1. Carte dialettologiche
1.1. Carte di lavoro
Con carta di lavoro (ted. Arbeitskarte) si intende una carta che risulta dall'analisi intralinguistica di una carta originale, contenuta in un atlante linguistico. Il numero delle carte di lavoro supera il numero delle carte originali, dato che ogni carta d'atlante può essere interpretata (= analizzata = tassata) secondo vari principi metrologici: criteri fonetici, morfologici, sintattici o lessicali.
Allo stato attuale (marzo 2023), la banca-dati del progetto ALD-DM contiene 6.057 carte di lavoro (si veda, a questo proposito, anche la cosiddetta catena dialettometrica riferita al ns. progetto di ricerca, cf. Bauer 2016, 13).
1.1.1. Fonetica
Come principio metrologico delle carte fonetiche si sceglie, in genere, un nesso latino contenuto nell'etimo che sta in base al titolo della carta d'atlante. Nel progetto ALD-DM, il 43% circa di tutte le analisi riguarda tassazioni fonetiche, distribuite in maniera equilibrata su vocalismo e consonantismo.
1.1.1.1. Sviluppo di -U (< PÉTRU)1
Analisi degli esiti dialettali del nesso latino -U (< PÉTRU), osservabili sulla carta ALD-I 601 Pietro (PDF). La carta mostra la riduzione di 218 risposte dialettali (tokens)2 a sei tipi fonetici (types) nonché la distribuzione di questi sei tassati nello spazio d'osservazione (= rete ALD). Il tassato 1 (-o finale come ad es. in [piéro]), maggioritario con una frequenza di 150 su 218, è rappresentato in rosso. Il tassato 2 riguarda la -u finale del tipo [pédru] (poligoni gialli: lombardo alpino). Il terzo tassato rappresenta le risposte "germaniche" del tipo [péder], riscontrabili nei Grigioni (poligoni grigi), il tassato 4 sta per la -e di [piére] (blu chiaro: ladino dolomitico meridionale e friulano occidentale), il quinto tipo rappresenta lo schwa in [pírə] (blu scuro: ladino dolomitico settentrionale) e il tassato numero 6 sta per la -i del friulano [piéri] (poligoni verdi).
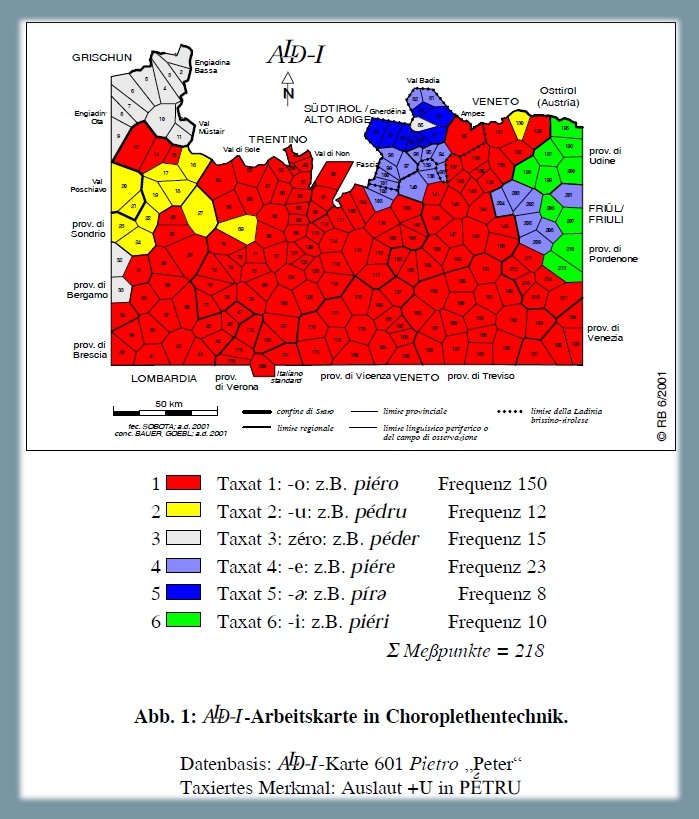
Carta di lavoro fonetica: esiti del nesso -U ← PÉTRU (Bauer 2002c, 97)
In base alla stessa carta originale si possono anche tassare i nessi che riguardano il consonantismo all'inizio di parola (P-), il vocalismo tonico (-É-) oppure il nesso intervocalico -TR-.
1.1.1.2. Sviluppo di V- (< VÓCE)3
Analisi degli esiti dialettali del nesso latino V- (< VÓCE), osservabili sulla carta ALD-I 873 la voce (PDF). La carta mostra la riduzione di 219 risposte dialettali (tokens)4 a quattro tipi fonetici (types) nonché la distribuzione di questi quattro tassati nello spazio d'osservazione (= rete ALD). Il tassato 1 "zéro" si riferisce alle risposte con aferesi in cui la /v/ iniziale è saltata: (come ad es. nella variante ladina [ūš], poligoni colorati in rosa). Il tassato maggioritario no. 2 (= 103 poligoni gialli) riguarda il mantenimento della /v/ iniziale, ad es. nel tipo veneto [vóẓe]. Il terzo tassato rappresenta le risposte con /g/ iniziale, tipo trentino occidentale [guš], mentre il tassato 4 sta per la γ- di [γṷọṣ] (un unico poligono blu nel Cadore). Ovviamente anche questa carta potrebbe essere tassata secondo altri (tre) criteri fonetici, e cioè -Ó-tonica, -C- intervocalica e -E atona finale.
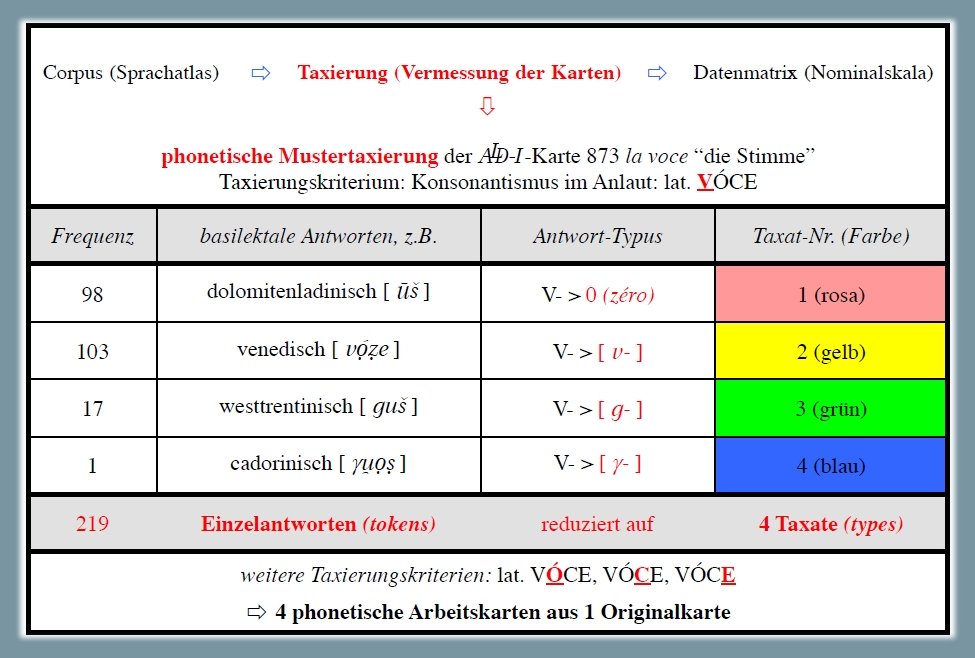
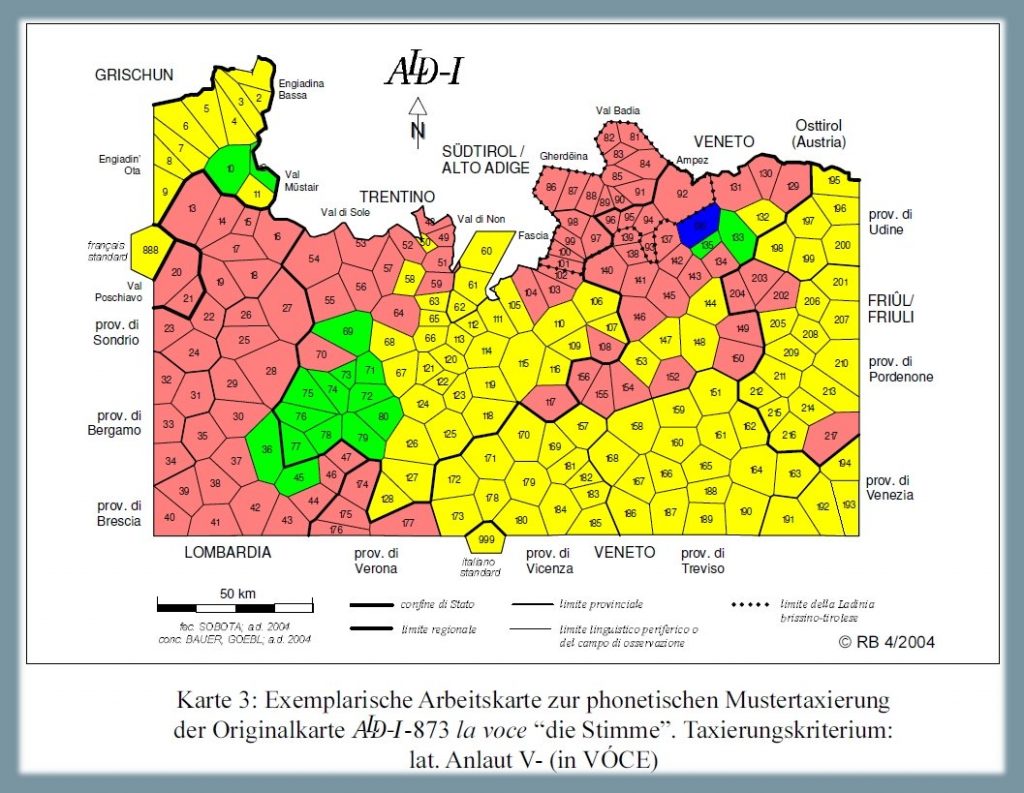
Carta di lavoro fonetica: esiti del nesso V- ← VÓCE (Bauer 2004, 210)
1.1.1.3. Sviluppo di V- (< VÚLPE) nei dialetti ladini5
Analisi degli esiti dialettali ladini del nesso latino V- (< VÚLPE), osservabili sulla carta ALD-I 878 la volpe (PDF). La carta mostra la riduzione di 22 risposte dialettali (tokens) a tre tipi fonetici ladini (types) nonché la distribuzione di questi tre tassati ladini nello spazio d'osservazione (= Ladinia dolomitica, secondo ALD). Il tassato maggioritario "zéro" si riferisce alle risposte con aferesi, come ad es. alla variante badiotta [ólp] (poligoni rossi). Il secondo tassato riguarda il mantenimento della /v/ iniziale nel tipo [vólp] (poligoni blu). Il terzo tassato rappresenta le risposte con betacismo: tipo gardenese e fassano [bólp] (poligoni gialli).
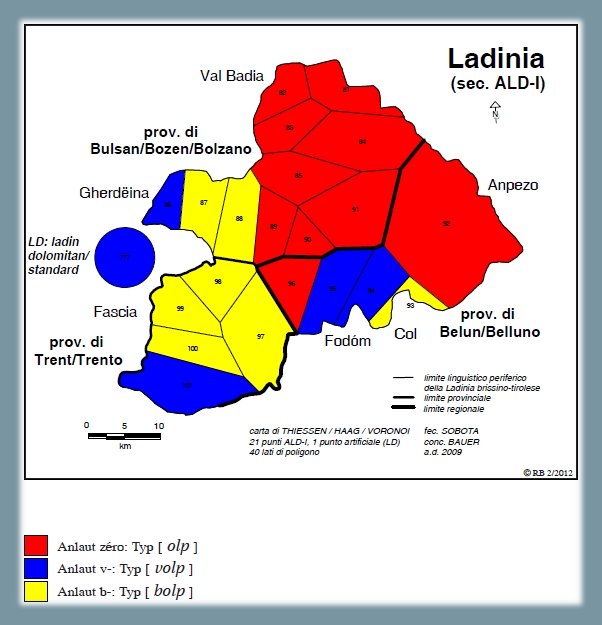
Carta di lavoro fonetica: esiti del nesso V- ← VÚLPE (Bauer 2012b, 288)
1.1.1.4. Sviluppo di -B- (< CABÁLLU)6
Analisi degli esiti dialettali del nesso latino -B- (< CABÁLLU), osservabili sulla carta ALD-I 130 il cavallo (PDF). La carta mostra la riduzione di 220 risposte dialettali (tokens)7 a quattro tipi fonetici (types) nonché la distribuzione di questi quattro tassati nello spazio d'osservazione (= rete ALD). Il tassato 1 (15 poligoni blu) si riferisce al tipo "zéro" con sincope della /b/ intervocalica [kaál]. Il tipo maggioritario (198 poligoni rossi) riguarda le risposte con fricativizzazione della /b/ in /v/, come ad es. nella variante gardenese [ćavál]. Il terzo tipo con la fricativa bilabiale [β] appare solo una volta (Livigno: [kaβál], poligono giallo). Nel quarto tipo appare la semivocale [ ṷ ], osservata ad es. nel lombardo orientale [ kaṷál ] (poligoni verdi).
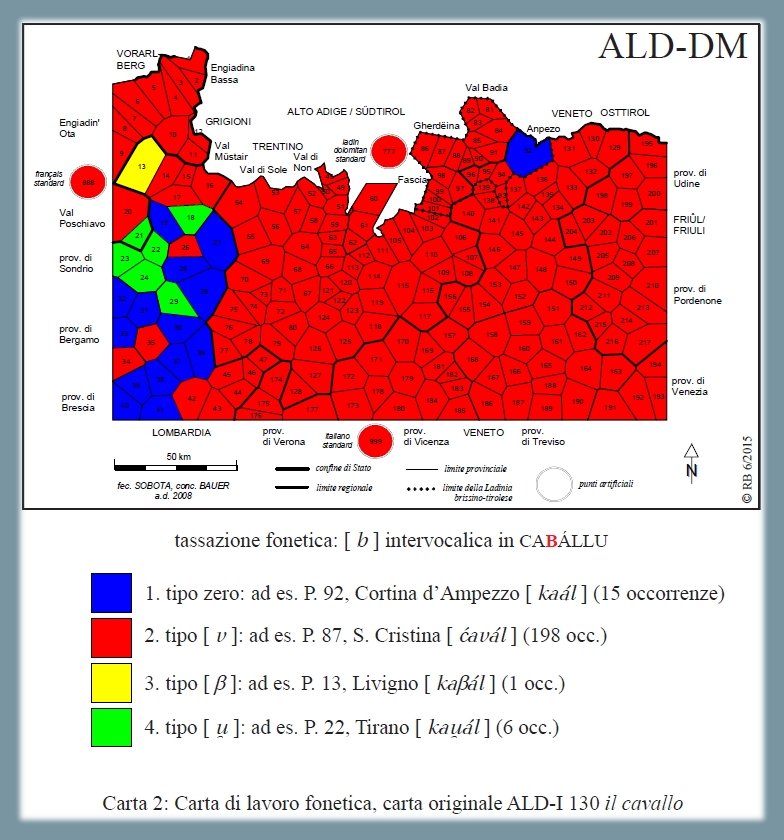
Carta di lavoro fonetica: esiti del nesso -B- ← CABÁLLU (Bauer 2016, 15)
1.1.2. Lessico
Il principio metrologico delle carte lessicali si riferisce alla presenza di signifiants (= tipi onomasiologici/etimologici) divergenti per la denominazione di un unico signifié. Nel progetto ALD-DM, il 35% circa di tutte le analisi riguarda tassazioni lessicali.
1.1.2.1. "amico"8
Analisi lessicale dei tipi onomasiologici che stanno per il signifié "amico", secondo la carta ALD-I 25 l'amico (PDF). La carta mostra la riduzione di 219 risposte dialettali (tokens) a quattro tipi lessicali (types) nonché la distribuzione di questi quattro tassati nello spazio d'osservazione (= rete ALD). Il tassato 1 (< AMÍCU), maggioritario con una frequenza di 187 su 219 e rappresentato in rosa, si riferisce a risposte come ad es. [amí, amís, amíco]. Il tassato 2 (poligoni blu) riunisce le risposte risalenti a SÓCIU, il terzo tassato (poligoni gialli) quelle associabili a COMPÁNIO e il tassato 4 (color verde) quella con etimo COLLÉGA.

