1. Einleitung
Noch bis vor wenigen Jahren waren Wörterbücher und Enzyklopädien Paradebeispiele für zwar dekorative, jedoch umständlich zu handhabende Nachschlagewerke in privaten Bücherregalen oder Bibliotheken – man denke etwa an die 30-bändige Brockhaus-Enzyklopädie (Brockhaus 2006), das Deutsche Wörterbuch mit 17 Bänden (DWB 1854-1971) oder das ebenfalls 17 Bände umfassende Schweizerische Idiotikon (SchweizId. 1881-lfd.). Gleichzeitig wurde gerade in Wörterbüchern selbst versucht, möglichst verdichtet und platzsparend zu schreiben, was zu unübersichtlichen Artikeln voller Kürzel führt. Dabei sind gerade Wörterbücher, aber natürlich auch andere Arten von Lexika, aufgrund ihrer immanenten (und technisch in Hypertext umwandelbaren) Verweisstruktur dafür prädestiniert, digital erstellt und publiziert zu werden. Auch inhaltlich sind insbesondere wissenschaftlich angelegte Wörterbücher als kultureller Wissensspeicher eine wichtige Ressource, die möglichst vielen Menschen frei zur Verfügung stehen sollte, was durch eine online-Publikation gewährleistet werden kann. Während neue Wörterbücher gleich von Beginn ihrer Produktionstätigkeit an digitale Methoden von der Datensammlung bis hin zum fertigen Artikel anwenden können, stellt der Umstieg für Langzeitprojekte, von denen es gerade im Bereich der Lexikographie einige gibt, eine größere Herausforderung dar, wie unten noch weiter skizziert wird.
Beim hier vorgestellten „Wörterbuch der bairischen Mundarten in Österreich“ (WBÖ) handelt es sich um ein Langzeitprojekt, dessen Ziel die umfassende Dokumentation und lexikographische Aufarbeitung der bairischen Dialekte (Alt-)Österreichs ist. In seiner über 100-jährigen Geschichte hat es schon zahlreiche Wandlungen durchlaufen (vgl. dazu Geyer 2019 sowie Stöckle 2021), die sich nicht nur auf inhaltliche Aspekte beziehen, sondern – besonders in jüngerer Zeit – technologische Neuerungen umfassen. Neben der Digitalisierung des Materialbestandes (vgl. Bowers/Stöckle 2018) betrifft dies die Artikelschreibung, die Präsentation bzw. Publikation der lexikographischen Inhalte sowie die entsprechenden Tools, die teils speziell dafür entwickelt wurden.
Das Ziel dieses Beitrags besteht darin, die Gesamtkonzeption des WBÖ zu präsentieren und dabei die sich aus den technischen und konzeptionellen Neuerungen ergebenden Möglichkeiten zur internen und externen wissenschaftlichen wie technischen Vernetzung aufzuzeigen. Zuvor sollen jedoch in Kapitel die zum Verständnis notwendigen Hintergrundinformationen zur Geschichte und Konzeption des WBÖ geliefert werden, bevor dann in Kapitel die technische Gesamtkonzeption mit den sich daraus ergebenden Vernetzungsmöglichkeiten präsentiert wird.
2. Das WBÖ – Hintergrund und Konzeption
2.1. Historischer Abriss und Materialgrundlage
Die Initiierung des WBÖ fällt bereits in das Jahr 1910, als der Münchener Indogermanist Ernst Kuhn dem Wiener Germanisten Joseph Seemüller in einem Brief den Vorschlag unterbreitete, ein gemeinsames Dialektwörterbuch des Bairischen zu schaffen. Nach dem Einsetzen von Wörterbuchkommissionen an den Akademien in München und Wien im Jahr 1911 wurden die Beschlüsse beider Akademien genehmigt und entsprechende Wörterbuchkanzleien eingesetzt. Als Gründungstag der Wiener Kanzlei gilt der 12. Februar 1913.1
In den folgenden Jahrzehnten wurde eine umfangreiche Erhebung von Dialektmaterial durchgeführt. Dies geschah mit der Unterstützung von freiwilligen Sammler*innen, die mithilfe von Fragebögen, die von den Mitarbeitern der Kanzleien erstellt und versandt worden waren, den dialektalen Wortschatz der vorwiegend bäuerlichen Bevölkerung erhoben. Der Hauptanteil der Erhebungen erfolgte von 1913 bis 1933 auf Grundlage der 109 „großen Fragebögen“ und der neun „Ergänzungsfragebögen“ zwischen 1927 und 1937. Zusätzlich wurden von 1927 bis 1965 Kundfahrten von geschulten Dialektolog*innen und bis 1990 nachträgliche Fragebucherhebungen durchgeführt. Ergänzt wurde das empirisch erhobene Material durch Exzerpte aus dialektologischer Fachliteratur und weiteren schriftlichen Quellen (u.a. historische Texte). Sämtliche Belege aus den verschiedenen Erhebungsphasen wurden auf Handzetteln notiert (vgl. Abbildung 1), das Ergebnis der gesamten Materialsammlung bildet schließlich der sog. „Hauptkatalog“ mit ca. 3,6 Millionen Belegzetteln.

Belegzettel zu den Lemmata Fabel, Ofengabel, feiern und Fack
Wie Abbildung 1 illustriert, unterscheiden sich die Belegzettel zum Teil hinsichtlich der dargestellten Inhalte, jedoch sind die für die Dialektlexikographie wichtigsten Informationen auf den meisten Zetteln zu finden. Dazu gehören insbesondere Angaben zum Lemma, zur Lautung, zur Bedeutung und zum Belegort. Zusätzlich enthalten viele Belegzettel Beispielsätze, Angaben zum Fragebogen, zum Sammler bzw. zur Sammlerin, zur Etymologie oder zur literarischen Quelle. In manchen Fällen (wie z.B. auf dem Zettel zum Lemma Ofengabel) wurden auch Zeichnungen angefertigt.
Auch wenn diese Struktur des Belegmaterials als typisch für die Dialektlexikographie betrachtet werden kann, stellt die Arbeit mit den Handzetteln doch eine große Herausforderung an die alltägliche Arbeit am Wörterbuch dar. Zum einen hängt die lexikographische Arbeit vom physischen Medium ab, d.h. der Zugang zum Material muss stets gewährleistet sein. Zudem altern die Zettel mit den Jahren, wobei die Qualität abnimmt und die handschriftlichen Notizen verblassen, und es besteht die Möglichkeit, dass Material verloren geht oder mit den Jahren Zerfallsprozessen zum Opfer fällt. Zum anderen – und weitaus gewichtiger – gestaltet sich die Arbeit mit den Belegzetteln oft als sehr umständlich, besonders in Fällen, in denen sehr viele Belegzettel die Grundlage für einen Artikel bilden.2 Dazu kommt noch, dass die Zettel Handschriften von mehreren hundert Sammler*innen enthalten, die zum Teil in Kurrentschrift verfasst und recht schwer zu entziffern sind.
Nachdem die ersten drei WBÖ-Bände, die die Lemmastrecken zu A, B/P und C enthalten und zwischen 1970 und 1983 erschienen, mithilfe der Handzettel erstellt worden waren, wurde bei der Arbeit für den vierten Band (ab dem Buchstaben D/T) daher mit dem Aufbau einer digitalen Belegdatenbank begonnen, auf die im Folgenden näher eingegangen wird.
