisch-masoretisch und außertiberisch), griechischer, lateinischer (Vulgata und Vetus Latina), syrischer und keilschriftlicher Belege, ferner die Wiedergabe der Namen im Deutschen (Einheitsübersetzung und Elberfelder, auch kombiniert);
- objektsprachliche Transliteration (biblisch hebräisch und epigraphisch-hebräische Varianten) und morphologische Transkription (hebräisch, außertiberisch, syrisch, keilschriftlich);
- metasprachliche Transkriptionen der grammatischen und semantischen Analyse: Syntax (Wortverbindungsart, Satzart), Struktur, Position des Prädikats, Formation (Wortart und Bauform der Bestandteile), hebräische Basis und gemeinsemitische Wurzel (jeweils mit/ohne Position), Wurzelklasse, Semantik;
- Übersetzung der analysierten Namensform ins Deutsche: Wiedergabe der Namensbedeutung;
- Metadaten: Geschlecht des Namensträgers, Distribution nach Anzahl der Belege und Namenträger (mit identifizierender Beschreibung bzw. genealogischer Zuordung), Quellenangaben;
- diskursive Daten: Kommentar.
3.3. Funktionen- und Perspektivenvielfalt
Die bisher beschriebene Vielfalt an Funktionen und ihrer Anwendungsmöglichkeiten läßt DAHPN als eine Forschungsumgebung erscheinen, die die vielfältigen Prozesse der Forschung und Rezeption integriert. Die Webschnittstelle dient dabei zur Erfassung, Analyse und Auswertung der Daten, zu Redaktion und Edition genauso wie zu Publikation und wissenschaftlicher Diskussion. Sie verlangt einerseits vom Projektteam umfangreiche Erfahrungen auf dem Gebiet der Digital Humanities. Sie öffnet andererseits Benutzerinnen und Benutzern, die sich nicht vor dem Umgang mit digitalen interaktiven wie automatisierten Schnittstellen scheuen, eine neue Erfahrungswelt.
Weit über den primären Interessentenkreis der Hebraistik, Onomastik und Alttestamentlichen Theologie hinaus können hier Disziplinen wie z.B. Semitistik, Altorientalisik, Gräzistik, Latinistik, Neutestamentliche Theologie und Linguistik, auch kultur- und religionsgeschichtliche Disziplinen und sicherlich noch viele mehr mit ihren jeweiligen Methoden und ihrem je eigenen Forschungsinteresse anknüpfen. Natürlich wirkt DAHPN auch in das gesellschaftliche Leben hinein, indem sich z.B. interessierte Laien über Personennamen erkundigen oder sich bei einer bevorstehenden Namensgebung individuell inspirieren lassen können. Möglicherweise kommen auch Filmemacher eines Tages auf die Idee, sich Anregungen für die Namensgebung von Akteuren in Fantasy- oder Science-Fiction-Filmen zu holen. Die Benutzerschnittstelle DAHPN steht allen für jegliches Explorieren und Experimentieren offen.
4. Ausblick
4.1. Vorteile des Digitalen
DAHPN ist digital: Die Daten werden digital gespeichert, sind damit jederzeit änderbar und sowohl quantitativ durch Hinzufügen neuer Datensätze als auch qualitativ durch Modifizierung des Datenmodells erweiterbar. Neue Projektphasen können sich anschließen. Datenbank und Benutzerschnittstelle ermöglichen kollaboratives und interdisziplinäres Arbeiten im Team.
DAHPN ist online: Die mit Webtechnologien realisierte Benutzerschnittstelle ist einer weltweiten Community, unabhängig von Raum und Zeit zugänglich. Der rasche Fortschritt der Webtechnologie und der Techniktransfer zwischen den DH-Projekten an der IT-Gruppe Geisteswissenschaften erleichtern die Entwicklung von Benutzerschnittstellen und schaffen zugleich Raum für neue Anwendungsszenarien.
DAHPN ist vernetzt: Die Vernetzung umfaßt den Datenbestand selbst, der sowohl mit projektinternen als auch mit projektexternen Online-Ressourcen verknüpft ist. Sodann vernetzt die Webschnittstelle Forscherinnen und Forscher zu einer Community, indem sie die wissenschaftliche Diskussion direkt am Gegenstand ermöglicht. Schließlich vernetzen APIs Maschinen miteinander und ermöglichen den Transfer und Austausch von Daten.
DAHPN ist nachhaltig: Der Datenbestand ist online dauerhaft verfügbar, zitierbar und interdisziplinär nachnutzbar.
4.2. Quantitative Auswertung und Visualisierung
Da der gesamte Datenbestand strukturiert abgelegt ist, ist grundsätzlich auch eine quantitative Auswertung auch mit statistischen Methoden und die Visualisierung der Ergebnisse mit informatischen Methoden möglich. Als Beispiel sei hier auf ein studentisches Projekt in der Medieninformatik der LMU verwiesen, das die Distribution von Wortverbindungen in der BHt visualisiert.