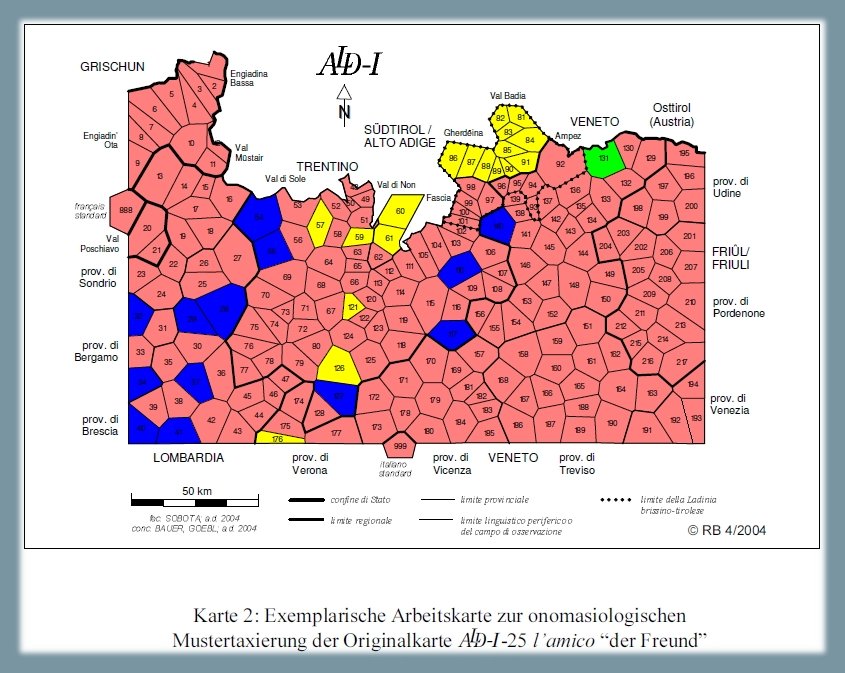
Carta di lavoro lessicale: "amico" (Bauer 2004, 208-209)
1.1.2.2. "affilare"9
Analisi lessicale dei tipi onomasiologici che stanno per il signifié "affilare", secondo la carta ALD-I 8 affilare (PDF). La carta mostra la riduzione di 220 risposte dialettali (tokens) a 14 tipi lessicali (types) nonché la distribuzione di questi 14 tassati nello spazio d'osservazione (= rete ALD):
A livello etimologico, i 14 tassati sono da ricondurre a:
tassato 1 ← AFFILÁRE, tassato 2 ← ACUTIÁRE, tassato 9 ← MOLLIÁRE, tassato 10 ← PASSÁRE + ÍLLA + PÉTRA, tassato 11 ← RE- + FILÁRE, tassato 12 ← FILÁRE, tassato 13 ← MOLLIÁRE + ÍLLU + FÉRRU, tassato 17 ← derivato da PÉTRA, tassato 18 ← DÁRE + HIC + ÍLLA + PÉTRA, tassato 19 ← DÁRE + HIC + ÍLLU + FÉRRU, tassato 20 ← FILÁRE + CUM + ÍLLA + PÉTRA, tassato 27 ← ACUTIÁRE, tassato 33 ← BATTÚERE, tassato 40 ← IN- + ACUTIÁRE
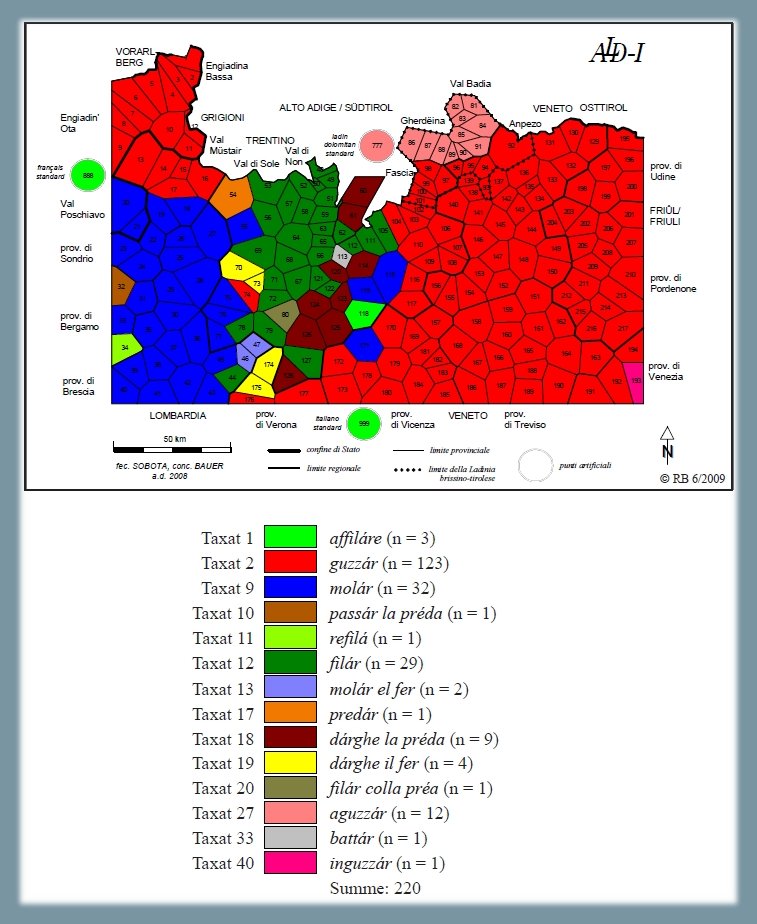
Carta di lavoro lessicale: "affilare" (Bauer 2009, 185)
Analisi lessicale dei tipi onomasiologici ladini che stanno per il signifié "il calcagno", secondo la carta ALD-I 88 il calcagno (PDF). La carta mostra la riduzione di 22 risposte dialettali (tokens) a tre tipi lessicali (types) nonché la distribuzione di questi tre tassati nello spazio d'osservazione (= Ladinia dolomitica, secondo ALD, Bauer 2014c, 54). Si tratta del tipo maggioritario CALCÁNEU, presente in Val Badia, Val Gardena, Val di Fassa e nello standard Ladin Dolomitan (poligoni rossi), del tipo [renćéi] di etimologia incerta (due poligoni verdi) e del tipo TALÓNE (Livinallongo ed Ampezzo, poligoni blu).
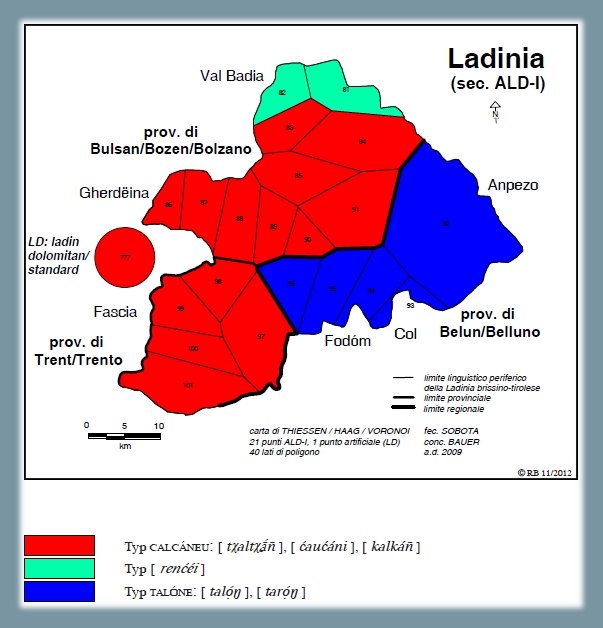
Carta di lavoro lessicale: "il calcagno" (Bauer 2012b, 287)
Analisi lessicale dei tipi onomasiologici che stanno per il signifié "la camera", secondo la carta ALD-I 96 la camera (PDF). La carta mostra la riduzione di 220 risposte dialettali (tokens) a cinque tipi lessicali (types) nonché la distribuzione di questi cinque tassati nello spazio d'osservazione (= rete ALD). Si tratta del tipo maggioritario CÁMERA (poligoni verdi), del tipo *EXTUPÁRE (Val di Sole & Val di Non, poligoni blu), del tipo STÁRE (Val Poschiavo, poligoni arancioni), del tipo MÁNSIO (Val Gardena, poligoni rossi) e del tipo CÁNABA (Livinallongo, poligoni gialli).
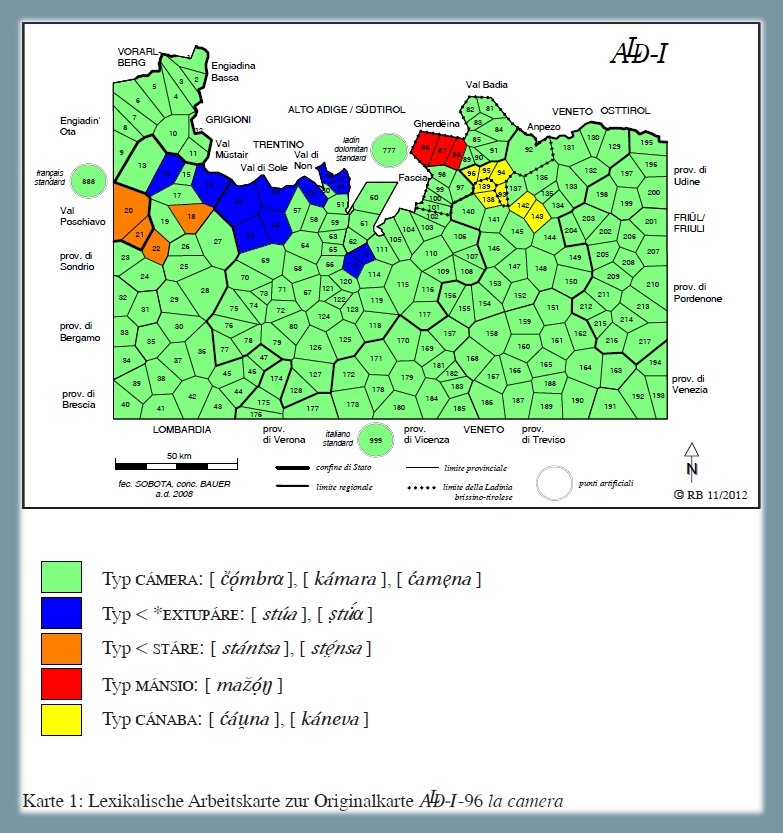
Carta di lavoro lessicale: "la camera" (Bauer 2014, 530)
Analisi lessicale dei tipi onomasiologici friulani che stanno per il signifié "il balcone", secondo la carta ALD-I 57 il balcone (PDF). La carta mostra la riduzione di 26 risposte dialettali (tokens) a sette tipi lessicali (types) nonché la distribuzione di questi sette tassati friulani nello spazio d'osservazione (= rete Friuli, secondo ALD, Bauer 2015, 24). Salta all'occhio la grande variazione lessicale!
Il tipo 1, maggioritario (9/26 occorrenze = poligoni rossi), a cui appartengono anche l’italiano balcone e l’italianismo francese balcon (si vedano i due cerchi rossi, no. 888 e 999), risale al longobardo *BÁLKO “trave” e si trova ad es. nelle varianti della Valcellina. Il secondo tipo ha come base un derivato diminutivo *PODIÓLU da lat. PÓDIU “podio”. Il terzo tipo risale a un derivato dal lat. TÉRRA (con suffisso -ÁCEA). Il quarto tassato riguarda la forma del ladino standard [ solé ] (cerchio verde con no. 777) riconducibile al lat. SOLÁRIU che aveva due significati, “orologio solare” e, appunto, “parte della casa esposta al sole”. Il tipo 5, dialetto di Sacile, nella fascia di transizione friulano-veneta, ha come base lat. PÉRGULA “poggiolo, loggetta”. La variante 6, carnica [ línḍo / línḍa / línde ] (con 4 occorrenze) deriva dal lat. LÍMITE. La forma 7 [ balkonáda ] infine, documentata solo in un punto-ALD, a Pordenone, è uno dei tanti derivati del tipo 1 (qui con suffisso -ATA).
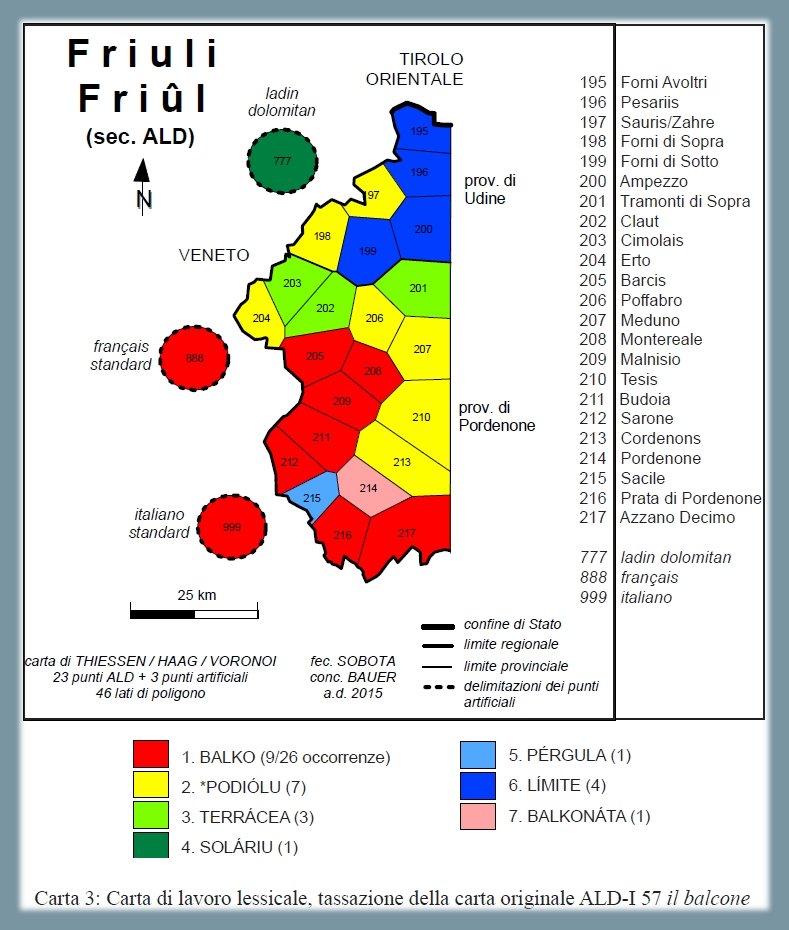
Carta di lavoro lessicale: "il balcone" (Bauer 2015, 26)
Analisi lessicale dei tipi onomasiologici che stanno per il signifié "moglie", secondo la carta ALD-II 30 (Sua) moglie (è incinta) (PDF). La carta mostra la riduzione di 220 risposte dialettali (tokens) a quattro tipi lessicali (types) nonché la distribuzione di questi quattro tassati nello spazio d'osservazione (= rete ALD). Il tipo 1 (di stampo veneto) deriva dal latino MULIÉRE, il tipo 2 (tipico dei Grigioni) risale a DÓMINA, il terzo tipo, maggioritario (149/220 occorrenze) a FÉMINA ed il quarto tipo, diffuso nel Trentino, a SPÓ(N)SA.
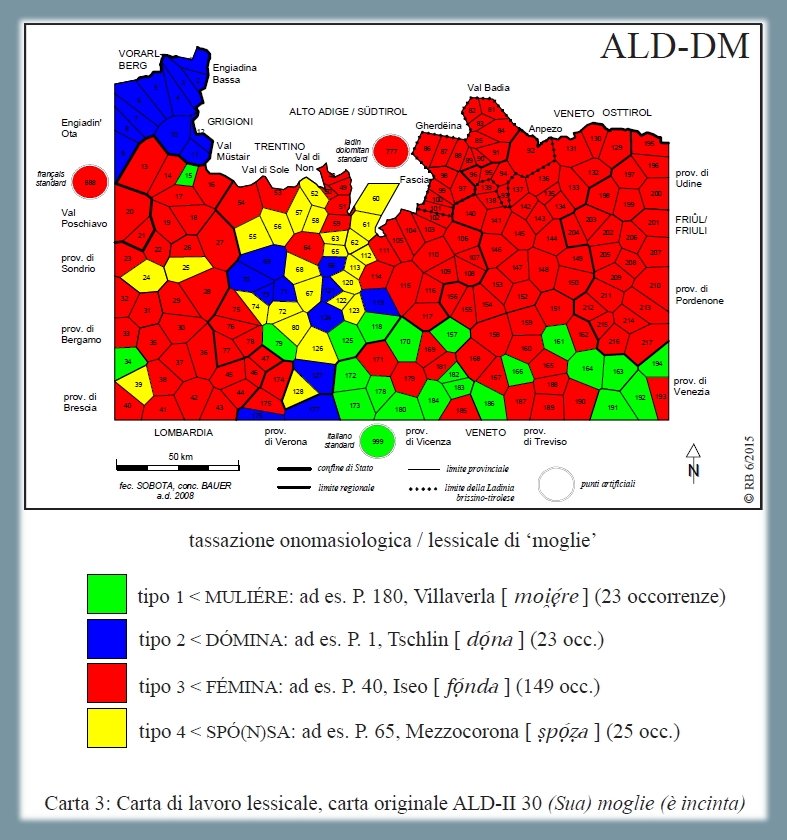
Carta di lavoro lessicale: "moglie" (Bauer 2016, 16)
Analisi lessicale dei tipi onomasiologici che stanno per il signifié "l'arcobaleno", secondo la carta ALD-II 690 l'arcobaleno (PDF). La carta mostra la riduzione di 220 risposte dialettali (tokens) a 12 tipi lessicali (types) nonché la distribuzione di questi 12 tassati nello spazio d'osservazione (= rete ALD).