2.2. Phasen der Digitalisierung
Der ursprüngliche Zweck der Datenbank lag darin, die lexikographische Arbeit zu erleichtern und so das Artikelschreiben zu beschleunigen. Neben einer schnellen Durchsuchbarkeit der Daten bestand ein wesentlicher Aspekt in der Wiedergabe der sehr variantenreichen Lautschrift. Da die Sammler*innen in der Regel keine geschulten Dialektolog*innen waren, wurde die Verschriftlichung der Dialektlautungen teilweise recht uneinheitlich gehandhabt. Als Lautschrift wurde eine frühe Variante der in der germanistischen Dialektologie häufig verwendeten Teuthonista verwendet, die sich durch eine sehr exakte Darstellung von Lautqualitäten (etwa den Öffnungs- oder Schließungsgrad von Vokalen, Lenisierung von Plosiven etc.) und daher einen umfangreichen Gebrauch an Diakritika auszeichnet. Die Wahl fiel auf das Programm TUSTEP3, eine auf die Bearbeitung und Editierung von Texten spezialisierte Software, die alle notwendigen Anforderungen erfüllte und insbesondere in der Lage war, sämtliche diakritische und sonstige Zeichen abzubilden. Die Digitalisierung, d.h. die manuelle Übertragung der Belegzettel-Inhalte in TUSTEP, wurde 1993 begonnen und konnte 2011 abgeschlossen werden.4
Während TUSTEP in den 1990er-Jahren sicherlich eine sehr gute Wahl zur digitalen Verarbeitung der Belegzettel-Inhalte darstellte, wurden in jüngerer Zeit zunehmend Unzulänglichkeiten hinsichtlich moderner Anforderungen deutlich. Zum einen zählt die TUSTEP-Community an Software-Nutzer*innen und -Entwickler*innen vergleichsweise wenige Mitglieder, was somit auch fehlende Entwicklungsleistungen nach sich zog. Zum anderen speichert TUSTEP die Daten in einem wenn auch offenen5, dennoch proprietären und wenig standardisierten Format, das nur mit der TUSTEP-internen Syntax zugänglich ist. Aus diesem Grund wurde der gesamte digitale Hauptkatalog seit dem Jahr 2016 in mehreren iterativen Schritten in das plattformunabhängige Format XML/TEI konvertiert (vgl. Bowers/Stöckle 2018). Dieser Prozess erwies sich als sehr aufwändig, da eine Vielzahl an Korrekturen in mehreren Schritten bei der Konvertierung durchgeführt werden musste. Der Grund dafür waren in erster Linie Vereinfachungen bei der Eingabe der Lautungsbelege in TUSTEP, die mit den internen Codierungsregeln nicht kompatibel waren und manuell nachgebessert werden mussten. Seit 2018 liegt jedoch eine Version aller digitalisierten Daten im XML/TEI-Format vor, die die Inhalte der Belegzettel weitestgehend fehlerfrei darstellt. Abbildung 2 illustriert die verschiedenen Phasen der Handzettel-Digitalisierung. Dabei handelt es sich in allen drei Fällen um den gleichen Beleg zum Lemma feiern.
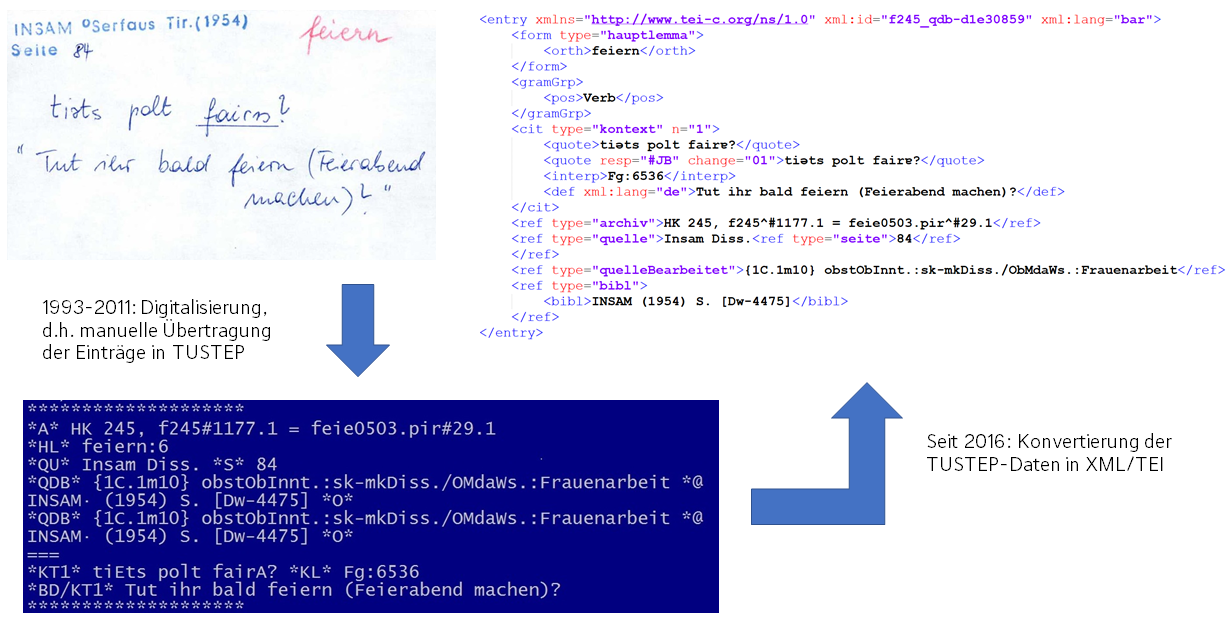
Phasen der Digitalisierung
3. Gesamtkonzept
Das Kerngeschäft des WBÖ-Projekts besteht – trotz der großen Anzahl an technischen Neuerungen in den letzten Jahrzehnten – weiterhin in der lexikographischen Aufbereitung der Belegdaten und der darauf beruhenden Erstellung der Wörterbuchartikel. Seit dem Jahr 2016 wurde die Konzeption grundlegend überarbeitet, wobei neben weiteren Straffungen, inhaltlichen Neuerungen und Vereinheitlichung ein Schwerpunkt auf die Integration neuer texttechnologischer Methoden für die Erstellung, aber auch die Publikation der Artikel gelegt wurde.6 Diese umfassen sowohl die genuin digitale Aufbereitung sowie Strukturierung der Artikel als auch die damit einhergehenden Möglichkeiten der internen Verlinkung von Artikeln, Datenbankeinträgen, geographischen Informationen und weiteren Materialien (wie z.B. Scans von Belegzetteln, Fragebögen etc.). Diese Verknüpfungen bieten für die Online-Publikation entsprechend hypertextuelle Möglichkeiten der Artikel-Rezeption, einen niederschwelligen Zugang zu den Inhalten, aber schließlich auch eine Offenlegung der Textgenese durch den Zugriff auf die den Artikeln zugrundeliegenden Daten (open data / open science). Daneben stehen vielfältige Möglichkeiten der Verlinkung mit externen Inhalten zur Verfügung, etwa über Lemmata (mit anderen Wörterbüchern), über Bedeutungen (z.B. mithilfe der semantischen Taxonomie von Hallig/von Wartburg 1963, die bereits von mehreren Wörterbüchern adaptiert und integriert wurde) oder über geographische Entitäten (mit Daten anderer Projekte aus dem gleichen Untersuchungsgebiet). Die Verlinkung mit externen Inhalten stellt zum aktuellen Zeitpunkt aber noch weitgehend ein Zukunftsprojekt dar, wird aber in der Textgenese bereits angelegt, etwa durch die Verwendung standardisierter Datenmodellierungsformate. Da aber eine tatsächliche Verlinkung über z.B. Identifier oder gemeinsame Schnittstellen erst in den folgenden Jahren erfolgen soll, wird im Folgenden der Schwerpunkt auf der WBÖ-Gesamtkonzeption und den verschiedenen technischen Komponenten liegen, die letztendlich alle im „Lexikalischen Informationssystem Österreich (LIÖ)“ münden.
3.1. Das Recherchetool „Collection Cat“
Grundlage für die Artikelarbeit bietet die WBÖ-Belegdatenbank, die die digitalen Einträge zu den Belegzetteln enthält. Um einen schnellen Zugriff auf die Daten zu gewähren und gleichzeitig notwendige Vorarbeiten wie Sortieren, Filtern, Klassifikation und Zusammenfassung der Belege (z.B. zu verschiedenen Bedeutungen) zu ermöglichen, wurde für das WBÖ-Team das Recherchetool (auch „Collection Cat“7) entwickelt. Es handelt sich dabei um ein webbasiertes System8, dem die Daten aus der BaseX-Datenbank, in der die Belegzettel als XML/TEI vorliegen, zur schnellen Verfügbarmachung von Elasticsearch9 zur Verfügung gestellt werden. Die Kategorisierung selbst erfolgt mithilfe einer djangobasierten10 PostgreSQL-Datenbank.
Der erste Schritt bei der Artikelarbeit besteht stets in einer Suchabfrage, die sämtliche Belege für ein bestimmtes Lemma bzw. den entsprechenden Artikel liefert. In der Collection Cat stehen dafür entsprechende Suchfelder zur Verfügung (vgl. Abbildung 3).