BHt: D3 Visualisierung
Ähnlich ließen sich bei DAHPN z.B. die Distribution von Satzarten, Formationen, Bauformen, semantischen Klassen usw. visualisieren. Dies ist in weiteren Projektphasen vorgesehen. Hier mögen vier Beispielabfragen genügen. Die Ergebnisse kommen direkt aus der Projektdatenbank bhtdb30 und werden hier als Tabelle dargestellt.
Verteilung der Formationen/Bauformen:

Verteilung der Satzarten/Syntax:
Verteilung der semantischen Klassen:
Gibt es typische Formationen von Wortarten und Bauformen, die bestimmte semantische Klassen hervorbringen?
4.3. Nachhaltigkeit
Der Umgang mit den im Projekt erhobenen Forschungsdaten berücksichtigt in allen Punkten die FAIR-Prinzipien des Forschungsdatenmanagements. Die Daten sind versioniert (20/1 und 21/1) und über die die digitale Benutzerschnittstelle auffindbar. Sie sind allerdings noch nicht in das Forschungsdatenrepositorium der Universitätsbibliothek der LMU importiert worden, da u.a. die Granularität der Datenerschließung noch definiert werden muss. Wünschenswert wäre, wenn das Auffinden auf der Ebene der einzelnen Datensätze erfolgen könnte. Interoperabilität und interdisziplinäre Wiederverwendung sind aufgrund der Datenstrukturen gegeben, spezifische APIs für den automatisierten Datentransfer sind noch nicht entwickelt.
Ein Problem in Zusammenhang mit der Nachhaltigkeit ist aktuell leider immer noch offen: Die langfristige Verfügbarkeit sog. "lebender Systeme", zu denen auch die digitale Benutzerschnittstelle des Projekts DAHPN gehört. Code oder Codeteile im Rahmen von Projekten entwickelter Systeme können zwar mittlerweile ebenfalls über Forschungsdatenrepositorien oder andere Repositorien wie z.B. Gitlab dauerhaft erhalten und damit jederzeit reaktiviert werden. Was bei einer Abschaltung eines "lebenden Systems" aber verloren geht, ist der unmittelbare Zugang zu den Daten und damit verbunden, die zahlreichen Verknüpfungen, die sich von der Schnittstelle aus mit anderen Systemen bzw. Projekten ergeben haben.
Die dauerhafte und langfristige Erhaltung "lebender Systeme" wird wohl noch eine geraume Zeit eine Herausforderung bleiben. Aus bisherigen Erfahrungen an der IT-Gruppe Geisteswissenschaften können "lebende Systeme" mit transparentem Programmcode, offener Software und breiter Entwicklercommunity durchaus einen Zeitraum von mindestens 15 bis 20 Jahren bestehen (einschliesslich Softwareupdates und Portierungen). In diesem Zusammenhang ergibt sich grundlegend die Frage nach "Langfristigkeit" in der Wissenschaft: Wie lange hebt man Wissen und wissenschaftliche Methoden auf? In welchen Zeitzyklen wird Wissen wieder aufs Neue entdeckt? Von welchen Medien und Infrastrukturen wird die Wissensaufbewahrung bestimmt? Dies alles ist aber hier nicht mehr Gegenstand der Betrachtung.
Um den eingangs erwähnten Song von Jimi Hendrix wieder aufzugreifen: Geisteswissenschaftler und Informatiker mögen sich also an den Händen fassen und gemeinsam in die digitale Welt voranschreiten. "Not necessarily stoned, but beautiful" heißt es am Ende des Songs. Erfahrungen der besonderen Art dürften zu erwarten sein.
Bibliographie
- Noth 1928/1980 = Noth, Martin (1928/1980): Die israelitischen Personennamen im Rahmen der gemeinsemitischen Namengebung, Hildesheim, New York, Georg Olms Verlag [2. Reprographischer Nachdruck der Ausgabe Stuttgart 1928].
- Rechenmacher 1997 = Rechenmacher, Hans (1997): Personennamen als theologische Aussagen. Die syntaktischen und semantischen Strukturen der satzhaften theophoren Personennamen in der hebräischen Bibel, vol. 50, St. Ottilien, EOS Verlag.
- Riepl 1999 = Riepl, Christian (1999): Wie wird Literatur berechenbar? Ein Modell zur rechnergestützten Analyse althebräischer Texte., in: Deubel, Volker / Eibl, Karl / Jannidis, Fotis (Hrsgg.), Jahrbuch für Computerphilologie, vol. 1, Paderborn, 107-134 [Internetveröffentlichung: Zeitschrift für Computerphilologie 1 (1997), Hg. v. Volker Deubel, Karl Eibl, Fotis Jannidis, München 1997.] (Link).
- Riepl 2016 = Riepl, Christian (2016): Biblia Hebraica transcripta - Das digitale Erbe, in: Rechenmacher, Hans (Hrsg.), In Memoriam Wolfgang Richter, Arbeiten zu Text und Sprache im Alten Testament, vol. 100, St. Ottilien, EOS Verlag, 295-311.
- Specht/Zirkel 1999 = Specht, Günther / Zirkel, Martin (1999): MultiMAP/2: Netzzugang und Netzbetrieb fuer das multimediale Datenbanksystem MultiMAP, vol. TUM-I9920, München, Technische Universtität München [Technical Report] (Link).