I poligoni bianchi con cifre rosse (si veda la colonna destra sulla carta sottostante) stanno per i dialetti, in cui un vecchio tipo onomasiologico, ancora documentato nell'AIS, nell'ALI o nell'ASLEF, è stato sostituito dal tipo italiano arcobaleno.
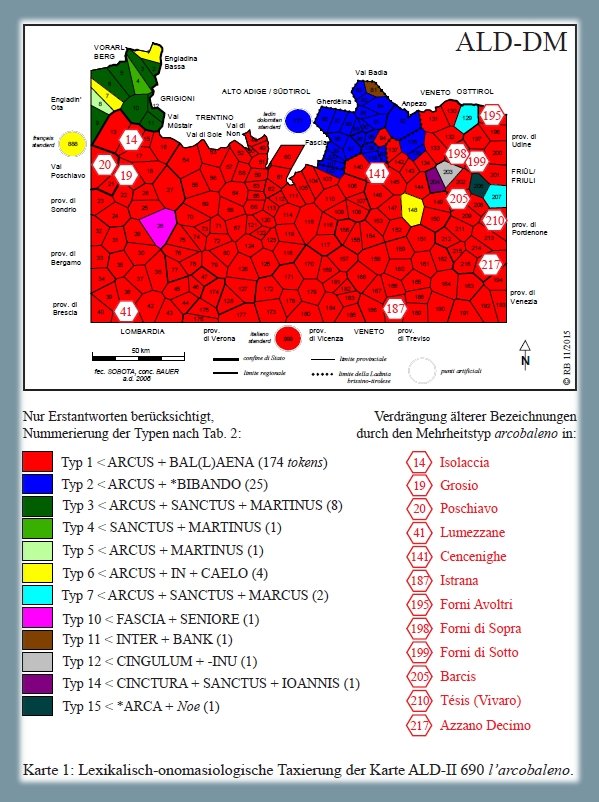
Carta di lavoro lessicale: "l'arcobaleno" (Bauer 2017, 135)
1.1.3. Morfosintassi
Il principio metrologico delle carte morfosintattiche si riferisce alla scelta di un criterio morfologico e/o sintattico. Nel progetto ALD-DM, solo il 15% di tutte le analisi riguarda tassazioni di questo genere, il subcorpus morfosintattico essendo allo stato attuale (maggio 2019) ancora in fase di elaborazione.
Analisi morfologica della formazione del plurale verbale di 1a persona in base alle carte ALD-II 1.061 stiamo, 598 crediamo e 724 dormiamo (PDF). La carta mostra la riduzione di 220 risposte dialettali (tokens) a solo due tipi morfologici (types) nonché la distribuzione di questi due tassati nello spazio d'osservazione (= rete ALD). Il tassato minoritario (42/220 occorrenze = poligoni rossi) si riferisce ai dialetti in cui la desinenza verbale della 1a persona plurale risale al latino -ÚMUS (come ad es. nel gardenese ciantón "cantiamo" < latino volgare *CANTÚMUS), mentre l'altro tassato riunisce tutti gli altri tipi di plurale.
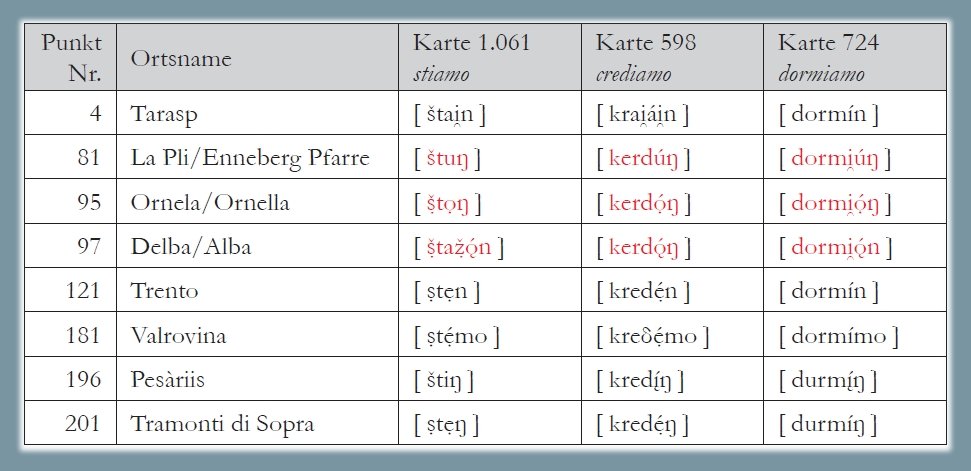
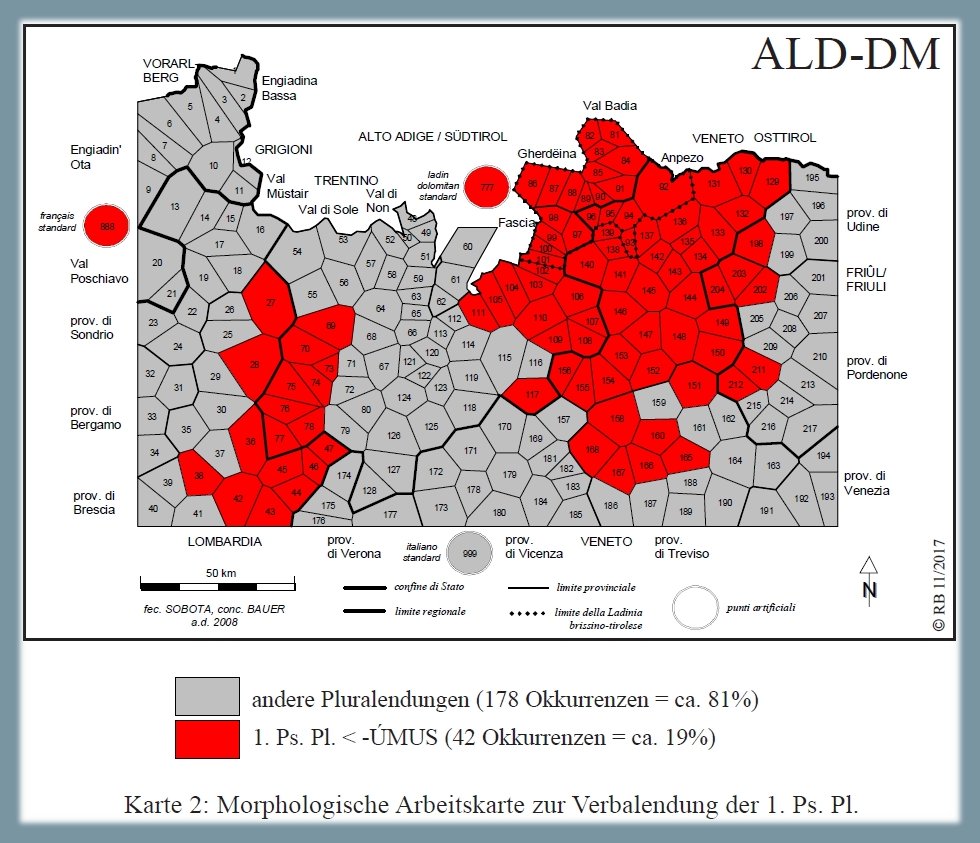
Carta di lavoro morfologica: il plurale verbale (Bauer/Casalicchio 2017, 85)
1.1.3.2. Omomorfia, 3a pers.16
Analisi morfologica delle desinenze verbali della 3a persona in base alle carte ALD-II 1.060 sta/stanno, 486 mangiava/mangiavano e 382 avesse/avessero (PDF). La carta mostra la riduzione di 220 risposte dialettali (tokens) a due tipi morfologici (types) nonché la distribuzione di questi due tassati nello spazio d'osservazione (= rete ALD). Il tassato maggoritario (185/220 occorrenze = poligoni rossi) si riferisce ai dialetti con omomorfia, in cui le desinenze verbali della 3a persona singolare sono identiche a quelle della 3a persona plurale, mentre l'altro tassato riunisce i dialetti senza omomorfia.
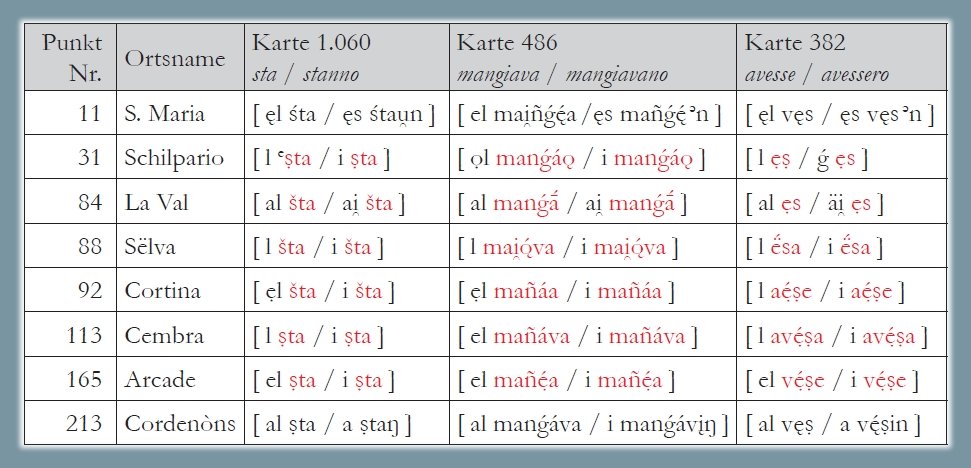
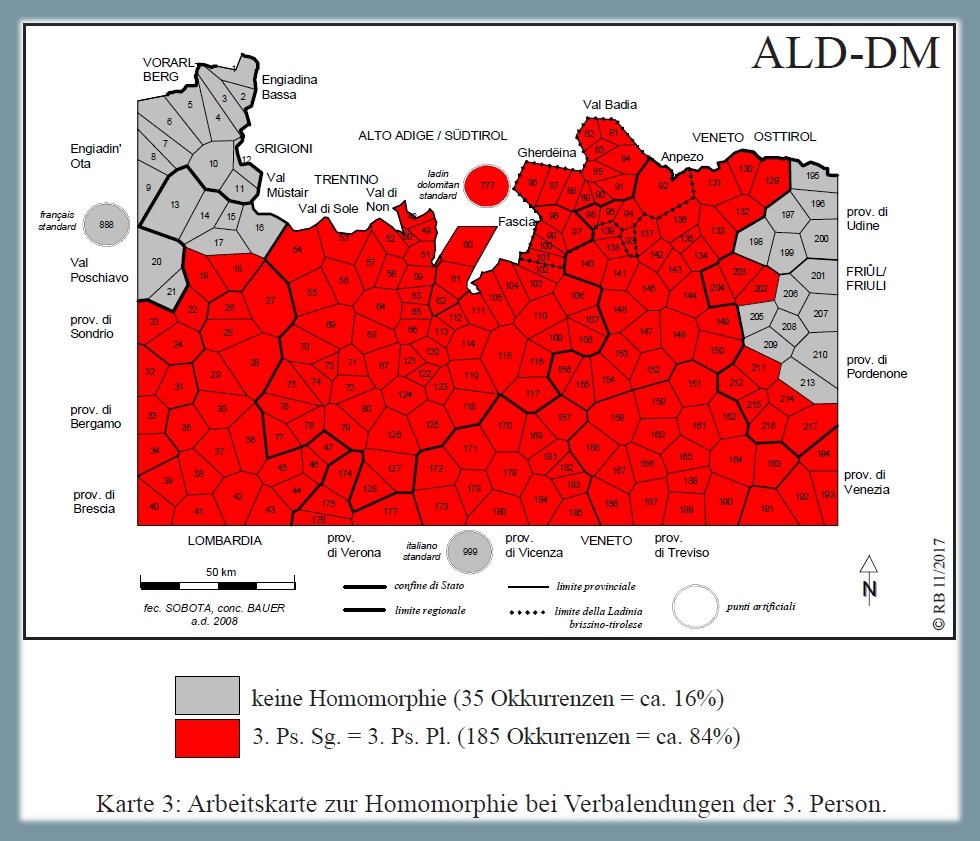
Carta di lavoro morfologica: omomorfia verbale (Bauer/Casalicchio 2017, 87)
1.1.3.3. Mantenimento -s, 2a pers. pl.17
Analisi morfologica delle desinenze verbali della 2a persona plurale in base alle carte ALD-II 1.061 state, 485 mangiavate, 113 sarete e 496 [che] mangiaste (PDF). La carta mostra la riduzione di 220 risposte dialettali (tokens) a due tipi morfologici (types) nonché la distribuzione di questi due tassati nello spazio d'osservazione (= rete ALD). Il tassato minoritario (22/220 occorrenze = poligoni rossi) si riferisce ai dialetti (retoromanzi) con forme sigmatiche, mentre l'altro tassato riunisce 195 dialetti e tre lingue standard (777: ladin dolomitan, 888: français standard, 999: italiano standard) che non hanno mantenuto la -s finale (= poligoni grigi).
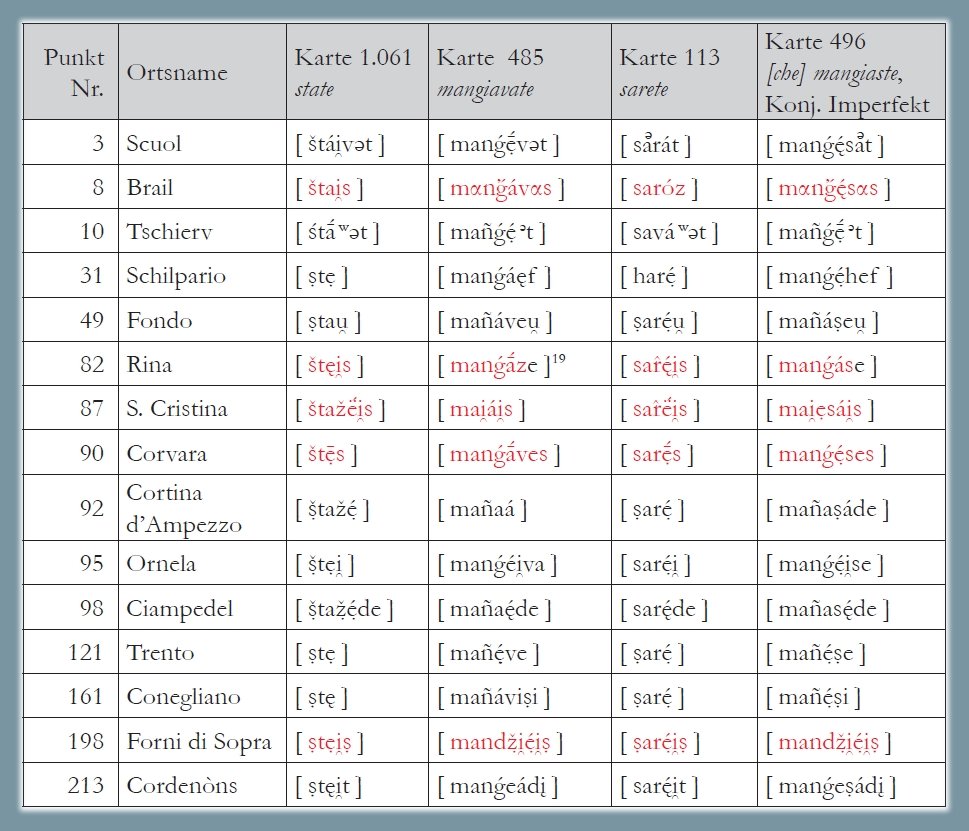
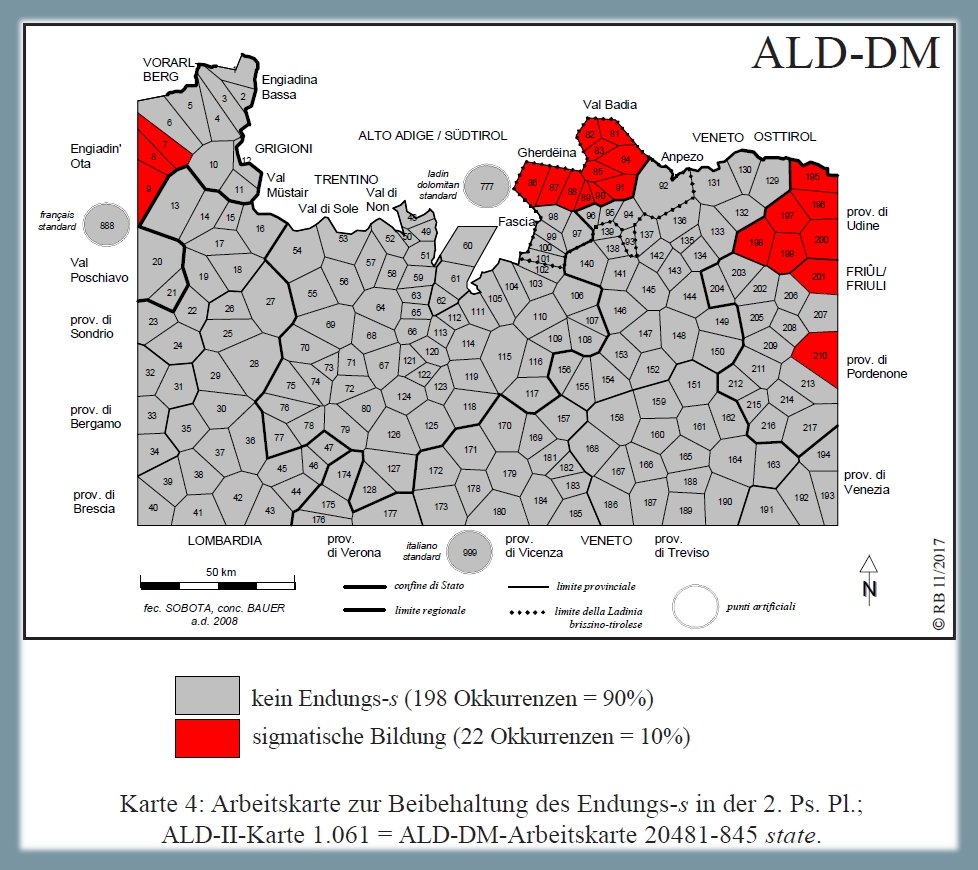
Carta di lavoro morfologica: mantenimento -s, 2a persona (Bauer/Casalicchio 2017, 91)
1.1.3.4. Negazione18
Analisi morfosintattica dei tipi di negazione presenti sulla carta ALD-I 103 ... non sarebbe caduto ... (PDF). La carta mostra la riduzione di 220 risposte dialettali (tokens) a tre tipi sintattici (types) nonché la distribuzione di questi tre tassati nello spazio d'osservazione (= rete ALD). Il tassato 1, maggioritario con una frequenza di 174/220 (poligoni rossi), si riferisce alla negazione semplice (NON). Il tassato 2 (poligoni gialli) riunisce le risposte con negazione rafforzata (MÍCA), e il terzo tassato (poligoni blu) rappresenta la negazione doppia, come il ladino [ne ... nía ...].