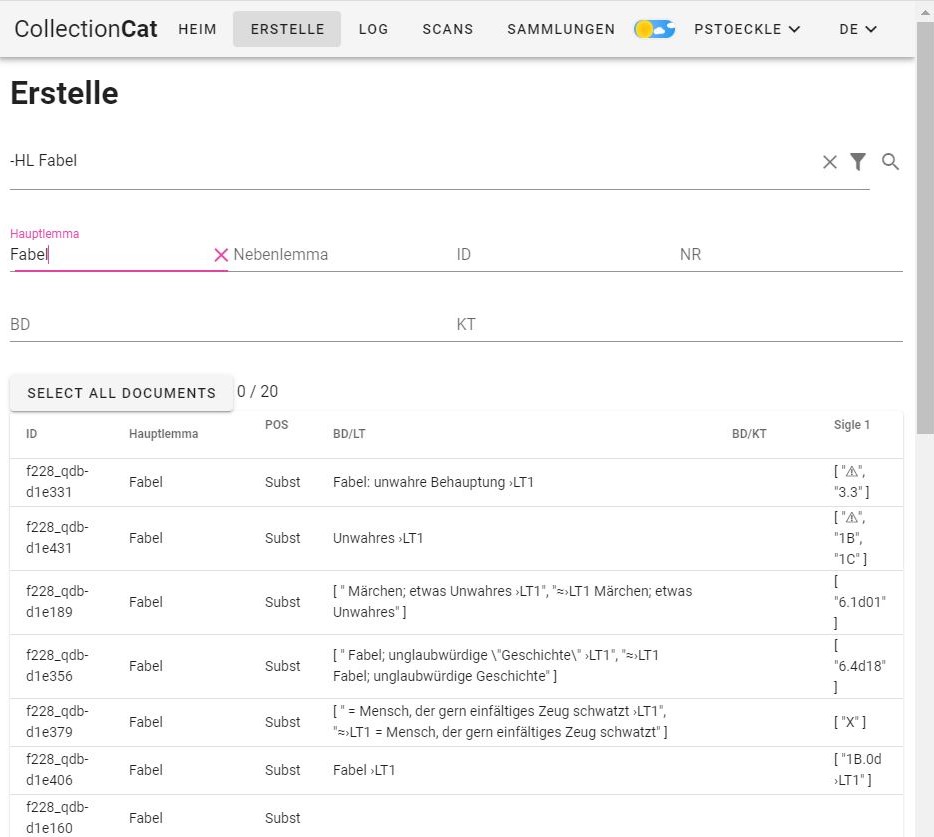
Abfrage zum Lemma Fabel in der Collection Cat
Neben dem „Hauptlemma“ und dem „Nebenlemma“ kann direkt in den Feldern „ID“, „NR“ (Fragebogen-Nummer), „BD“ (Bedeutung)11 und „KT“ (Kontext bzw. Belegsatz) gesucht werden. Zusätzlich bietet das Tool eine Volltextsuche über alle Felder an.
Die Suchabfrage zum Hauptlemma Fabel ergibt eine Trefferzahl von 20 Belegen. Diese können in einem nächsten Schritt ausgewählt und zu einer Sammlung („Collection“) zusammengestellt werden (vgl. Abbildung 4).
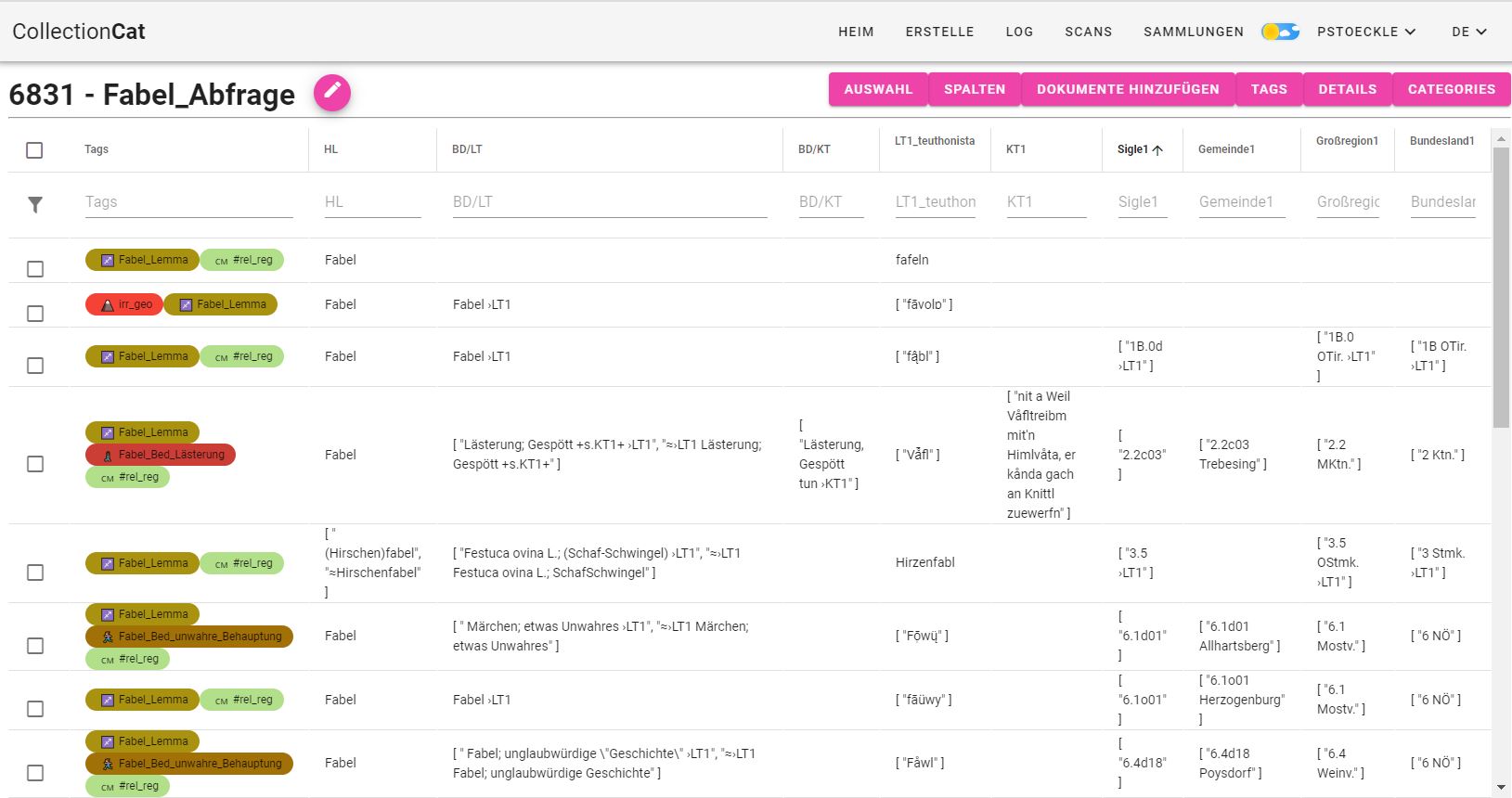
Collection Fabel_Abfrage in der Collection Cat
Für die Darstellung der Collection Fabel_Abfrage in Abbildung 4 wurden insgesamt zehn aus über 200 möglichen Spalten ausgewählt, die u.a. Angaben zum Hauptlemma („HL“), zur Bedeutung („BD/LT“ und „BD/KT“) zur Lautung („LT1_teuthonista“) und zu geographischen Informationen enthalten („Sigle1“, „Gemeinde1“ etc.). Die hohe Spaltenzahl ergibt sich – vereinfacht dargestellt – aus der Natur bzw. auch Modellierung der Originaldaten noch in TUSTEP bzw. auch in der Konvertierung zu XML/TEI. Zum einen führte die relativ „freie“ Erhebungsmethode durch eine hohe Anzahl ungeschulter Sammler*innen zu einer großen Heterogenität hinsichtlich der Inhalte der Handzettel, wodurch die Anzahl an Lautungsbelegen oder Belegsätzen teilweise stark variiert. So finden sich auf vereinzelten Handzetteln bis zu neun Lautungsbelege bzw. bis zu acht Belegsätze, die tabellarisch jeweils in einer eigenen Spalte angezeigt werden. Zum anderen können einige Informationen als hierarchische Datenformate tabellarisch nur durch Duplikation und Indizierung bestimmter Datenfelder angezeigt werden, weil sie in den Originaldaten nicht getrennt sind; dies betrifft insbesondere n:m- aber auch 1:n-Beziehungen. Gibt es z.B. mehrere Kontextbelege (KT1, KT2, KT3) zu einem Lemma und je Kontextbeleg ein oder mehrere Zusatzlemmata (ZL1, ZL2, ZL3), dann lässt sich das durch ein hierarchisches Markup leicht erfassen und abbilden, tabellarisch müssen diese Informationen atomisiert allerdings zu vielen eindeutigen Spalten (ZL1/KT1, ZL2/KT1, ZL1/KT2, ZL2/KT2, ...) aufgetrennt werden. Abbildung 5 illustriert die Darstellung mehrerer Zusatzlemmata (Wēiz, kriegen) zu einem Belegsatz (wir haben 30 fādl wǫɒts gekriegt) im XML/TEI-Format sowie in tabellarischer Form.
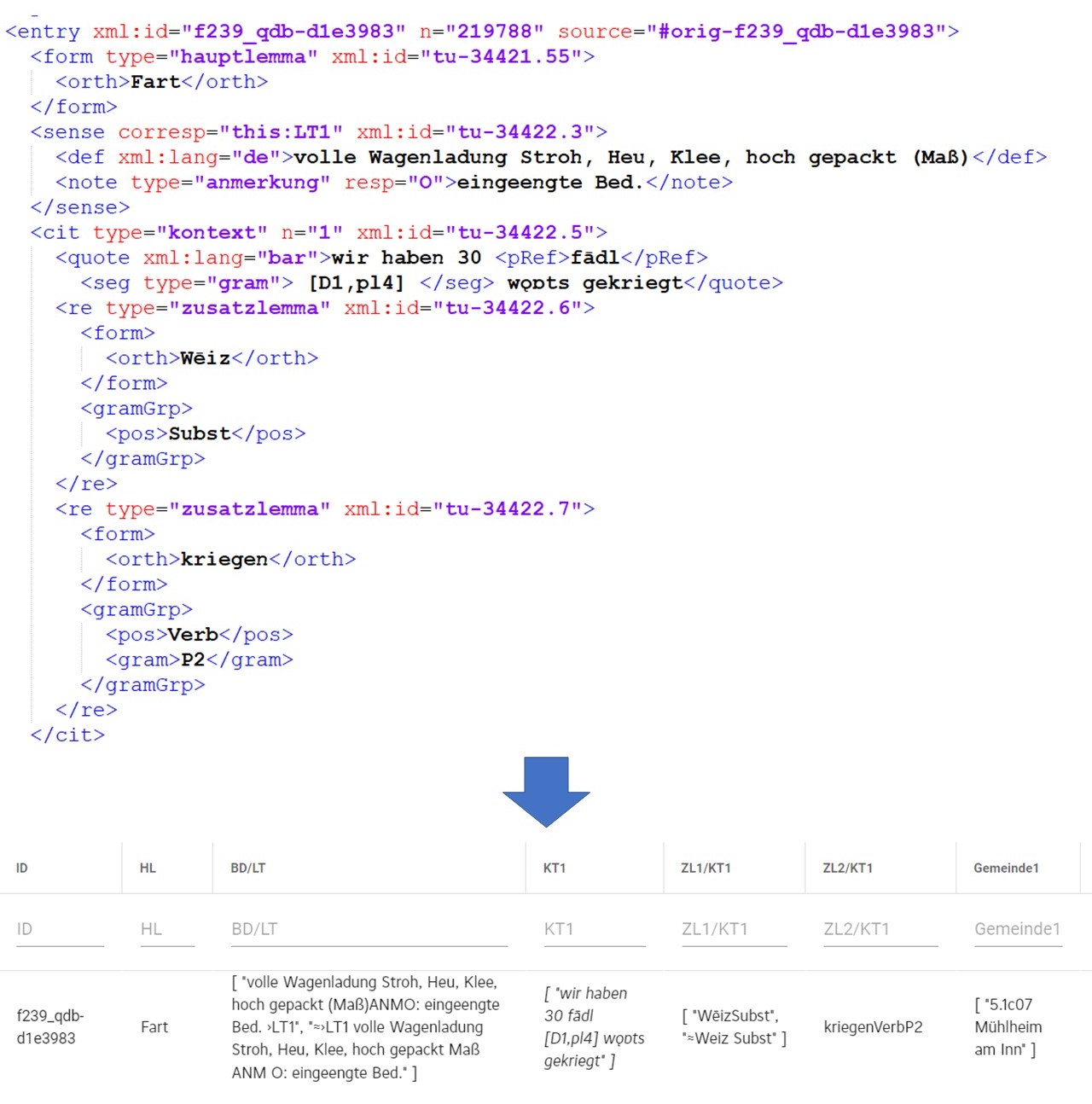
Abbildung von XML/TEI in tabellarischer Form
Eines der wichtigsten Werkzeuge für die Artikelarbeit stellen darüber hinaus die Tags dar, die eher einer klassischen Annotation entsprechen, da hier einzelne Datensätze ad hoc kategorisiert werden, also ein einzelner Datensatz einer Kategorie zugeordnet wird. In der Schreibpraxis werden die annotierten Belege dann wiederum zu Subsammlungen zusammengefasst, wobei natürlich ein Beleg in verschiedenen Kategorien auftauchen kann. Lexikograph*innen erstellen diese individuell und weisen sie in der Redaktionsarbeit bestimmten Daten zu. Durch die Vergabe von Tags kann jeder Beleg außerdem mit Zusatzinformationen versehen werden wie etwa zur regionalen Zugehörigkeit zum Bearbeitungsgebiet12 („rel_reg“ vs. „irr_reg“, d.h. 'regional relevant' vs. 'regional irrelevant'), zur Zugehörigkeit zum Lemma13 („Fabel_Lemma“) oder zu bestimmten Bedeutungen („Fabel_Bed_Lästerung“, „Fabel_Bed_unwahre_Behauptung“). Für die semantische Kategorisierung der Belege wird in erster Linie die Spalte „BD/LT“ ('Bedeutung der Lautungsangabe') herangezogen. Da die Angaben in dieser Spalte jedoch in vielen Fällen unzureichend, trivial14 oder schlichtweg nicht vorhanden sind, werden zusätzlich die Informationen aus den Spalten „BD/KT“ ('Bedeutungsangabe zum Belegsatz') oder „NR“ ('Fragebogen-Nummer') hinzugezogen. Im Anschluss an die Vergabe der Tags besteht der wichtigste Schritt darin, die Belege aufgrund der verschiedenen Tags neuen Sammlungen zuzuordnen, die wiederum verschiedenen Stellen im Artikel entsprechen (vgl. Abbildung 6).
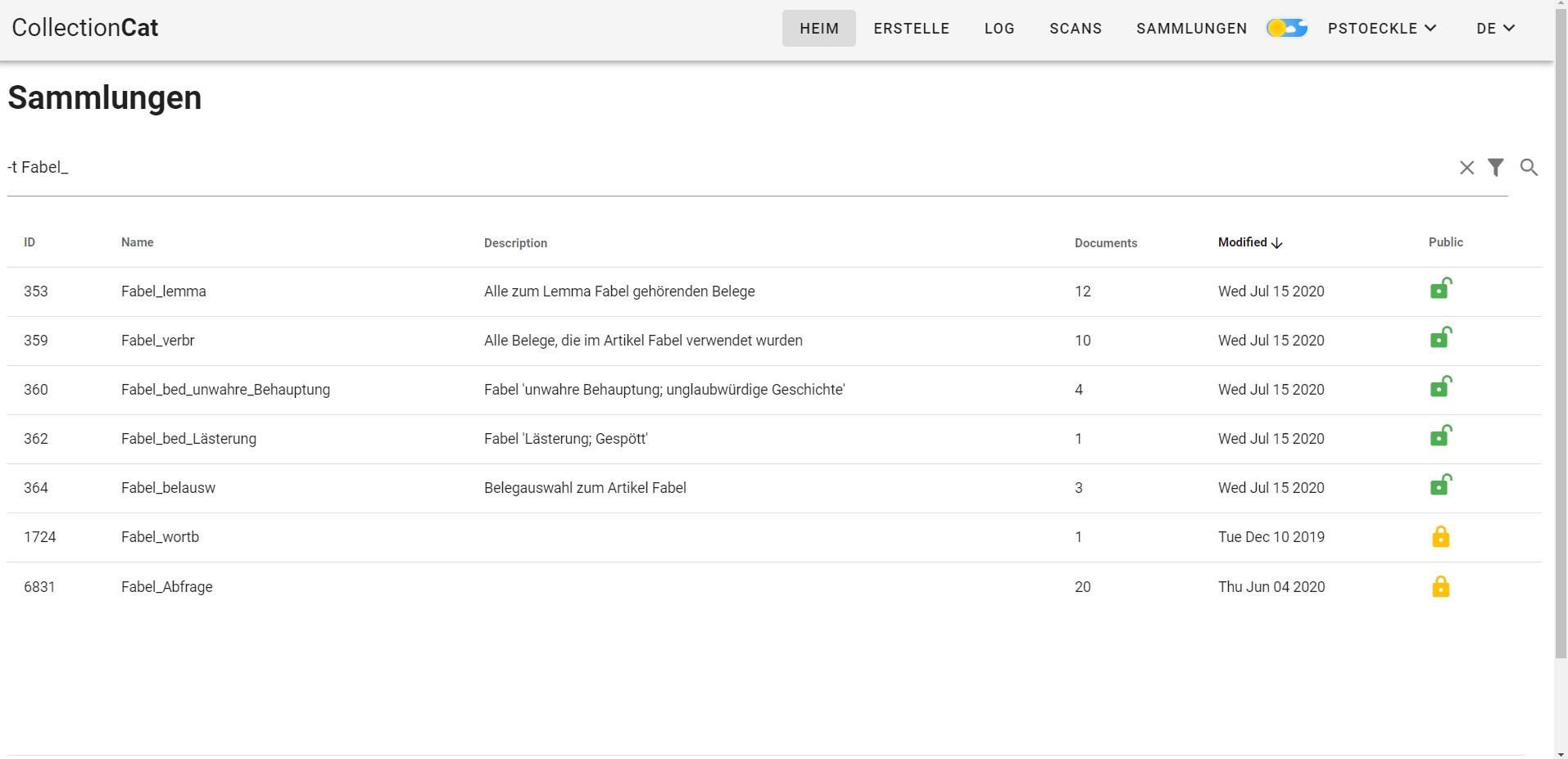
Collections zum Artikel Fabel
Wie oben erwähnt, stellen Sammlungen dann die kategorisierten Datenbestände dar, die zur Erstellung des Artikels verwendet worden sind – sie stellen somit, wie alle digitalen Arten der Datenkategorisierung, auch „eine technische, digitale Abbildung der geisteswissenschaftlichen Analyse dar“ (Breuer/Seltmann 2018, 146). Insbesondere beim vorliegenden Material ist die Vorstellung als „Sammlung“ von „(Beleg-)Zetteln“ und die entsprechende Bezeichnung eine relativ plastische, am Material orientierte.15 Diese Sammlungen können dann 1:1 auf LIÖ (s.u.) auch von externen Usern betrachtet werden. Im Artikel selbst werden die Sammlungen auch mit jenen Teilen des Artikels assoziiert, in denen sie eben die Grundlage zur Formulierung bilden, womit eine hohe Überprüfbarkeit und offene Datenlage geboten wird. Die Sammlung Fabel_verbr enthält alle Belege, auf denen der gesamte Artikel beruht16, Fabel_belausw enthält alle Lautungsbelege, die beispielhaft ausgewählt worden sind, während die Belege zu den verschiedenen Bedeutungen in den Collections Fabel_bed_unwahre_Behauptung und Fabel_bed_Lästerung versammelt sind. Das Einschreiben der Collection-IDs aus dem Recherchetool in die TEI-Artikel stellt auch den redaktionellen Übergang von Recherche- zu Redaktionstool dar. Im Folgenden wird das Redaktionstool ausführlicher vorgestellt.