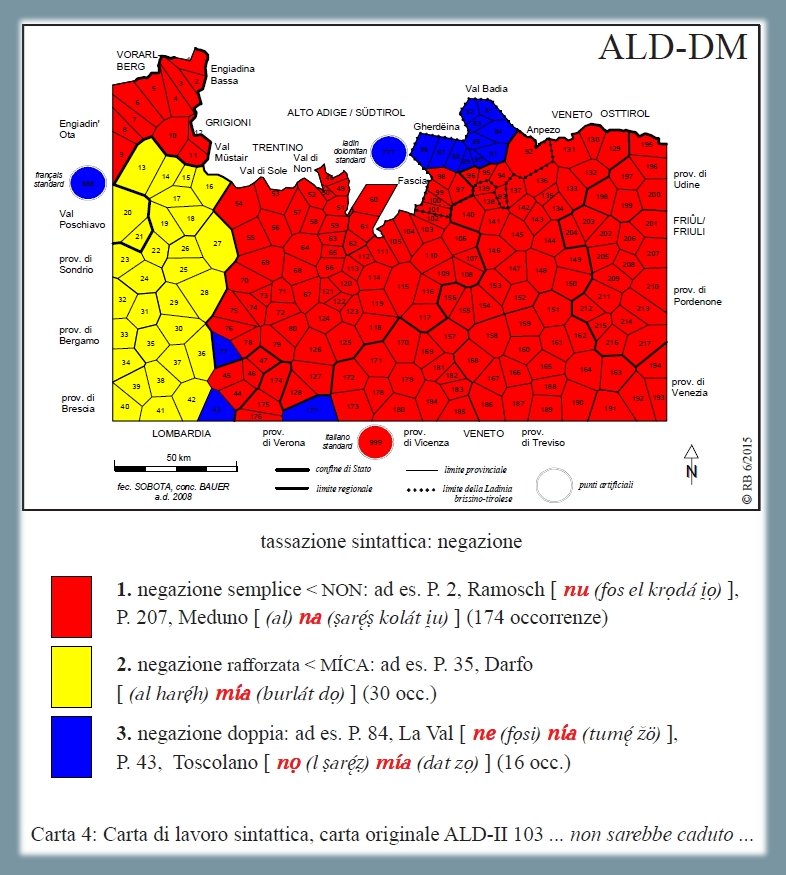
Carta di lavoro sintattica: la negazione (Bauer 2016, 17)
1.2. Carte sinottiche "di densità"
Con carta di densità (ted. Dichtekarte) si intende una carta sinottica che rappresenta, tramite un numero di intervalli prestabiliti (e rappresentati, sulla carta, da colori diversi), la presenza relativa di un fenomeno linguistico nello spazio (cf. Bauer 2008b, 81-82, Bauer 2009c, 300).
1.2.1. Mantenimento di -l- ← PL-19
La prima carta di densità è dedicata al mantenimento della -l- postconsonantica del nesso latino PL-. Nei dialetti delle zone colorate la liquida si è mantenuta. La carta di densità (PDF, versione in bianco e nero) è stata creata in base a 10 carte originali dell'ALD 1, e cioè: 586 piace ← PLÁCET, 587 piacere (← PLACÉRE), 588 la piaga (← PLÁGA), 590 piano (← PLÁNU), 593 la piazza (← PLÁTIA), pieno (← PLÉNU), 605 la pioggia (← PLÓVIA), 606 il piombo (← PLÚMBU), 607 piovere (← PLÓVERE) e 611 la piuma (← PLÚMA).
I valori di frequenza (della -l- mantenutasi) oscillano tra un minimo di 0 (poligoni bianchi) e un massimo 10 (poligoni rossi). Nella carta sottostante, tali valori sono stati distribuiti a quattro intervalli: I. 9-10 presenze della liquida (= poligoni rossi), II. 7-8 presenze (= poligoni arancioni), III. 5-6 presenze (= poligoni gialli), IV. 1-4 presenze (= poligoni verdi). La carta dimostra la massima presenza della -l- nelle tre zone retoromanze (Grigioni, Ladinia ad eccezione della Val di Fassa e di Ampezzo, Friuli occidentale) e nella Val di Non (Trentino) nonché la graduale diminuzione del fenomeno in alcune aree adiacenti, come ad esempio nella Val di Sole o in parte della Lombardia orientale. A parte queste aree, il manitenimento della -l- postconsonantica è praticamente assente al di fuori delle aree retoromanze.
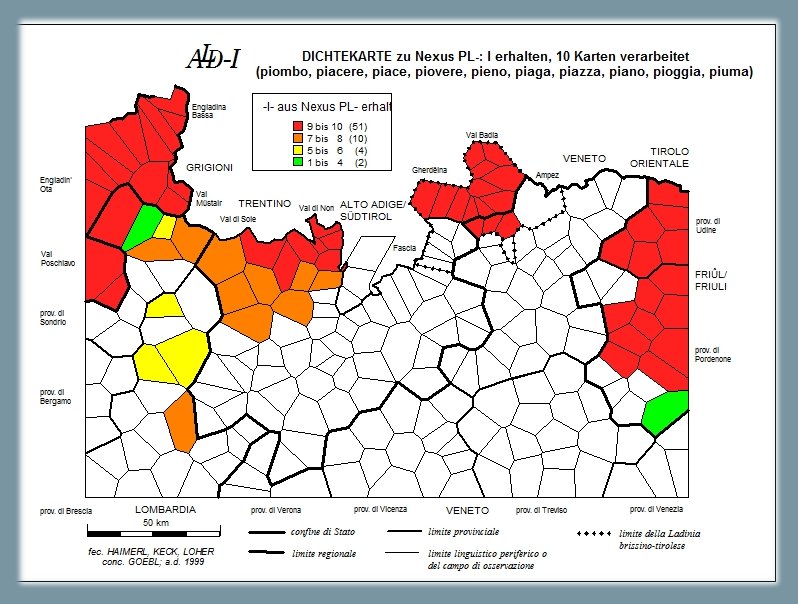
Carta sinottica "di densità": mantenimento di -l- ← PL (Bauer 2004b, 204-205)
1.2.2. Mantenimento della -s , 2a pers. sg & pl.20
La seconda carta di densità è dedicata a un criterio Ascoliano (cf. Ascoli 1873), e cioè al mantenimento della -s come desinenza verbale della 2a persona singolare e plurale. I dialetti delle zone colorate usano forme sigmatiche. La carta di densità (PDF) è stata creata in base a nove carte originali dell'ALD 2, e cioè: hai, scrivi, sarai, sarete, sei, eri, state, stiate, stessi.
Le forme sigmatiche si concentrano nelle tre aree retoromanze (= poligoni colorati in rosso e rosa). Il fenomeno diminuisce nelle anfizone peri-ladine (Val di Sole/Val di Non; Val di Fiemme; Cadore/Comelico/Agordino) ed è praticamente assente nei dialetti di pianura (lombardi, trentini, veneti).
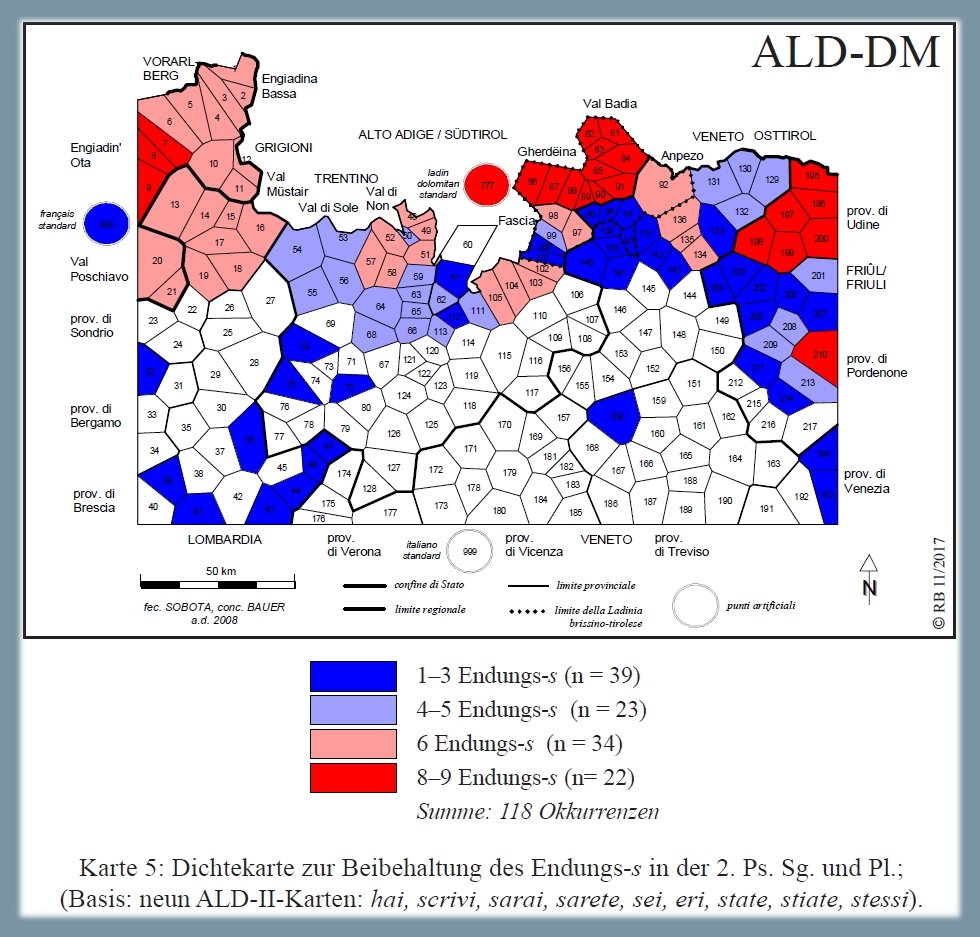
Carta di densità: mantenimento -s, 2a persona (Bauer/Casalicchio 2017, 93)
1.2.3. Germanesimi 1: ad-/superstrati, antico/medio alto tedesco21
La carta di densità (PDF) mostra la diffusione dei prestiti germanici più antichi, derivanti cioè dagli adstrati e/o superstrati germanici e dall'antico/medio alto tedesco. La sinossi poggia sull'analisi di 54 carte di lavoro. Le massime presenze (fino a 25/54, si vedano i poligoni rossi) si concentrano nel retoromanzo, soprattutto nelle valli settentrionali della Ladinia e nei Grigioni. Si noti anche la graduale diminuzione dei germanesimi dal Friuli alla Ladinia meridionale. In 63 dialetti (= poligoni bianchi) non si usa alcun germanesimo.
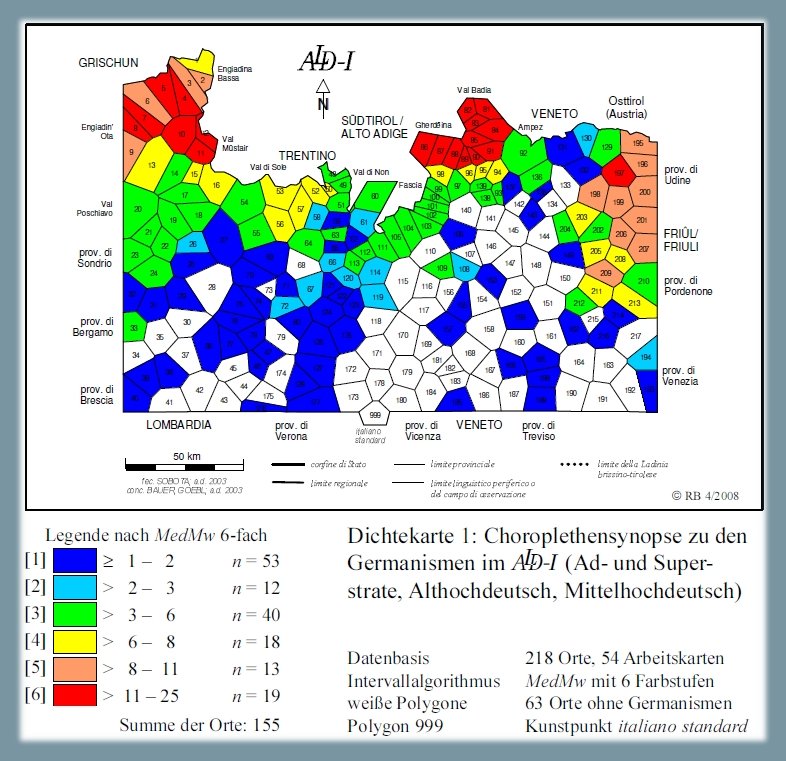
Carta di densità: germanesimi 1: antico/medio alto tedesco (Bauer 2008b, 86)
1.2.4. Germanesimi 2: bavarese, alemannico22
La prossima carta di densità (PDF) mostra la diffusione dei prestiti germanici derivanti dall'adstrato bavarese o alemannico. La sinossi poggia sull'analisi di 74 carte di lavoro. Le massime presenze (fino a 28/74, si vedano i poligoni rossi) si verificano nelle due valli settentrionali della Ladinia e nei Grigioni, mentre il fenomeno è piuttosto effimero nel Friuli e nella Ladinia meridionale. In 129 dialetti lombardi, trentini e veneti (= poligoni bianchi) non si usa alcun germanesimo.
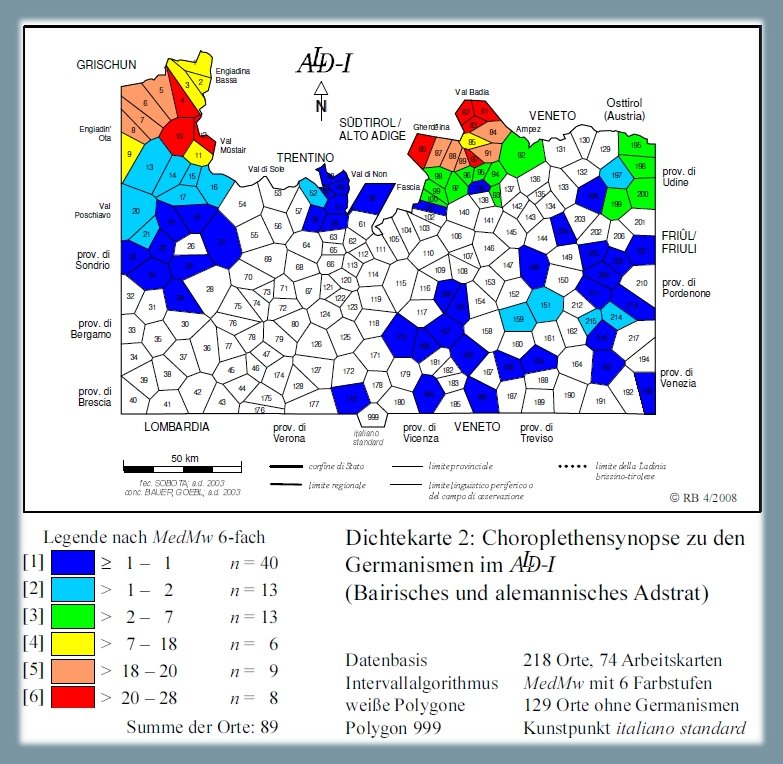
Carta di densità: germanesimi 2: bavarese/alemannico (Bauer 2008b, 87)
1.2.5. Germanesimi 3: calchi23
La terza carta di densità (PDF) dedicata ai germanesimi riguarda i calchi germanici, come ad esempio ladino [liié adöm] oppure romancio [liar aint] secondo il modello tedesco zusammen-binden "legare". La sinossi poggia sull'analisi di 21 carte di lavoro. Le massime presenze (fino a 12/21, si vedano i poligoni rossi) si verificano, ancora una volta, nelle due valli settentrionali della Ladinia e nei Grigioni. Per quel che riguarda le 21 carte analizzate, in 102 dialetti trentini, veneti e friulani (= poligoni bianchi) non si usa alcun calco tedesco.
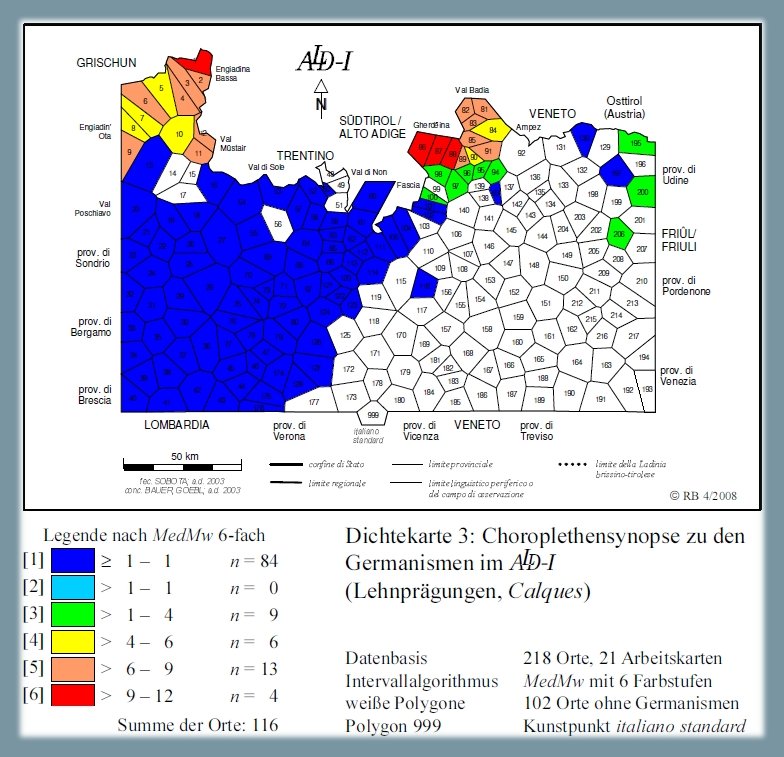
Carta di densità: germanesimi 3: calchi (Bauer 2008b, 88)
1.2.6. Germanesimi 424
La quarta carta di densità (PDF) tiene conto di tutti i germanesimi analizzati nelle tre sinossi precedenti. Perciò poggia sull'analisi di 149 carte di lavoro. Le massime presenze (fino a 60/149, si vedano i poligoni rossi) si verificano sempre nelle due valli settentrionali della Ladinia e nei Grigioni. Seguono il Friuli carnico e la Ladinia meridionale (Livinallongo).

Carta di densità: germanesimi 4 (Bauer 2008b, 89, Bauer 2009c, 304)
1.2.7. Germanesimi 5: Ladinia dolomitica25
La carta seguente (PDF) si riferisce solo a una parte della rete-ALD, e cioè alla Ladinia dolomitica (con 22 punti). La sinossi poggia sull'analisi di 99 carte di lavoro. La carta visualizza la strutturazione interna della Ladinia per quel che riguarda la presenza di germanesimi, con i valori più alti in Val Gardena e in un punto della Val Badia (P. 82, Rina). A parte la netta scissione tra nord e sud, si noti anche la quasi-assenza in Ampezzo e nella bassa Val di Fassa.
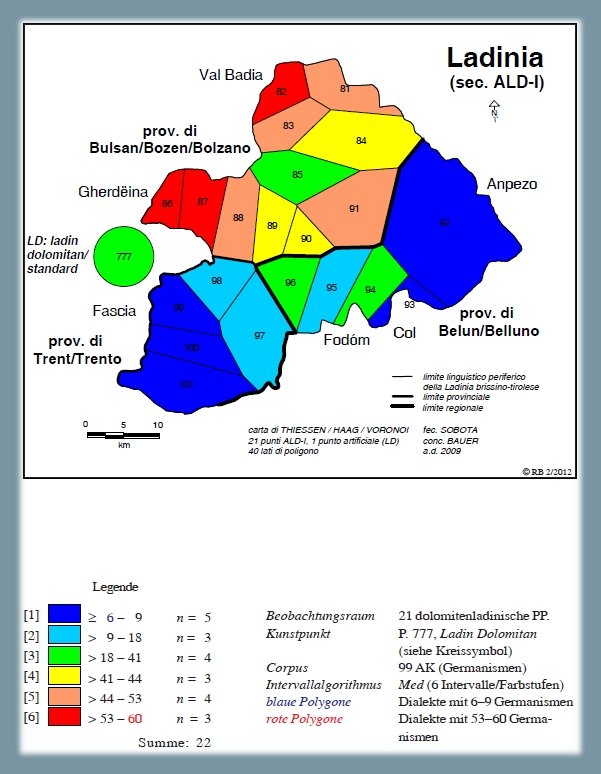
Carta di densità: germanesimi (Ladinia dolomitica) (Bauer 2012b, 302)
2. Visualizzazioni dialettometriche
I risultati delle tassazioni (dalle quali risultano le carte di lavoro presentate nel DEFAULT) sono stoccati nella cosiddetta matrice dei dati che sta alla base dell’analisi dialettometrica. Si tratta di una matrice binaria, composta di un numero piuttosto basso di dialetti per un numero molto alto di caratteri.26
Il vero e proprio lavoro tassometrico inizia con la trasformazione delle informazioni contenute nella matrice dei dati in una cosiddetta matrice di similarità, fase in cui entra in gioco il concetto delle relazioni interdialettali. In questo contesto, si adopera soprattutto il cosiddetto Indice Relativo d’Identità (IRIjk) che permette di mostrare il grado di vicinanza reciproca tra tutti i dialetti coinvolti e che parte dall’idea che la similarità tra due parlate possa essere rappresentata dal numero relativo dei caratteri che due dialetti hanno in comune. I valori del nostro indice di similarità oscillano, teoricamente, tra 0 e 100. Un valore zero vuol dire che, confrontando due dialetti, non si registra nessuna coniazione identica, cioè che i vettori delle due parlate non hanno nessun tratto linguistico (fonetico, lessicale, morfosintattico) in comune. Nella realtà dialettometrica del progetto ALD-DM, non si registra, però, mai un IRIjk uguale a zero, giacché i dialetti messi a confronto appartengono tutti alla grande famiglia delle parlate romanze. D’altronde, un valore di similarità uguale a 100 si riferirebbe alla massima similarità (100% di coniazioni identiche) tra i vettori delle due parlate paragonate (cf. Bauer 2015, 26-27).
2.1. Carte di similarità
Il messaggio iconico della carta di similarità poggia su una serie di principi (cf. Bauer 2003, 98-99):
- Come fondo-carta si utilizza sempre una rete poligonizzata di aree disgiunte (= poligoni), per poter contrassegnare graficamente (e per poter percepire a livello ottico-psicologico) degli spazi (pseudo-)continui / coerenti anziché punti isolati. La poligonizzazione avviene secondo la cosiddetta geometria di Delaunay-Voronoi-Thiessen, sperimentata nella geolinguistica dal germanista K. Haag già alla fine del 19mo secolo (cf. Bauer 2009, 105-108). Il procedimento di poligonizzazione consiste nella costruzione del centro di un cerchio circoscritto ad un triangolo e comprende tre azioni di geometria elementare: 1. triangolazione dell’intera rete, 2. costruzione delle perpendicolari sui lati del triangolo, 3. costruzione di cerchi circoscritti al triangolo. Le perpendicolari formano i lati, mentre i centri dei cerchi circoscritti stanno per gli angoli dei poligoni.
- Per ogni carta di similarità27 si sceglie un cosiddetto punto di riferimento j che viene confrontato con tutti i punti rimanenti (= N–1) della rete. A livello ottico il punto di riferimento è contrassegnato da un poligono bianco. Nel caso dei tre punti artificiali che rappresentano lo standard (italiano, francese, ladino) il punto di riferimento è rappresentato da un cerchio bianco situato fuori dalla rete poligonizzata.
- I poligoni che si riferiscono agli altri (N–1) punti sono segnati a colori secondo la logica dello spettro solare (dell’arcobaleno). Ciò vuol dire che colori caldi (ad es. rosso e giallo) stanno per similarità alte (IRIjk oltre la media aritmetica), colori freddi (ad es. verde e azzurro) invece per similarità basse (IRIjksotto la media).
- L’assegnazione dei N–1 valori di similarità a una classe (rappresentata da un colore) si effettua applicando un algoritmo di intervallizzazione. In questa sede si opera con l’algoritmo “MinMwMax” che funziona nella seguente maniera: In primo luogo si calcola la media aritmetica (= Mw, ted. Mittelwert) dei N–1 valori di similarità presi in considerazione, dopodiché si divide sia lo spazio tra il valore minimo e la media (Min–Mw) che lo spazio tra la media e il valore massimo (Mw–Max) in un numero uguale di intervalli di larghezza identica. Ogni classe, che secondo questo principio viene ad avere lo stesso spessore, rappresenta dunque un gruppo di valori di similarità (IRI) che sta, a sua volta, per un gruppo di oggetti (punti) con simili valori relativi d’identità rispetto al punto di riferimento. Siccome l’occhio umano riesce bene a percepire e a distinguere contemporaneamente tra sei e otto colori diversi, l’algoritmo “MinMwMax” opera in genere con sei intervalli (contrassegnati da altrettanti colori), tre dei quali si collocano sotto la media (colori freddi: verde, blu chiaro, blu scuro), mentre gli altri tre sono posizionati sopra la media (colori caldi: rosso, arancione, giallo).
- In alcune delle carte di similarità riprodotte in questo contributo, l’algoritmo di intervallizzazione sopra descritto è stato leggermente ampliato (“MMinMwMaxX”). La M- iniziale sta per il minimo assoluto, la -X finale per il massimo assoluto. Questi due valori rappresentano i due poli estremi di tutta la gamma dei valori di similarità, contrassegnati sulla carta tramite due poligoni tratteggiati in bianco su fondo rosso (per il massimo) e azzurro (per il minimo). Visto dall’ottica del punto di riferimento, il polo negativo, riferendosi al punto che presenta il valore (IRI) minimo, i.e. la più grande distanza rispetto al punto di riferimento, potrebbe, metaforicamente parlando, essere denominato “antipaticone, nemico, avversario, antagonista”, mentre il polo positivo (portatore del valore di similarità massimo) sarebbe il “simpaticone, l’amico migliore / più intimo” del punto di riferimento.
- Ogni carta di similarità è accompagnata da una legenda (6-tupla, operante cioè con sei intervalli / classi) e da un istogramma (12-tuplo). Ambedue informano sulla distribuzione dei N–1 valori di similarità in sei o 12 classi nonché sulla frequenza n degli oggetti (punti) rientranti in ogni classe. La curva posta nell’istogramma si riferisce alla distribuzione normale o gaussiana dei valori di similarità.
2.1.1. La posizione dell'italiano standard
Il primo profilo di similarità (PDF), riferito al punto di riferimento (cosiddetto "artificiale") dell'italiano standard, si basa su un corpus misto di 3.302 carte di lavoro (fonetiche e lessicali). Il punto di riferimento è contrassegnato dal poligono bianco 999 (posto a sud della rete) e da una freccia rossa. Leggenda e istogramma informano sulle sei classi dei valori di similarità (calcolati in base all'IRI999,k, denominato, sulla carta, in tedesco RIW999,k = Relativer Identitätswert).
Dal punto di vista dell'italiano standard, il valore minimo (36% di similarità) è registrato nel punto 8, Brail/Engadina (si veda il poligono azzurro trattegiato in bianco = dialetto più distante dall'italiano), mentre come dialetto più simile all'italiano (similarità pari al 76%) risulta il punto 119, Lèvico/Trentino (si veda il poligono rosso trattegiato in bianco). Osservando la distribuzione delle sei classi cromatiche nello spazio, si nota, più che altro, la stragrande distanza intralinguistica (similarità sotto il 50%) dei tre tronconi che formano (sin dagli studi dell'Ascoli 1873) la famiglia delle parlate ladine (ossia retoromanze), cioè il romancio, il ladino dolomitico e il friulano (= aree colorate in azzurro e celeste). Dall'altro lato della scala dei valori di similarità appare il macro-sistema trentino-veneto, i cui dialetti (colorati in arancione e rosso) dimostrano una similarità molta alta (67-76%) con l'italiano.
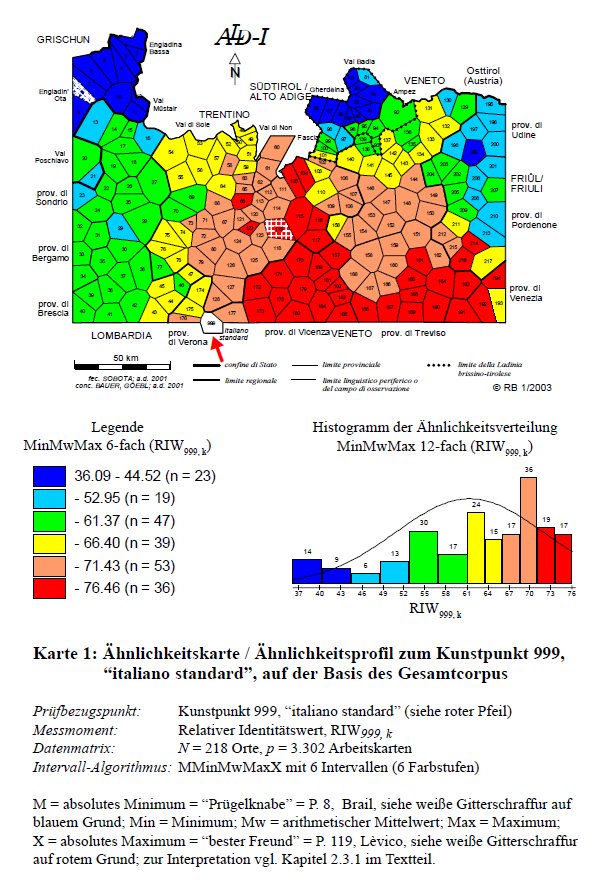
Carta di similarità del P. 999 "italiano standard" (= Karte 1 in Bauer 2002/2003, 244).
Per altre tre carte di similarità del P. 999, basate sul corpus misto (fonetica, lessico e in parte anche morfosintassi), cf. Bauer 2002c, 98 (527 carte di lavoro), Bauer 2010c, 24 (4.017 carte di lavoro) e Bauer 2014b, 109 (4.310 carte di lavoro).
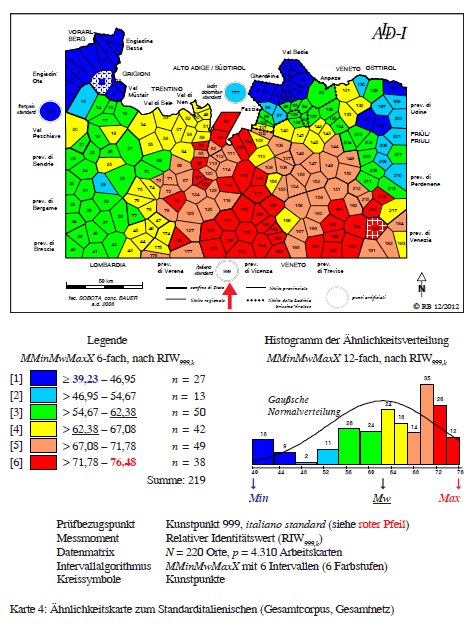
Carta di similarità del P. 999 "italiano standard" (= Karte 4 in Bauer 2014b, 109).