3.2. Das WBÖ-Redaktionssystem
Das Ziel der Artikelschreibung unter technischen Gesichtspunkten besteht darin, Artikel in maschinenlesbarer Form so zu verfassen, dass diese ohne größeren Aufwand in verschiedene Online- und Print-Formate konvertiert werden können, wobei sämtliche Elemente der Artikel strukturell und semantisch eindeutig ausgezeichnet sein sollen. Als De-facto-Standard zur Auszeichnung von Texten hat sich dazu seit geraumer Zeit das XML/TEI-Format („Text Encoding Initiative“)17 etabliert und ist quasi Standard in verschiedenen geisteswissenschaftlichen Bereichen wie der Textedition oder Geschichtswissenschaft. Es bietet eine hohe Interoperabilität, umso mehr Projekte dieses Format zumindest zum Datenaustausch zur Verfügung stellen. Durch eine (nicht nur auf die Formatierung bezogen) inhaltliche Auszeichnung des Textes wird auch die Datensemantik technisch beschrieben und kann somit in anderen Kontexten standardisiert wiederverwendet werden. Dabei ist zwar entscheidend, dass die Daten schlussendlich in diesem Format vorliegen und verteilt werden (d.h. ein Export in dieses Format vorliegt, wie das ja z.B. bereits aus TUSTEP möglich wäre), allerdings bietet das genuine Formulieren in TEI auch Vorteile – insbesondere wenn technisch bereits entsprechende XML-Infrastrukturen vorliegen (wie das ja der Fall mit den Belegdaten ist). Deshalb hat man sich in Absprache mit der Datenabteilung des Austrian Centre for Digital Humanities and Cultural Heritage (ACDH-CH) dazu entschieden, die Artikel direkt in TEI anzulegen, um somit u.a. eine direktere, unvermittelte Form der Online-Publikation der Artikel zu gewährleisten und nicht erst über einen Exportschritt aus einem anderen System (WYSIWG). Dies garantiert auch, dass die Texte umgehend, also schon bei der Erstellung, TEI-standardkonform sind. Um die Artikel direkt in TEI erstellen zu können, ohne sich dabei jedoch mit dem für Nicht-Techniker ungewohnten Codierungssystem (Markup) auseinandersetzen zu müssen (was bei falscher Handhabung darüber hinaus auch zu Fehlern und Uneinheitlichkeiten führen kann), wurde ein eigenes Redaktionstool mit einer intuitiv(er) zugänglichen Benutzeroberfläche entwickelt. Die folgende Abbildung zeigt einen Ausschnitt der Benutzeroberfläche des Redaktionssystems.
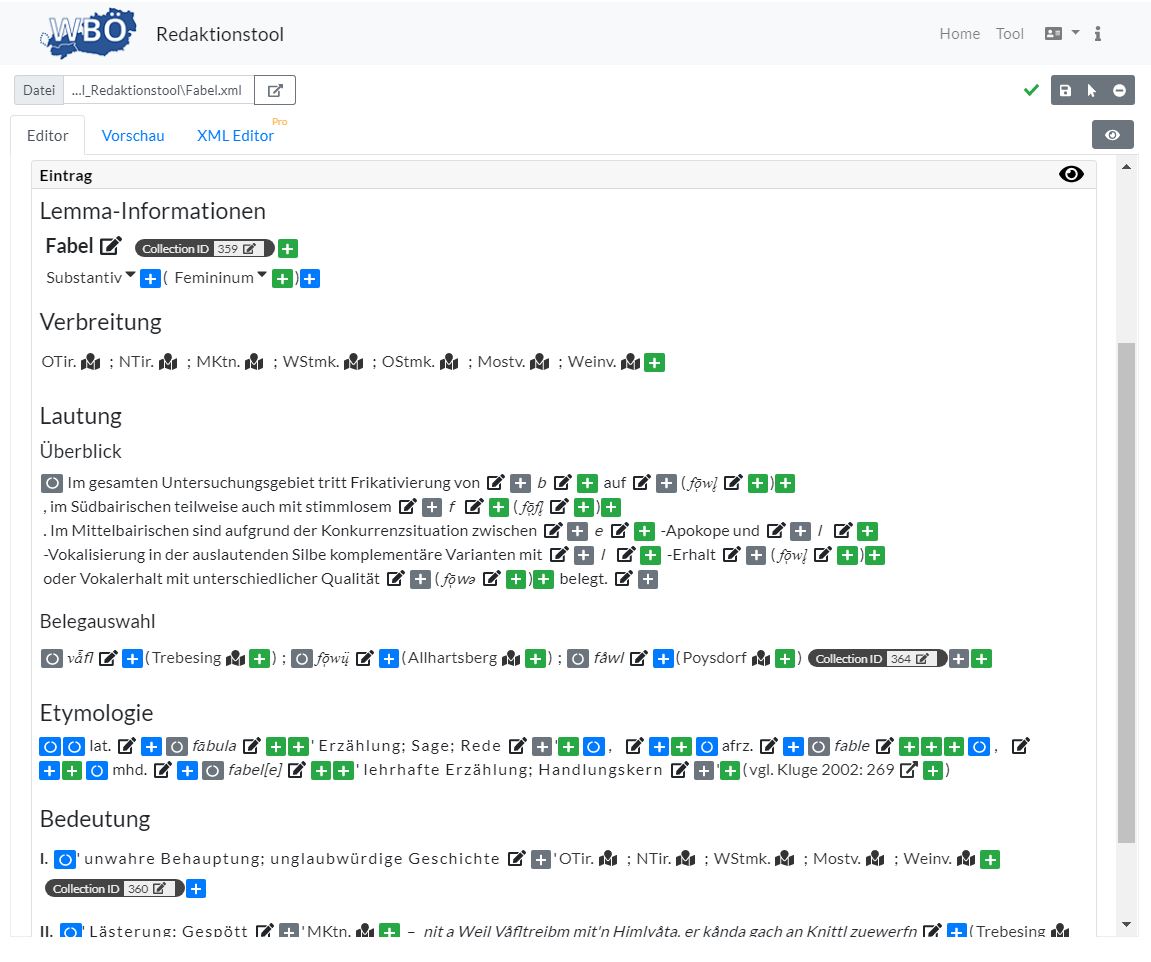
Redaktionstool-Benutzeroberfläche
Im Redaktionstool sind sämtliche Artikelpositionen (Artikelkopf, Verbreitung, Lautung, Etymologie, Bedeutung, Wortbildung, Redewendungen)18 sowie die einzelnen Inhaltselemente vordefiniert, sodass alle Eintragungen durch die Lexikograph*innen automatisch mit den richtigen TEI-Elementen und -Tags gespeichert werden.