Nel caso della carta sovrastante (PDF originale, corpus 4.310 carte di lavoro, IRI999,k), il punto di riferimento (999 "italiano standard") è contrassegnato da un cerchio bianco posto al di fuori della rete d'osservazione (e dalla solita freccia). Rispetto al primo profilo di similarità si nota una leggera differenza nella scala dei valori di similarità (dovuta alla crescita del corpus): il minimo assoluto sale a 39 (ed è registrato nel P. 10 Tschierv/Val Monastero, si veda il poligono azzurro tratteggiato in bianco), mentre il massimo si aggira sempre attorno al 76% (si veda il poligono rosso tratteggiato in bianco del P. 163 Motta di Livenza/Veneto). Viene invece confermata la grande distanziazione del gruppo ladino/retoromanzo (= poligoni delle classi [1] e [2]) dall'italiano.
La seguente carta (tratta da Bauer/Casalicchio 2017, 98, PDF originale) è suddivisa in tre parti, per dimostrare l'importanza del corpus intralinguistico preso in esame. Si tratta di un profilo multiplo di similarità del P. 999 "italiano standard", una volta elaborato in base a un corpus di 2.111 analisi fonetiche (vedi sotto parte 7a), poi in base a un corpus lessicale (2.003 carte di lavoro, vedi sotto parte 7b) e infine su una corpus morfosintattico (con 834 carte di lavoro, vedi parte 7c; per una carta analoga basata su un corpus di 52 carte di lavoro che riguardano esclusivamente la formazione del plurale cf. Bauer 2002c, 99, PDF). Per tutti e tre i profili sottostanti è stato usato l'Indice Relativo di Identità (IRI999,k).
Il profilo fonetico (7a) fa vedere una netta opposizione tra il sistema dell'italiano e quello del français standard (P. 888, con appena il 20% di similarità; si veda il cerchio azzurro tratteggiato in bianco a nordovest della rete), mentre la massima similarità fonetica è registrata nel Veneto (P. 180 Villaverla; si veda il poligono rosso tratteggiato in bianco, immediatamente accanto al/a nord del punto di riferimento). La distanziazione fonetica del gruppo ladino/retoromanzo concerne, innanzitutto, il romancio (Engadina, Val Monastero) e il ladino dolomitico settentrionale (Val Badia, Val Gardena), in maniera minora anche il friulano. Ciò vale anche per il profilo lessicale (7b) con il P. 82 Rina come antagonista lessicale dell'italiano (35% di similarità). La distanza lessicale del friulano risulta, invece, decisamente minore. Il profilo morfosintattico (7c) evidenzia la polarizazzione "globale" tra tutto il ladino/retoromanzo (questa volta di nuovo includendo il friulano) e italiano, conosciuta dal profilo generale di cui sopra, con il minimo registrato nei Grigioni (P. 12 Müstair, 24%). Su tutti e tre i profili, la distribuzione dei poligoni rossi rappresenta l'alto grado di "italianità" (fonetica, lessicale e morfosintattica) dei dialetti parlati nella macro-area trentino-veneta.
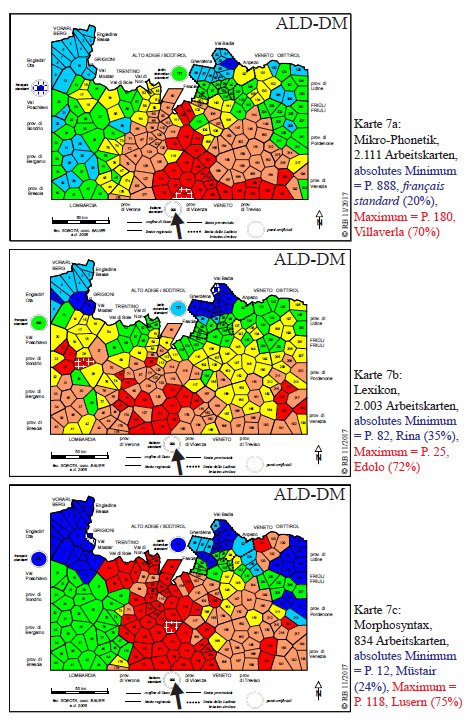
Tre carte di similarità del P. 999 "italiano standard": fonetica vs. lessico vs. morfosintassi (= Karte 7a-c in Bauer/Casalicchio 2017, 98).
Il prossimo profilo di similarità del P. 999 "italiano standard" opera con una rete ridotta, limitata ai dialetti parlati in Trentino (PDF). L'IRI999,k è calcolato in base ad un corpus misto di 3.330 carte di lavoro. Accanto ai 62 punti trentini dell'ALD si prendono in considerazione tre punti situati in provincia di Bolzano (P. 60 Bronzolo/Branzoll, P. 61 Egna/Neumarkt, P. 62 Salorno/Salurn) e due punti artificiali rappresentanti lo standard italiano (999) e quello francese (888).
Per quel che riguarda la posizione dell'italiano rispetto al sistema dei dialetti parlati nel Trentino (ladino fassano a nord-est, influssi lombardi ad ovest e veneti ad est), i valori di similarità oscillano tra un minimo di 27 (registrato nel confronto tra italiano e francese) e un massimo di oltre 72% (si veda il poligono rosso tratteggiato in bianco del P. 115 Strigno). Come dialetti dissimili si dimostrano, in primo luogo, le parlate ladine dell'alta Val di Fassa (P. 97 Delba e P. 98 Ciampedel) che condividono solo il 44% di tutte le caratteristiche (= ∼1.465/3.330) prese in esame con l'italiano. Dall'altro lato la carta evidenzia l'italianità alta (∼71% di similarità) delle parlate della Valsugana (si vedano i poligoni rossi accanto al punto di riferimento) nonché la similarità alta (66–69%) dell'intero gruppo dei dialetti centrali della Val Lagarina, della Val di Cembra e della bassa Val di Fiemme (si vedano i poligoni arancioni della classe [5]). Il trentino occidentale (Giudicarie e Val Rendena), in genere associato al sistema dialettale lombardo orientale, appare come gruppo compatto (poligoni verdi della classe [3] con 62–65% di similarità) alla quale appartengono anche i dialetti anaunici e solandri della Valle del Noce.
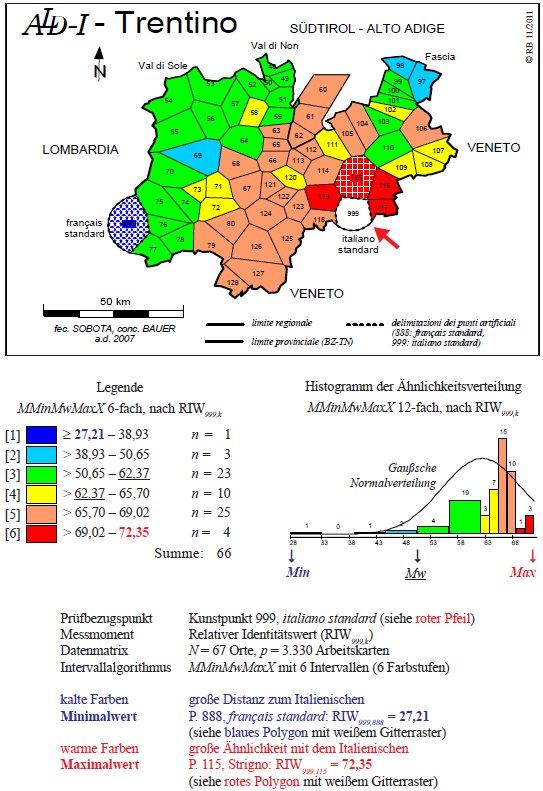
Carta di similarità del P. 999 "italiano standard", subset Trentino (= Karte 1 in Bauer 2012).
2.1.2. La posizione del français standard
Il secondo punto artificiale inserito nella rete d'osservazione del progetto ALD-DM si riferisce al français standard (P. 888, si vedano il cerchio bianco e la freccia rossa a nordovest della rete). Il profilo di similarità sottostante (PDF) poggia su un corpus misto di 4.017 carte di lavoro, elaborato in base all'IRI888,k. Salta all'occhio la scala relativamente stretta dei valori di similarità (34–50%) il che sottolinea l'eterogeneità del francese rispetto alle parlate documentate nell'ALD. Come più affini al francese appaiono i dialetti lombardi alpini (= poligoni rossi con 47–50% di similarità) e il lombardo orientale (incl. il trentino occidentale; poligoni arancioni della classe [5], 44–47%). Dall'altro lato della scala troviamo i dialetti veneti della provincia di Vicenza (poligoni azzurri della classe [1], 34-36%) con il minimo assoluto registrato a Bassano (P. 183), il cui dialetto condivide solo un terzo di tutte e 4.000 le caratteristiche esaminate (IRI888,183 = 34,67) con il francese.
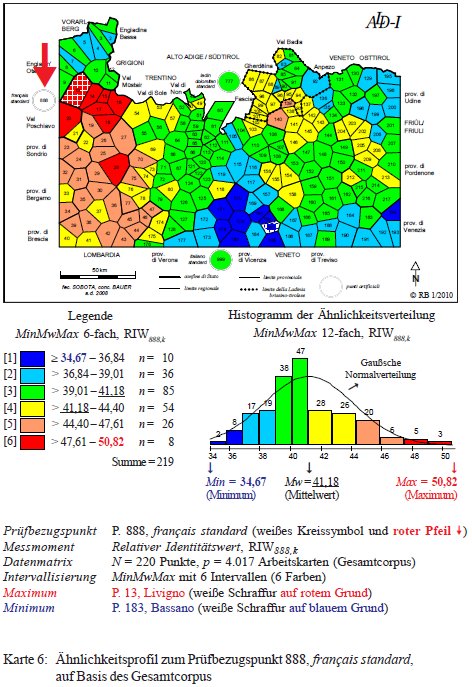
Carta di similarità del P. 888 "français standard" (= Karte 6 in Bauer 2010c, 25).
2.1.3. La posizione del romancio
2.1.3.1. Bassa Engadina: Profilo di Tschlin (P. 1)
Il profilo del P. 1 Tschlin (3.899 carte di lavoro, PDF originale) evidenzia, da un lato, la compatezza del gruppo romancio (= 13 PP. dell'Engadina e della Val Monastero, tutti colorati in rosso con 74–88% di similarità rispetto al dialetto di Tschlin), e dimostra, dall'altro, la netta distanziazione del sistema veneto (37–44%). Non sorprende che anche il francese e l'italiano risultano poco simili al romancio del punto di riferimento, mentre nel confronto con le due "sorelle" del romancio, cioè il ladino dolomitico e il friulano, si registrano valori di similarità sopra la media aritmetica che vanno fino al 61%.
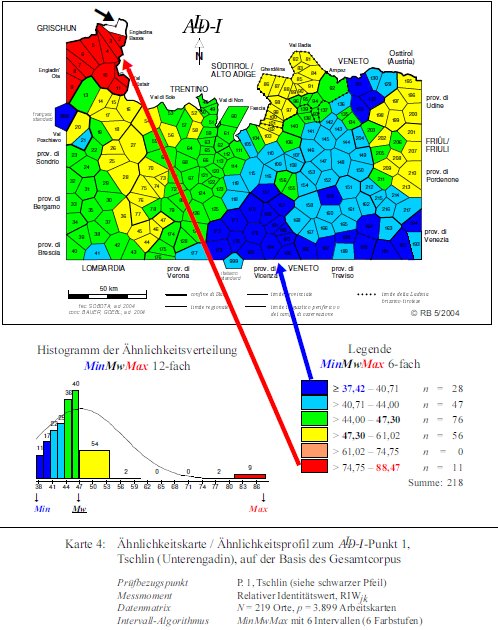
Carta di similarità del P. 1 Tschlin (= Karte 4 in Bauer 2004, 218; cf. anche grafico 3 in Bauer 2007, 68).
2.1.3.2. Val Monastero: Profilo di Santa Maria (P. 11)
Il profilo del P. 11 Santa Maria/Val Monastero poggia su un piccolo corpus di 149 carte di lavoro che trattano esclusivamente la presenza o l'assenza di germanesimi (PDF originale). È sorprendente osservare come le più grandi distanze separano, da questo punto di vista, il romancio dal ladino dolomitico (settentrionale). Ciò è dovuto al fatto che i germanesimi usati nei Grigioni non corrispondono a quelli usati nelle Dolomiti, anche se la relativa presenza di germanesimi nelle due aree è paragonabile (si veda ancora una volta la carta di densità, fig. 21, PDF).
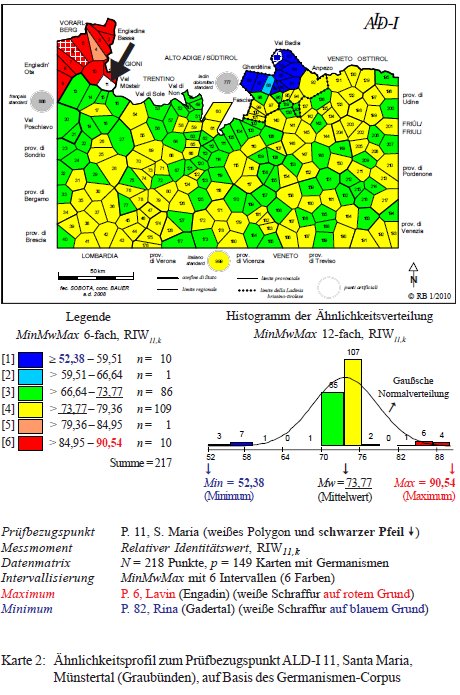
Carta di similarità del P. 11 Santa Maria/Val Monastero (= Karte 2 in Bauer 2010c, 21).
2.1.4. La posizione del ladino dolomitico
2.1.4.1. Profili del Ladin dolomitan (P. 777)
Il terzo punto artificiale preso in considerazione nel progetto ALD-DM si rifersisce al neo-standard dei dialetti dolomitici, chiamato Ladin dolomitan oppure Ladin standard (cf. a questo proposito Bauer 2012b e Bauer 2014c). Il profilo del P. 777 (PDF originale) poggia su un corpus di 4.017 carte di lavoro ed opera sempre con l'IRI777,k. La distribuzione areale dei poligoni delle classi [5] e [6] dimostra la compatezza del gruppo dialettale ladino dolomitico che condivide tra 63 e 81% dei caratteri linguistici presi in esame con il Ladin dolomitan. Si noti anche la maggiore vicinanza del ladino settentrionale (Valli Badia28 e Gardena, poligoni rossi) rispetto al ladino meridionale (alta Val di Fassa e Livinallongo, poligoni arancioni, bassa Val di Fassa e Ampezzo, poligoni gialli). Come antagonisti dello standard ladino appaiono il francese standard (IRI777,888 = 40,18) nonché il sistema dialettale veneto e l'italiano standard.29
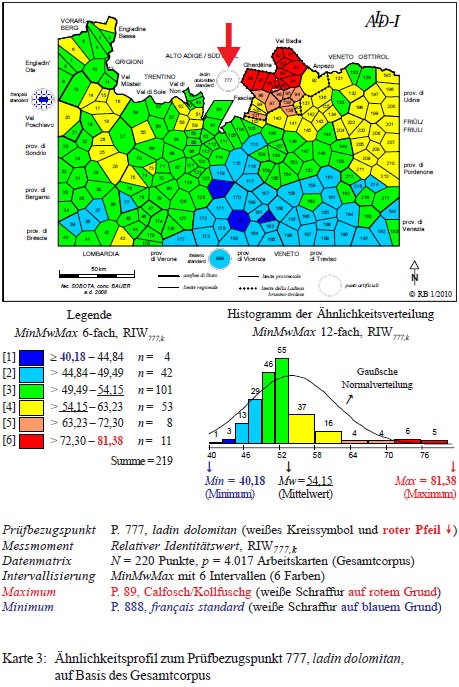
Carta di similarità del P. 777 Ladin dolomitan (= Karte 3 in Bauer 2010c, 22).
Il seguente profilo del P. 777 Ladin dolomitan si riferisce alla sola area della Ladinia dolomitica (21 punti d'inchiesta nell'ALD, 2.969 carte di lavoro, misurazione della similarità secondo IRI777,k, PDF originale). In questo modo è possibile osservare da più vicino la strutturazione interna della Ladinia rispetto alla vicinanza dei suoi dialetti al Ladin dolomitan. La graduatoria dei dialetti meglio rappresentati nello standard parte dall'alta Val Badia (70–74%) e dalla bassa Badia incl. Marebbe (66–70%) per giungere alla Val Gardena (61–66%).30 La Ladinia meridionale presenta valori di similarità sotto la media aritmetica (i.e. inferiori al 61%) con Livinallongo che precede Fassa e Ampezzo, portatore del valore minimo (46%). Ciò significa che meno della metà delle caratteristiche dell'ampezzano sono rappresentate dallo standard.