Das Redaktionstool ist als Desktop-App konzipiert, beruht allerdings dennoch auf Webtechnologien, was durch den Einsatz des Open-Source-Frameworks Electron19 relativ leicht gewährleistet werden kann. Der Vorteil ist, dass durch die Systemintegration von Desktop-Apps systemspezifische Komponenten leichter genutzt werden können als im Browser. Electron-Apps können plattformübergreifend kompiliert werden. Im Prinzip handelt es sich bei dem Redaktionstool um einen XML-Editor, welcher allerdings mit vorgefertigten, speziell an die Anforderungen des WBÖ angepassten User Interface-Komponenten ein visuelles, intuitives Markup liefert, das genau für den Redaktionszweck angepasst ist. Prinzipiell ist – mit etwas Programmieraufwand – das Tool auch für andere Projekte einsetzbar, da das User Interface automatisch aus Templates generiert wird, in welchen auch die XML-Definitionen (Parser) festgelegt werden können, sodass nur wohlgeformte XML/TEI generiert werden können (je nach Restriktionsgrad). Für das WBÖ wurde das Tool speziell für die Artikel konzipiert und an entsprechende TEI-Strukturen angepasst. Sämtliche Artikel werden in einem Git-Repositorium gespeichert, welches mit einer BaseX-Datenbank synchronisiert wird, aus der für das Online-Rendering die Artikel abgerufen werden können. Das bedeutet, dass theoretisch alle Artikel nach dem Hochladen in das Repositorium ohne Umwege online publiziert werden – Redakteur*innen müssen sich dabei um keine weiteren technischen Dinge kümmern. Dies stellt auch die Verbindung zwischen Redaktionstool und LIÖ dar, welches die Artikel im Web abbildet.
In Bezug auf die interne Verlinkung relevant sind insbesondere die sog. „Collection-IDs“, die durch die schwarzen Felder symbolisiert werden. Diese sind auch in Abbildung 7 ersichtlich und stellen die Verknüpfung zu den entsprechenden Sammlungen her (vgl. Kapitel 3.1).
3.3. Das Lexikalische Informationssystem Österreich (LIÖ)
3.3.1. Möglichkeiten der internen Vernetzung
Im Zuge der WBÖ-Neukonzeption, bei der den digitalen Aspekten eine große Bedeutung beigemessen wird, wurde als zentraler Bestandteil das „Lexikalische Informationssystem Österreich (LIÖ)“20 mitentwickelt. LIÖ ist zunächst als generalisiertes lexikalisches Informationssystem für österreichische Daten konzipiert, weshalb bereits am Beginn der Konzeption mit dem Teilprojekt 11 des SFB „Deutsch in Österreich: Variation – Kontakt – Perzeption“21, das für die Online-Forschungsplattform zuständig ist22, und natürlich mit der Datenabteilung des ACDH-CH eng kooperiert wurde. Im Vordergrund steht aber im ersten Schritt die Publikation aller Daten und Inhalte des WBÖ. Diese sollen in der Zukunft ergänzt werden um andere Inhalte zur Lexik Österreichs aus unterschiedlichen Quellen (insbes. auch aus den Lexik-Daten aus den variationslinguistischen Teilprojekten23 des SFB „Deutsch in Österreich“). Die zentralen Komponenten umfassen derzeit die WBÖ-Artikel, die WBÖ-Belegdatenbank sowie ein interaktives Kartentool. Im Kartentool lassen sich die (georeferenzierten) Belege kartieren, somit können die geographischen Distributionen von Artikelinhalten, aber auch von Rechercheergebnissen, die sich direkt und individuell in der Belegdatenbank erstellen lassen, angezeigt werden.
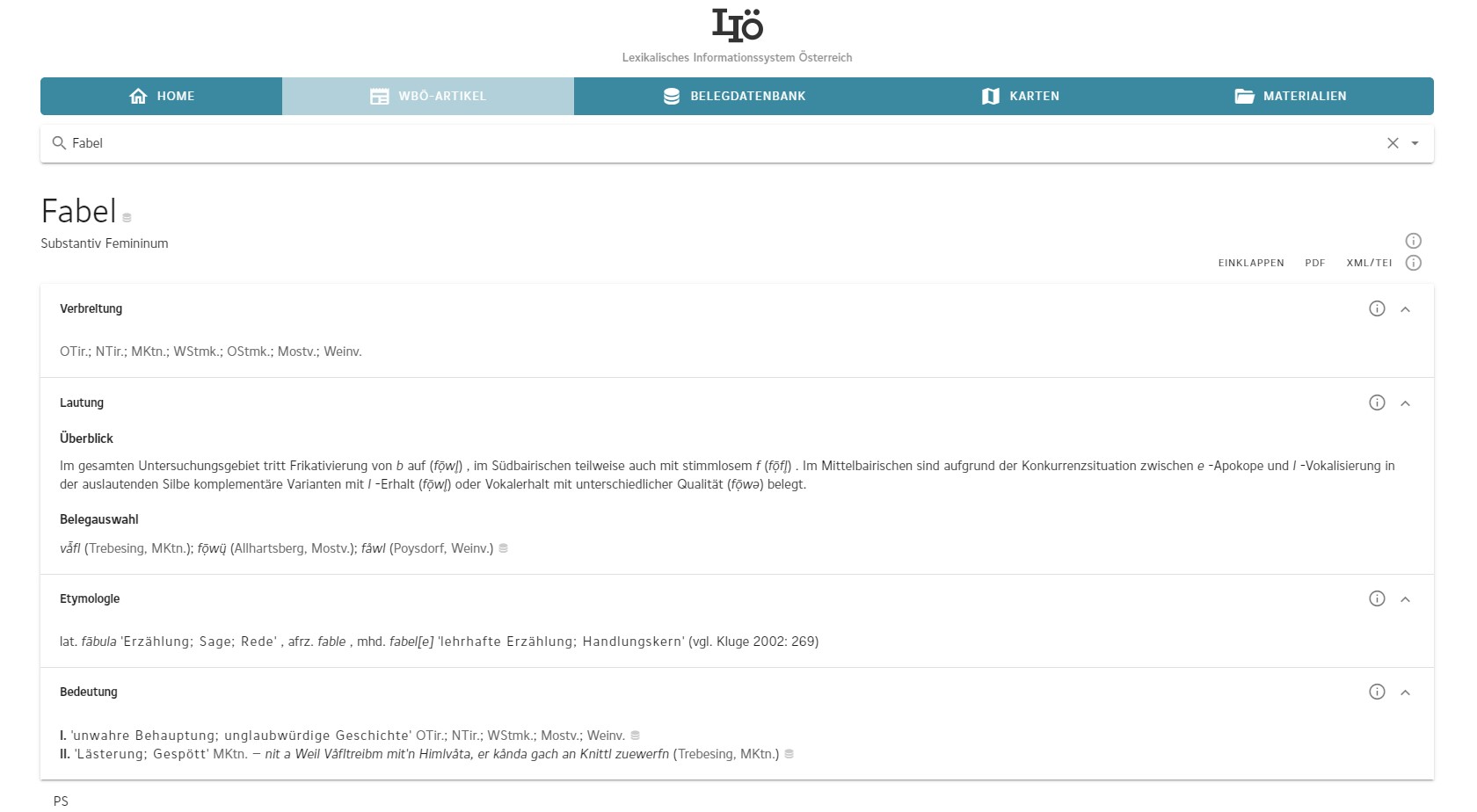
Darstellung des Artikels Fabel auf LIÖ
Abbildung 8 zeigt den Artikel Fabel, wie er im „Lexikalischen Informationssystem Österreich“ publiziert wird. Durch Klicken auf die kleinen Datenbank-Symbole am Ende der verschiedenen Einträge werden die entsprechenden Collections in der Belegdatenbank ausgewählt und können dort eingesehen und in verschiedene Formate exportiert werden bzw. auch direkt im Kartentool in ihrer geographischen Distribution angezeigt werden.