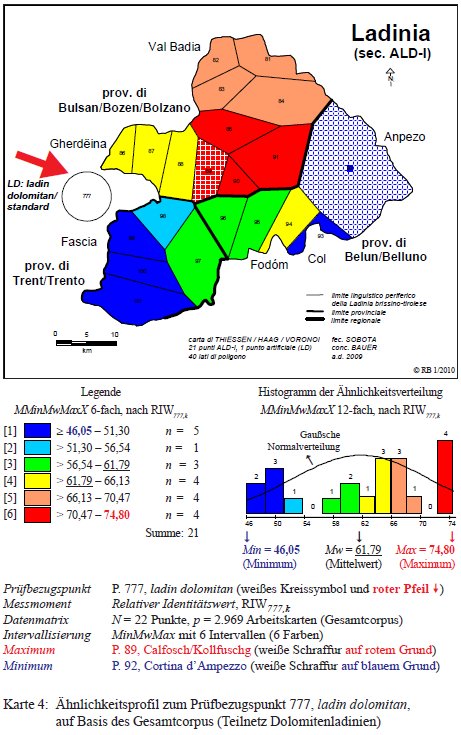
Carta di similarità del P. 777 ladin dolomitan (= Karte 4 in Bauer 2010c, 23).
Per altri quattro profili del P. 777 Ladin dolomitan si rinvia a Bauer 2009, 317-327: profilo basato su 896 analisi vocaliche (PDF), profilo basato su 789 analisi consonantiche (PDF), profilo basato su 483 analisi lessicali (PDF), profilo basato su 449 analisi morfosintattiche (PDF). La tabella sottostante informa sui valori medi di similarità delle singole vallate ladine secondo il corpus/sub-corpus preso in esame. In testa troviamo (per tutti e cinque i corpora) l'alta Val Badia, mentre la coda è rappresentata dalla bassa Val di Fassa (per il consonantismo e la morfo-sintassi) e da Ampezzo (per il vocalismo e per il lessico). Queste due vallate sono le uniche parti della Ladinia dolomitica con una similarità media complessiva sotto il 50%.
| vallata (corpus intero) |
vocalismo | consonan-tismo | morfo-sintassi | lessico |
| Marebbe (67%) | 56% | 75% | 81% | 69% |
| bassa Val Badia (68%) | 51% | 78% | 86% | 71% |
| alta Val Badia (74%) |
64% | 81% | 87% | 76% |
| Gardena (65%) | 59% | 69% | 72% | 68% |
| alta Val di Fassa (Cazet) (56%) |
49% | 59% | 64% | 59% |
| bassa Val di Fassa (Brach) (49%) |
45% | 47% | 32% | 57% |
| Livinallongo (con Colle Sta. Lucia) (58%) | 59% | 54% | 33% | 67% |
| Ampezzo (46%) | 41% | 50% | 44% | 49% |
Similarità medie tra Ladin dolomitan e i dialetti ladini (cf. Bauer 2009, 325)
2.1.4.2. Profili della Val Badia
- P. 81 Pieve di Marebbe/La Pli/Enneberg, IRI81,k, corpus misto: 4.020 carte di lavoro (PDF, cf. Bauer 2009, 300).
- P. 83 San Martino in Badia/San Martin de Tor/St. Martin in Thurn, IRI83,k, corpus misto: 3.302 carte di lavoro (PDF, cf. Bauer 2002/2003, 245).
- P. 83 San Martino in Badia/San Martin de Tor/St. Martin in Thurn, IRI83,k, corpus ridotto: 1.101 carte di lavoro con caratteri vocalici (PDF, cf. Bauer 2002/2003, 246).
- P. 83 San Martino in Badia/San Martin de Tor/St. Martin in Thurn, IRI83,k, corpus ridotto: 936 carte di lavoro con caratteri consonantici (PDF, cf. Bauer 2002/2003, 247).
- P. 83 San Martino in Badia/San Martin de Tor/St. Martin in Thurn, IRI83,k, corpus ridotto: 490 carte di lavoro lessicali (senza tenere conto dei germanesimi, PDF, cf. Bauer 2002/2003, 248).
- P. 83 San Martino in Badia/San Martin de Tor/St. Martin in Thurn, IRI83,k, corpus ridotto: 309 carte di lavoro morfologiche (formazione del plurale, PDF, cf. Bauer 2002/2003, 250).
2.1.4.3. Altri profili ladini
- Val Gardena: P. 87 S. Cristina/St. Christina, IPI87,k,31 corpus misto: 4.020 carte di lavoro (PDF, cf. Bauer 2009, 302).
- Val di Fassa: P. 98 Campitello/Ciampedel, IPI98,k, corpus misto: 4.020 carte di lavoro (PDF, cf. Bauer 2009, 306).
- Livinallongo: P. 95 Ornella/Ornela, IPI95,k, corpus misto: 4.020 carte di lavoro (PDF, cf. Bauer 2009, 308).
- P. 92 Cortina d'Ampezzo/Anpez, IPI92,k, corpus misto: 4.020 carte di lavoro (PDF, cf. Bauer 2009, 312).
- P. 92 Cortina d'Ampezzo/Anpez, IRI92,k, corpus misto: 4.020 carte di lavoro (PDF, cf. Bauer 2009, 313).
2.1.5. La posizione del friulano
- P. 195 Forni Avoltri, IRI195,k, corpus misto: 4.020 carte di lavoro (PDF, cf. Bauer 2009, 329).
- P. 213 Cordenons, IPI213,k, corpus misto: 3.899 carte di lavoro (PDF, cf. Bauer 2005, 355).
- P. 213 Cordenons, IPI213,k, corpus misto: 4.020 carte di lavoro (PDF, cf. Bauer 2009, 331).
- P. 214 Pordenone, IPI214,k, corpus misto: 3.899 carte di lavoro (PDF, cf. Bauer 2005, 356).
- P. 214 Pordenone, IPI214,k, corpus misto: 4.020 carte di lavoro (PDF, cf. Bauer 2009, 332).
2.1.6. La posizione del lombardo
2.1.6.1. Il lombardo alpino
- P. 13 Livigno (Valtellina), IRI13,k, corpus misto: 4.020 carte di lavoro (PDF, cf. Bauer 2009, 255).
- P. 23 San Rocco/Teglio, IRI23,k, corpus misto: 4.020 carte di lavoro (PDF, cf. Bauer 2009, 256).
2.1.6.2. Il lombardo orientale
- P. 30 Breno (BS), IRI30,k, corpus misto: 3.302 carte di lavoro (PDF, cf. Bauer 2003, 106).
- P. 35 Darfo (Val Camonica), IRI35,k, corpus misto: 4.020 carte di lavoro (PDF, cf. Bauer 2009, 260).
2.1.7. La posizione del trentino
2.1.7.1. Il trentino occidentale
- P. 77 Storo (TN), IRI77,k, corpus misto: 3.302 carte di lavoro (PDF, cf. Bauer 2003, 107).
- P. 77 Storo (TN), IRI77,k, corpus misto: 4.020 carte di lavoro (PDF, cf. Bauer 2009, 262).
2.1.7.2. Il ladino anaunico
- P. 49 Fondo (Val di Non), IRI49,k, corpus misto: 4.402 carte di lavoro (PDF, cf. Bauer 2009, 270).
- P. 55 Vermiglio (Val di Sole), IRI55,k, corpus misto: 4.402 carte di lavoro (PDF, cf. Bauer 2009, 267).
2.1.7.3. Il trentino centrale e orientale
- P. 66 San Michele all'Adige, IRI66,k, corpus misto: 4.402 carte di lavoro (PDF, cf. Bauer 2009, 271).
- P. 101 Moena (Val di Fiemme – Val di Fassa), IRI101,k, corpus misto: 4.402 carte di lavoro (PDF, cf. Bauer 2009, 273).
- P. 102 Forno (Val di Fiemme), IRI102,k, corpus misto: 4.402 carte di lavoro (PDF, cf. Bauer 2009, 272).
- P. 106 San Martino di Castrozza (Primiero), IRI106,k, corpus misto: 4.402 carte di lavoro (PDF, cf. Bauer 2009, 276).
- P. 117 Tezze (Bassa Valsugana), IRI117,k, corpus misto: 4.402 carte di lavoro (PDF, cf. Bauer 2009, 281).
- P. 119 Levico (Alta Valsugana), IRI119,k, corpus misto: 4.402 carte di lavoro (PDF, cf. Bauer 2009, 280).
- P. 127 Ala, IRI127,k, corpus misto: 3.302 carte di lavoro (PDF, cf. Bauer 2003, 110).
2.1.8. La posizione del veneto
- P. 130 Casamazzagno (Comelico), IRI130,k, corpus misto: 4.402 carte di lavoro (PDF, cf. Bauer 2009, 296).
- P. 133 Pozzale (Cadore), IRI133,k, corpus misto: 4.402 carte di lavoro (PDF, cf. Bauer 2009, 294).
- P. 141 Cencenighe (Agordino), IRI141,k, corpus misto: 4.402 carte di lavoro (PDF, cf. Bauer 2009, 292).
- P. 148 Belluno, IRI148,k, corpus misto: 4.402 carte di lavoro (PDF, cf. Bauer 2009, 287).
- P. 172 Valli del Pasubio (VI), IRI172,k, corpus misto: 3.302 carte di lavoro (PDF, cf. Bauer 2003, 111).
- P. 179 Calvene (VI), IRI179,k, corpus misto: 4.402 carte di lavoro (PDF, cf. Bauer 2009, 285).
2.2. Carte a interpunti
2.2.1. Carte a interpunti con funzione discriminatoria (carte quantitative di isoglosse)32
Tra le maniere euristiche di visualizzare i risultati dialettometrici si trova anche la cosiddetta carta a interpunti con funzione discriminatoria che evidenzia diversi livelli di chiusure, barriere o compartimentazioni linguistiche, alla pari di fasci quantitativi di isoglosse (più o meno discriminatori), permettendo di riconoscere i nuclei dialettali)33 “recintati” dai fasci di isoglosse. In questo caso ci si basa sulla matrice di distanza, dove sono memorizzati N/2 · (N–1) Indici Relativi di Distanza (IRDjk). Per quanto concerne il progetto ALD-DM si tratta di 24.090 di tali valori, dei quali viene utilizzata solo quella minima parte che riguarda le distanze tra punti confinanti, punti cioè che hanno almeno un lato di poligono in comune. Si tratta dunque di una classificazione molto selettiva! Il valore (metrico) di distanza rappresenta la somma relativa delle divergenze (nominali) tra due punti, vale a dire il numero relativo di singole isoglosse che separano un punto dall’altro.
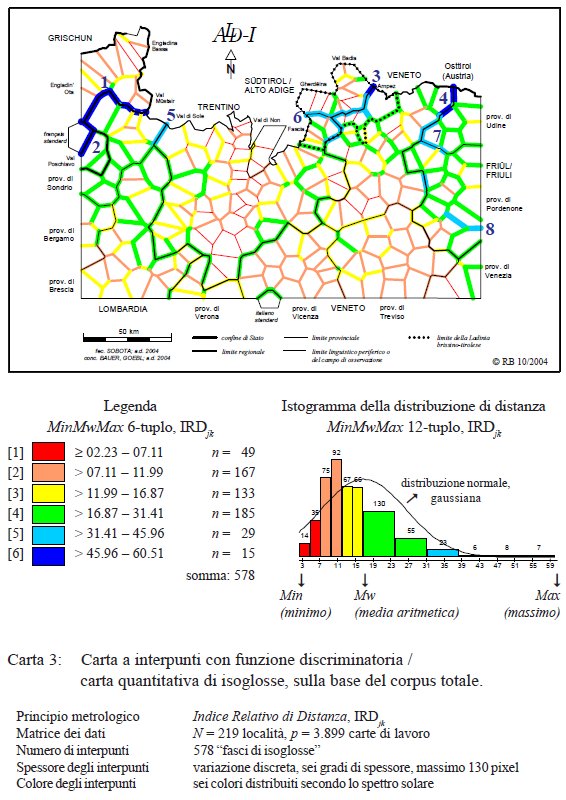
Carta a interpunti con funzione discriminatoria / carta quantitativa dí isoglosse (= carta 3 in Bauer 2005, 358).
La carta quantitativa di isoglosse (PDF originale) presenta 578 interpunti (= 2,4% di tutti i valori disponibili nella matrice di distanza), i.e. lati colorati di poligono, suddivisi – secondo il noto algoritmo “MinMwMax” – in sei intervalli. Ogni intervallo è contrassegnato sia da un colore che da uno spessore preciso, in cui vengono tracciate (sulla carta) le isolinee rientranti in quella classe. Isolinee spesse a colori freddi (intervalli 5 e 6, blu chiaro e blu scuro) segnalano importanti fasci di isoglosse che “circondano” i nuclei dialettali. La legenda informa sui valori di distanza che rientrano in queste classi. Si tratta di nuclei dialettali separati dalle parlate confinanti dal 31–46% (classe 5) o addirittura dal 46–60% (classe 6) di tutti i caratteri presi in considerazione. In altre parole: laddove vediamo grossi lati di poligono in blu scuro, abbiamo a che fare con le barriere o con le compartimentazioni linguistiche più importanti della nostra rete, giacché i punti confinanti separati da tali linee mostrano distanze intralinguistiche che variano tra il 46 ed il 60%.34
In casi del genere, quando più della metà dei 3.900 caratteri analizzati divergono tra due dialetti confinanti, abbiamo a che fare con le più importanti zone o strisce di segregazione/separazione linguistica di tutta la nostra rete. Sulla carta a interpunti ne vediamo quattro, contrassegnati dai numeri 1–4:
1. Una barriera/compartimentazione netta che separa il romancio dei Grigioni dalle parlate lombarde alpine, situate a sud di esso: già nel 1981 l’analisi dialettometrica della parte settentrionale dell’Atlante Italo-Svizzero (AIS) aveva evidenziato l’importanza del fascio di isoglosse che racchiude il romancio, staccandolo dalla parlate lombarde. Tale barriera risultava addirittura più marcata, cioè basata su un maggiore numero relativo di co-differenze, della ben conosciuta “linea” La Spezia–Rimini ritenuta essenziale per la strutturazione (storica) dell’intera Romania.linea La Spezia–Rimini ritenuta essenziale per la strutturazione (storica) dell’intera Romania.35
2. Una barriera/compartimentazione che separa il lombardo dal nostro punto artificiale francese standard.
3. Una barriera/compartimentazione che riguarda un unico interpunto e che separa (all’interno della Ladinia dolomitica) l’ampezzano dal badiotto.
4. Una barriera/compartimentazione che separa il comelicano dal friulano carnico.
Nella classe 5 (che raggruppa valori di distanza tra il 31 ed il 46%) troviamo (almeno) altre quattro compartimentazioni importanti della nostra rete. Esse sono contrassegnate dai numeri 5–7, e cioè:
5. Una barriera/compartimentazione che separa il solandro dal lombardo alpino. Questo risultato dialettometrico è in netto contrasto con le tesi dialettologiche tradizionali che legano il solandro (specie quello della parte alta della Val di Sole) al lombardo alpino. Tomasini 1960, 100 ad es. afferma che “il carattere del dialetto solandro tipico […] è di un tipo lombardo alpino”, mentre Mastrelli Anzilotti 1995, 16 è sicura che “i dialetti dell’alta valle si presentano senza dubbio alcuno come dialetti di tipo lombardo alpino”. In ambedue i casi ci sembra di avere a che fare con una specie di illusione tipologica dovuta a pochi caratteri linguistici, come ad es. la presenza delle vocali ö ed ü, la non-palatalizzazione di CA, GA o la presenza del suffisso -er (< lat. –ÁRIU). L’analisi quantitativa (più oggettiva perché prende in considerazione migliaia di caratteri [3.900], evidentemente anche quelli sopraccitati) rivela invece l’esistenza di un geotipo solandro nettamente distaccato dal lombardo alpino e relativamente affine alle parlate trentine settentrionali della Val Lagarina.
6. Una barriera/compartimentazione abbastanza complessa che attraversa la Ladinia dolomitica in senso orizzontale dividendola in due parti (nord vs. sud). Questo fascio di isoglosse separa anche le vallate dolomitiche meridionali (Fassa, Livinallongo, Ampezzo) l’una dall’altra e stacca infine il fassano dall’agordino.
7. Una compartimentazione che prolunga la già citata barriera 4 e che separa il cadorino dal friulano carnico.
8. La barriera (= zona di transizione) tra veneto e friulano.
Tutti gli altri interpunti della rete-ALD sono meno importanti perché si basano su fasci di isoglosse minori, indicando distanze intralinguistiche minime tra il 2 ed il 31%. Per evidenziare questa minore distanza anche a livello ottico, abbiamo ridotto l’intensità dei colori degli intervalli 1–4, creando una carta che fa vedere solo i 44 interpunti più importanti, cioè 29 lati di poligono rientranti nella classe 5 e 15 lati di poligono della classe 6 (v. carta sottostante, PDF originale). Secondo i risultati dialettometrici, solo questo 7% di tutti gli interpunti “circonda” i nostri nuclei dialettali e segnala le vere chiusure o compartimentazioni linguistiche, situate tutte nelle zone periferiche della rete, laddove il macro-sistema italo-romanzo in genere incontra (o si scontra con) quello ladino/retoromanzo (in senso Ascoliano36).