Für die Zukunft ist eine Verknüpfung der Einträge aus der Belegdatenbank mit den Scans der entsprechenden Handzettel (vgl. Abbildung 1) geplant, wozu bereits Komponenten im Recherchetool implementiert werden. Dies ermöglicht nicht nur eine Kontrolle der Abschriften, sondern gewährt auch interessierten Nutzer*innen einen Einblick in das originale Datenmaterial, das sonst nur sehr schwer zugänglich ist, und stellt somit einen wichtigen Beitrag zur Offenheit der Forschung und der Forschungsdaten dar. Darüber hinaus lassen sich somit natürlich auch Informationen, die für das maschinenlesbare Format reduziert wurden, wieder zugänglich machen, z.B. diverse Zeichnungen von Alltagsgegenstände, Schriftarten oder Ähnliches.
3.3.2. Möglichkeiten der externen Verknüpfung
Wie nun ersichtlich geworden sein sollte, wird in der Neukonzeption des WBÖ24 in den verschiedenen Aspekten der Datenanalyse, -aufbereitung und auch -verarbeitung in Form der Artikel ein möglichst interoperabler (Datenverknüpfung), nachvollziehbarer (Open Science), offener Datenzugang (Open Data) für alle erdenklichen Kontexte – also eben nicht nur wissenschaftlich – angestrebt. Dies wird ersichtlich an der Wahl des Datenformats, am (zusätzlichen, aber auch für den Artikelgeneseprozess durchaus effizienteren) Aufwand der digitalen Kategorisierung der Daten, aber eigentlich noch grundlegender an der prinzipiellen, strukturierten Verarbeitung und Speicherung der Daten. Dieser Ansatz führt ganz grundsätzlich zu einer (technischen/digitalen) höheren Interoperabilität und Nachnutzbarkeit der Daten. Für eine relativ einfache Verknüpfung der Daten mit Daten aus anderen Quellen allerdings sind überdies bestimmte, generalisierbare Entitäten zu identifizieren. Wie bereits in der Einleitung erwähnt, sind das insbesondere geographische Informationen, Lemmata sowie semantische Taxonomien. Da gerade in der momentanen Phase insbesondere das Schreiben und Veröffentlichen von Artikeln, d.h. eher projektzentrierte Arbeiten im Vordergrund stehen, können im Folgenden nur Schlaglichter künftiger Möglichkeiten und erste Überlegungen präsentiert werden.
Mehr oder minder vereinheitlichte Objektidentifizier liegen dabei vor allem für die geographische Einordnung vor (rein geographisch in Form von Koordinaten und gleichzeitig durch standardisierte Ortsnamen auch politisch-sozial), weshalb sich diese als erster Verknüpfungspunkt mit externen Projekten natürlich besonders anbieten. Dabei ist allerdings zu bedenken, dass es sich um historische Daten und somit auch geopolitisch zum Teil von den aktuellen Einteilungen abweichende Daten handelt, auch wenn sich diese durch ihre materielle Georeferenzialität gut rezent projizieren lassen. Diese Datenkategorie bietet gleichzeitig die wohl interdisziplinärsten Verknüpfungsmöglichkeiten, da geopolitische Entitäten natürlich in den verschiedensten wissenschaftlichen, objektorientierten Kontexten von Bedeutung sind – für sprachliche Varietäten sind sie natürlich eine entscheidende Größe, über die sie sich mehr oder minder zeitunabhängig mit verschiedenen linguistischen Daten verknüpfen lässt. So böte sich z.B. die Untersuchung von Wandel im (Dialekt-)Wortschatz an, indem man die Daten an einem Ort mit rezenten Daten, die am selben Ort erhoben worden sind, vergleicht. Genau dies ist geplant in Kooperation mit dem SFB DiÖ (s.o.), wobei hier eine weitere Entität sicherlich entscheidend ist, um diesen Prozess einerseits zu beschleunigen und andererseits weitere Zusammenhänge feststellen zu können: das Lemma.
Lemmata stellen als „Grundform“ oder „Stichwort“ eines Wortes ja bereits eine Generalisierung verschiedener Wortformen dar, d.h. zumindest innerhalb eines Wörterbuchs sind sie Identifikator (die bei Uneindeutigkeit ja auch indiziert werden). Dabei sind sie aber immer auf den bestimmten Anwendungszweck angepasst (Lemma im Wörterbuch <> Lemma in einer Korpusanalyse), was sich ja insbesondere auch im Vergleich der alten und neuen WBÖ-Konzeption gut zeigen lässt, da in der Neukonzeption der Lemmaansatz grundlegend geändert wurde.25 Das heißt, dass Lemmata als mehr oder minder bedeutungstragende, abstrakte Sammelentität trotz ihrer Generalisierung und Vereinheitlichung kaum als allgemeiner Indentifizierer geeignet sind – zumindest nicht, solange sie nicht über den Einzelanwendungsfall hinaus einem standardisierten Lemmavokabular entsprechen. Es bedarf dafür also eines kontrollierten Vokabulars zur Referenz. Hierfür ein geeignetes auszuwählen oder zu erstellen, wird Teil künftiger Bemühungen zur Steigerung der Interoperabilität der Daten sein.
Während das Lemma dann die eher sprachmaterielle bzw. darstellende Seite (wenn auch generalisiert) beschreibt, liegen im WBÖ natürlich insbesondere auch Daten zur eher konzeptionellen, bedeutungstragenden Einheit vor. Die Semantik ist dabei als verbindende Einheit nur schwer fassbar, auch hierfür bedarf es eines kontrollierten Vokabulars, das verschiedene Komponenten einer Bedeutungsangabe eineindeutig benennt, gleichzeitig aber auch spezifiziert. Derzeit ist hierfür die semantische Taxonomie von Hallig/von Wartburg 1963 vorgesehen, da diese auch in anderen Dialektwörterbüchern zu deutschen Varietäten bereits erfolgreich eingesetzt und adaptiert wurde, etwa in den (sprach-)historisch teils verwandten und geographisch benachbarten Projekten der Bayerischen Akademie der Wissenschaften „Bayerisches Wörterbuch (BWB)“ (vgl. Schnabel/Raaf/Schwarz 2021), „Fränkisches Wörterbuch (WBF)“ (vgl. König/Raaf/Klepsch 2021) und „Dialektologisches Informationssystem von Bayerisch-Schwaben (DIBS)“ (vgl. Schwarz/Funk/Raaf/Welsch 2021). Dabei besteht das Ziel häufig vor allem darin, die Daten semantisch besser fassbar zu machen und somit insbesondere die Durchsuchbarkeit zu erhöhen. Gleichzeitig steigern das semantische Kategorisieren und das Verwenden eindeutiger Identifikator aber – wie bereits dargestellt – auch deutlich die Interoperabilität und bieten Verknüpfungspunkte zu anderen Projekten. Hierfür wird im WBÖ ein enger Austausch mit anderen Wörterbuchprojekten angestrebt, wobei durch die Einbindung am ACDH-CH außerdem auf die Expertise der Abteilung DH Forschung & Infrastruktur und hier insbesondere auf die Vocabs Services26 zurückgegriffen werden kann.
Abgesehen von Entitäten, die sich zur Verknüpfung der Daten mit anderen Projekten eignen, gibt es natürlich künftig auch viele technische Aspekte zu klären. Für eine grundlegende Nutzung der Daten durch externe Nutzer*innen ist zwar bereits mit der Exportierbarkeit in nicht-proprietäre Formate (Belegdaten z.B. als CSV, Artikel in XML/TEI) direkt von der Webpage gesorgt, ebenso durch die genaue Beschreibung der Daten in den verschiedenen Texten, sowie einer geographischen Zuordnung. Damit die Daten aber auch dynamisch interoperabel sind, d.h. trotz Änderungen in der Datenbasis (z.B. durch Korrekturen, Neuzuordnungen, Kategorisierungen bzw. schlicht das Erstellen weiterer Artikel) müssen technische Schnittstellen konzipiert und implementiert werden, die es Entwickler*innen ermöglichen, die Daten leicht verständlich, zuverlässig, schnell und möglichst ohne Aufwand in andere (Online-)Systeme (wie z.B. Kartentools, Vergleichstabellen oder auch schlicht Homepages) einbinden zu können. Hierfür wird eine standardisierte Spezifikation (nach OpenAPI-Spezifikationen27) einer offenen Schnittstelle angestrebt. Die entsprechenden Anforderungen sollen anhand von Befragungen bzw. auch Besprechungen mit Projektpartner*innen formuliert werden, bevor sie technisch umgesetzt werden.
4. Schlussbemerkung
Das Ziel dieses Beitrags bestand darin, die Verknüpfung von inhaltlich-konzeptionellen Aspekten der Neubearbeitung des WBÖ seit 2016 einerseits und der technischen Seite andererseits vorzustellen und dabei besonders die sich daraus ergebenden Vernetzungsmöglichkeiten in den Fokus zu nehmen. Wie hoffentlich gezeigt werden konnte, handelt es sich dabei um eine konsistente, in sich abgeschlossene Gesamtkonzeption, bei der – mit einer Zentrierung auf das Artikelschreiben bzw. die redaktionelle Arbeit an sich – ineinandergreifende Tools konzipiert und implementiert wurden, die einen möglichst reibungslosen, effizienten Prozess der Datenaufbereitung, Analyse und des Schreibens ermöglichen sollen und dabei genuin eine hohe Interoperabilität, Datenkonsistenz und auch Nachhaltigkeit gewährleisten. Dabei wurden verschiedene moderne Konzepte der Digital Humanities (insbesondere der Webentwicklung) eingearbeitet und so weit als möglich berücksichtigt, wobei stets dem Ziel des Artikelschreibens oberste Priorität eingeräumt wurde. Wesentliche Aspekte in Bezug auf die Publikation von Artikeln, Daten und weiterer Materialen sind die niederschwellige Zugänglichkeit sowie ein möglichst offener Zugang zum generierten Wissen, aber auch zum gesamten Forschungsprozess und den Daten.
Wie ebenfalls deutlich wurde, bedarf es in Bezug auf die Interoperabilität noch einiger Modifikationen und Verbesserungen, besonders hinsichtlich der Identifizierung und Aufbereitung der Entitäten, die zur Verknüpfung geeignet sind, aber auch der Konzeption und Implementierung standardisierter technischer Schnittstellen. Gerade in diesem Zusammenhang sind die Fortführung, Intensivierung und der Ausbau von Kooperationen – wie etwa mit den bereits genannten Projekten der Bayerischen Akademie der Wissenschaften – von höchster Relevanz.
Bibliographie
- Barabas et al. 2010 = Barabas, Bettina / Hareter-Kroiss, Claudia / Hofstetter, Birgit / Mayer, Lana / Piringer, Barbara / Schwaiger, Sonja (2010): Digitalisierung handschriftlicher Mundartbelege. Herausforderungen einer Datenbank, in: Germanistische Linguistik 199–201. Fokus Dialekt. Festschrift für Ingeborg Geyer zum 60. Geburtstag, 47-64.
- Bauer/Kühn 1998 = Bauer, Werner / Kühn, Erika (1998): Vom Zettelkatalog zur Datenbank. Neue Wege der Datenverwaltung und Datenbearbeitung im "Wörterbuch der bairischen Mundarten in Österreich", in: Hutterer, Claus Jürgen / Pauritsch, Gertrude (Hrsgg.), Beiträge zur Dialektologie des ostoberdeutschen Raumes. Referate der 6. Arbeitstagung für bayerisch-österreichische Dialektologie, 20.–24.9.1995 in Graz, Göppingen, Kümmerle, 369-382.
- Bowers/Stöckle 2018 = Bowers, Jack / Stöckle, Philipp (2018): TEI and Bavarian dialect resources in Austria: updates from the DBÖ and WBÖ, in: Frank, Andrew U. / Ivanovic, Christine / Mambrini, Francesco / Passarotti, Marco / Sporleder, Caroline (Hrsgg.), Proceedings of the Second Workshop on Corpus-Based Research in the Humanities (CRH-2), Wien, Gerastree Proceedings, 45-54.
- Breuer/Seltmann 2018 = Breuer, Ludwig Maximilian / Seltmann, Melanie (2018): Sprachdaten(banken) – Aufbereitung und Visualisierung am Beispiel von SyHD und DiÖ, in: Germanistik digital. Digital Humanities in der Sprach- und Literaturwissenschaft, Facultas, 135-152.
- Brockhaus 2006 = Zwahr, Annette (Hrsg.) (212006): Brockhaus-Enzyklopädie : in 30 Bänden, Leipzig [u. a.], Brockhaus.
- DWB 1854-1971 = Grimm, Jacob / Grimm, Wilhelm (1854-1971): Deutsches Wörterbuch. Hg. von der Preußischen [später: Deutschen] Akademie der Wissenschaften zu Berlin [später: Akademie der Wissenschaften der DDR], Leipzig.
- Geyer 2019 = Geyer, Ingeborg (2019): Wörterbuch der bairischen Mundarten in Österreich: Rückblick auf 105 Jahre Erheben, Aufbereiten und Auswerten im institutionellen Rahmen der ÖAW, in: Kürschner, Sebastian / Habermann, Mechthild / Müller, Peter O. (Hrsgg.), Methodik moderner Dialektforschung. Erhebung, Aufbereitung und Auswertung von Daten am Beispiel des Oberdeutschen, Hildesheim, Olms, 471-488.
- Hallig/von Wartburg 1963 = Hallig, Rudolf / von Wartburg, Walther (21963 [1952]): Begriffssystem als Grundlage für die Lexikographie. Versuch eines Ordnungssystems, Berlin, Akademie-Verlag.
- Hornung 1976 = Hornung, Maria (1976): Wörterbuch der bairischen Mundarten in Österreich, in: Friebertshäuser, Hans (Hrsg.), Dialektlexikographie. Berichte über Stand und Methoden deutscher Dialektwörterbücher. Festgabe für Luise Berthold zum 85. Geburtstag am 27.1.1976, Wiesbaden, Steiner, 37-47.
- König/Raaf/Klepsch 2021 = König, Almut / Raaf, Manuel / Klepsch, Alfred (2021): Das Fränkische Wörterbuch (WBF), in: Lenz, Alexandra N. / Stöckle, Philipp (Hrsgg.), Germanistische Dialektlexikographie zu Beginn des 21. Jahrhunderts, Stuttgart, Steiner, 77-104 (Link).
- Philipp 2021 = Philipp, Stöckle (2021): Wörterbuch der bairischen Mundarten in Österreich (WBÖ), in: Alexandra N., Lenz / Philipp, Stöckle (Hrsgg.), Germanistische Dialektlexikographie zu Beginn des 21. Jahrhunderts, Stuttgart, Stuttgart, 11-46, ISBN: 978-3-515-12920-6 (Link).
- Reiffenstein 2005 = Reiffenstein, Ingo (2005): Die Geschichte des "Wörterbuchs der bairischen Mundarten in Österreich" (WBÖ). Wörter und Sachen im Lichte der Kulturgeschichte, in: Hausner, Isolde / Wiesinger, Peter (Hrsgg.), Deutsche Wortforschung als Kulturgeschichte. Beiträge zum Symposium "90 Jahre Wörterbuchkanzlei" der Österreichischen Akademie der Wissenschaften, Wien, 25.–27. September 2003, Wien, Verlag der Österreichischen Akademie der Wissenschaften, 1-13.
- Schnabel/Raaf/Schwarz 2021 = Schnabel, Michael / Raaf, Manuel / Schwarz, Daniel (2021): Bayerisches Wörterbuch (BWB), in: Lenz, Alexandra N. / Stöckle, Philipp (Hrsgg.), Germanistische Dialektlexikographie zu Beginn des 21. Jahrhunderts, Stuttgart, Steiner, 47-76 (Link).
- Schwarz/Funk/Raaf/Welsch 2021 = Schwarz, Brigitte / Funk, Edith / Raaf, Manuel / Welsch, Ursula (2021): Dialektologisches Informationssystem von Bayerisch-Schwaben (DIBS), in: Lenz, Alexandra N. / Stöckle, Philipp (Hrsgg.), Germanistische Dialektlexikographie zu Beginn des 21. Jahrhunderts, Stuttgart, Steiner, 105-141 (Link).
- SchweizId. 1881-lfd. = SchweizId. (1881-lfd.): Schweizerisches Idiotikon. Wörterbuch der schweizerdeutschen Sprache. Gesammelt auf Veranstaltung der Antiquarischen Gesellschaft in Zürich unter Beihülfe aus allen Kreisen des Schweizervolkes. Hg. mit Unterstützung des Bundes und der Kantone. Begonnen von Staub, Friedrich und Tobler, Ludwig. Fortges. unter der der Leitung von Bachmann, Albert, u.a., Frauenfeld (Link).
- Stöckle 2021 = Stöckle, Philipp (2021): Wörterbuch der bairischen Mundarten in Österreich (WBÖ), in: Lenz, Alexandra N. / Stöckle, Philipp (Hrsgg.), Germanistische Dialektlexikographie zu Beginn des 21. Jahrhunderts, Stuttgart, Steiner, 11-46 (Link).