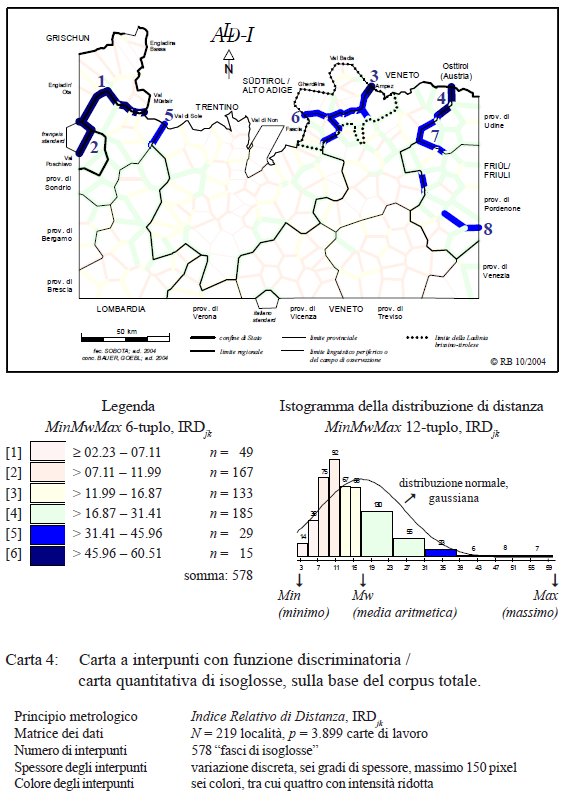
Carta a interpunti con funzione discriminatoria / carta quantitativa dí isoglosse (= carta 4 in Bauer 2005, 361).
Per altre carte quantitative di isoglosse cf.:
- Bauer 2009, 118: 4.020 carte di lavoro, IRDjk, rete intera, 573 "fasci di isoglosse" (PDF originale).37
- Bauer 2014b, 112: 4.310 carte di lavoro, IRDjk, rete intera (PDF originale).
- Bauer 2012, carta 10: 3.330 carte di lavoro, IRDjk, rete ridotta al Trentino (PDF originale).
- Bauer 2012b, 327: 2.699 carte di lavoro, IRDjk, rete ridotta alla Ladinia dolomitica, 40 "fasci di isoglosse" (PDF originale).
- Bauer 2014b, 113: 2.696 carte di lavoro, IRDjk, rete ridotta alla Ladinia dolomitica (PDF originale).
2.2.2. Carte a raggi
Essendo complementare alla carta a interpunti (che tiene conto delle distanze linguistiche misurate in base all'IRDjk), la carta a raggi opera con i valori di similarità (IRIjk) tra punti vicini.38 Partendo da una rete triangolata si usano, a livello cartografico, i lati dei triangoli in modo da connettere punti vicini con delle linee colorate di vario spessore. Alti valori di similarità sono rappresentati da linee spesse e da colori caldi (rosso ...),39 mentre i bassi valori di similarità si contrassegnano con delle linee sottili e con colori freddi (azzurro ...).40 La carta a raggi rappresenta, dunque, il "potenziale comunicativo" tra comunità vicine che dipende, evidentemente, dalla similarità dei dialetti coinvolti.
La carta a raggi sottostante, creata in base ad un corpus misto composto di 4.020 carte di lavoro (fonetiche, morfo-sintattiche e lessicali), si riferisce esclusivamente ai 217 punti dialettali della rete-ALD (senza tenere conto dei tre punti artificiali) e presenta 573 raggi suddivisi in sei classi secondo l'algoritmo MedMw41 (PDF originale). Come si vede dalla distribuzione delle linee rosse e arancioni (classi [5] e [6]), il maggiore "potenziale comunicativo" (similarità 87-97%) si riscontra nel Trentino, specie lungo il corso dell'Adige, nella pianura veneta, ma anche nei Grigioni e all'interno di singole vallate della Ladinia dolomitica. Dall'altro lato saltano all'occhio le scarse "vie di comunicazione" rappresentate dalle linee sottili delle classi [1] e [2] e poste ad es. tra romancio e lombardo alpino come anche tra l'"anfizona" cadorina e il friulano occidentale oppure tra la Ladinia settentrionale e quella meridionale.
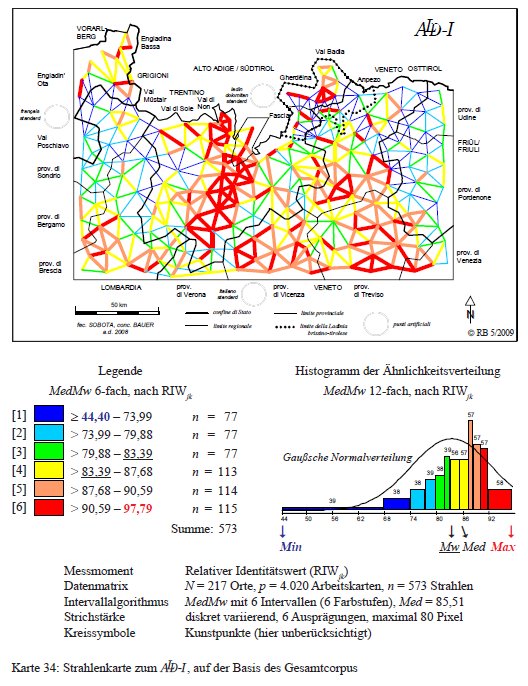
Carta a raggi (= Karte 34 in Bauer 2009, 244).
La seconda carta a raggi opera con un corpus misto di 2.969 carte di lavoro e con una rete ridotta, limitata ai 21 punti ladini, connessi tramite 40 raggi e suddivisi a loro volta in sei classi cromatiche secondo l'algoritmo MinMwMax (PDF originale). Notiamo ottime connessioni (fino al 97% di similarità) all'interno delle singole vallate (Badia, Gardena, Livinallongo e, in parte, anche Fassa) e connessioni molto ridotte (dovute a valori che scendono fino al 35% di similarità) tra la bassa Val Badia e Ampezzo e tra la parte nord e la parte sud della Ladinia. A livello topografico, queste connessioni ridotte (= distanze linguistiche) corrispondono alle ristrette condizioni di viabilità/mobilità tra le singole vallate (passi alpini).
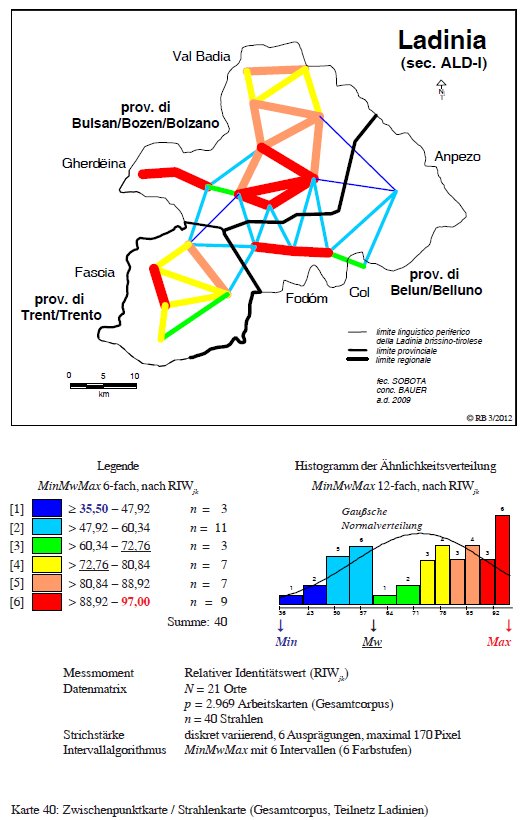
2.3. Analisi dendrografiche
2.3.1. Rete-ALD42
A differenza dei profili di similarità (DEFAULT) e delle carte a interpunti (DEFAULT), l’analisi dendrografica è una tecnica dialettometrica più complessa che utilizza tutta la matrice di similarità e che permette la scoperta di strutture profonde, complementari alle modellizzazioni di superficie delle carte di similarità. Nel caso presente si opera con una classificazione gerarchica agglomerativa del tipo average linkage basata sul co-siddetto metodo Ward.43 La classificazione in questione parte, in fin dei conti, dal numero N di oggetti (= le 220 parlate documentate nel progetto ALD-DM) che sono (secondo la loro similarità reciproca) man mano fusi o aggregati per formare un numero minore di classi oppure clusters di dialetti. I risultati tassometrici primari si riflettono negli schemi dendrografici, cioè in alberi genealogici le cui ramificazioni (che sono sempre binarie) rappresentano le classi disgiunte. L'eterogeneità (ossia la variabilità quantitativa) delle singole classi è piuttosto bassa quando il ramo si trova nella chioma, vicino alle foglie dell’albero, mentre le classi (ramificazioni) collocate vicino al tronco dell’albero e contenenti più oggetti (dialetti) sono, evidentemente, meno omogenee. In sede di dialettometria, i risultati classificatori, rappresentati dalla struttura degli alberi vengono anche proiettati nello spazio geolinguistico. Tale spazializzazione facilita non solo l’identificazione, ma anche la localizzazione concreta dei gruppi linguistici rappresentati dalle ramificazioni del dendrogramma. Per ripercorrere l’evoluzione linguistica diacronica dello spazio geolinguistico preso in esame, occorre iniziare l’interpretazione dal lato del tronco dell’albero che sta per una classe molto eterogenea in cui sono ancora raggruppate tutte le parlate. A livello metaforico, tale unità starebbe all’inizio dell’emancipazione delle lingue e dei dialetti romanzi e si riferirebbe ad una classe latina volgare/protoromanza comune.
Le tre visualizzazioni dendrografiche presentate di seguito riposano esclusivamente sull’elaborazione dialettometrica di un corpus lessicale con 1.698 carte di lavoro. La matrice di similarità è sempre calcolata secondo l'IRIjk. Il primo taglio diacronico (PDF originale) riguarda la biforcazione più elevata, vale a dire una scissione (molto remota) della presunta "unità" lessicale iniziale in due blocchi.
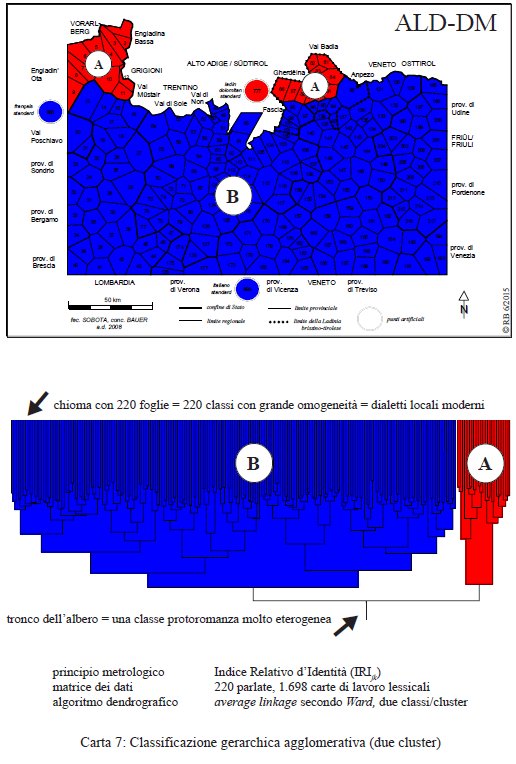
Classificazione gerarchica agglomerativa con due cluster (= carta 7 in Bauer 2016, 28).
L’albero dendrografico e la sua spazializzazione fanno risaltare la suddivisione lessicale più importante delle nostre 220 parlate in un cluster A (composto di romancio da un lato e ladino dolomitico settentrionale dall’altro) e un macro-cluster B (lombardo, trentino, veneto, ladino meridionale, friulano; francese, italiano). Questa suddivisione iniziale riguarda dunque anche il retoromanzo! Sia detto tra parentesi che nelle analisi dendrografiche contrastive di altri sub-corpora (elaborate in base al vocalismo, al consonantismo o alla morfosintassi) i tre membri della famiglia linguistica ladina (in senso Ascoliano) sono sempre raggruppati in un cluster iniziale comune, classificazione per l’appunto non confermata dall’analisi lessicale.
Procedendo nel percorso dell’analisi dendrografica, ci si sofferma al momento in cui l’unità iniziale delle 220 parlate è scissa in quattro gruppi, tra l’altro molto compatti a livello areale (PDF originale).
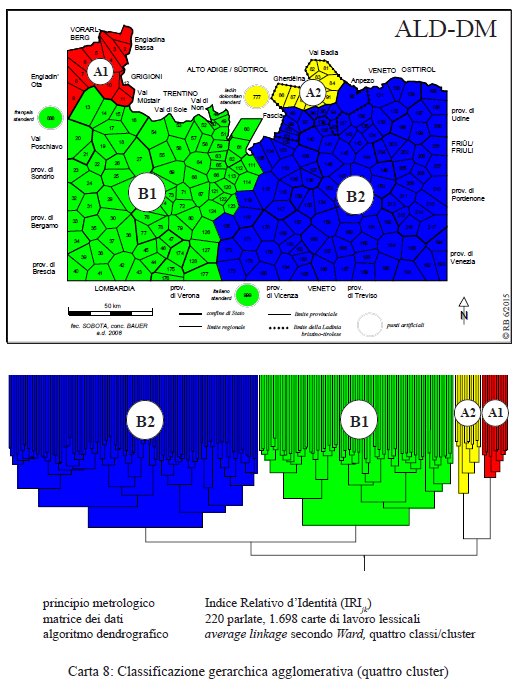
Classificazione gerarchica agglomerativa con quattro cluster (= carta 8 in Bauer 2016, 29).
Nel cluster A il romancio (A1) è ben presto separato dal ladino settentrionale (A2), mentre la prima bipartizione del macro-cluster B in una sezione occidentale e in un’altra orientale riguarda la comune classificazione (B1) di parlate lombarde e trentine (con francese e italiano) da un lato come pure la formazione di un cluster lessicale (B2) dall’altro, in cui si ritrovano, fondamentalmente, il ladino delle vallate meridionali (Fassa, Livinallongo, Ampezzo), il friulano e il veneto.
Il terzo sviluppo dendrografico (PDF originale) sfocia in una suddivisione delle nostre parlate in sette gruppi.
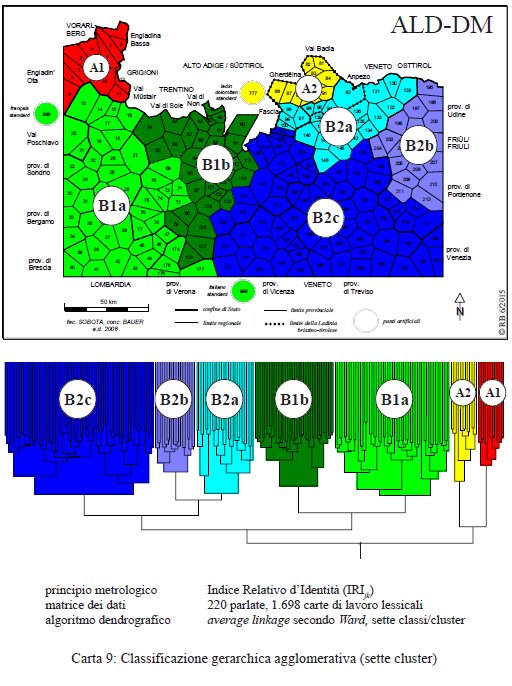
Classificazione gerarchica agglomerativa con sette cluster (= carta 9 in Bauer 2016, 30).
Anche in questo caso sorprende la plausibilità e la compattezza spaziale dei cluster. Mentre il lato A con romancio (A1) e ladino settentrionale (A2) resta inalterato, il ramo occidentale B1 si presenta suddiviso in un gruppo lessicale lombardo (B1a), che comprende (oltre alle due lingue standard, francese e italiano) anche il trentino occidentale, linguisticamente lombardo,44 e in un gruppo trentino centrale (B1b) al quale appartengono anche i dialetti solandro-anaunici (Val di Sole, Val di Non).45 Nella parte orientale della rete avviene una tripartizione del cluster B2. Il ladino dolomitico meridionale forma un gruppo lessicale a parte (B2a) che lo vede, però, assieme alle parlate dell’"anfizona" peri-ladina veneta (Agordino, Cadore, Comelico). I dialetti friulani (carnico e occidentale) costituiscono una classe "pulita" (B2b), la cui delimitazione meridionale evidenzia in maniera molto netta il passaggio dal friulano al veneto. Il terzo cluster (B2c) riunisce, infine, le parlate di stampo veneto, ivi incluso il trentino orientale (Valsugana, Val di Fiemme, Primiero) e, appunto, i dialetti veneti parlati su territorio friulano.
2.3.2. Trentino46
L'analisi dendrografica dei dati trentini (raccolti in 67 punti-ALD incl. francese e italiano standard) poggia su un corpus misto di 3.330 carte di lavoro. La similarità è calcolata in base all'IRIjk, la classificazione gerarchicha agglomerativa segue il metodo introdotto da Ward 1963.
La prima agglomerazione delle 67 parlate in due gruppi (PDF originale) riguarda un cluster 1 con francese standard, trentino occidentale e ladino fassano differenziato dal cluster 2 che comprende gli altri dialetti (italo-romanzi) parlati nel Trentino (e l'italiano standard).
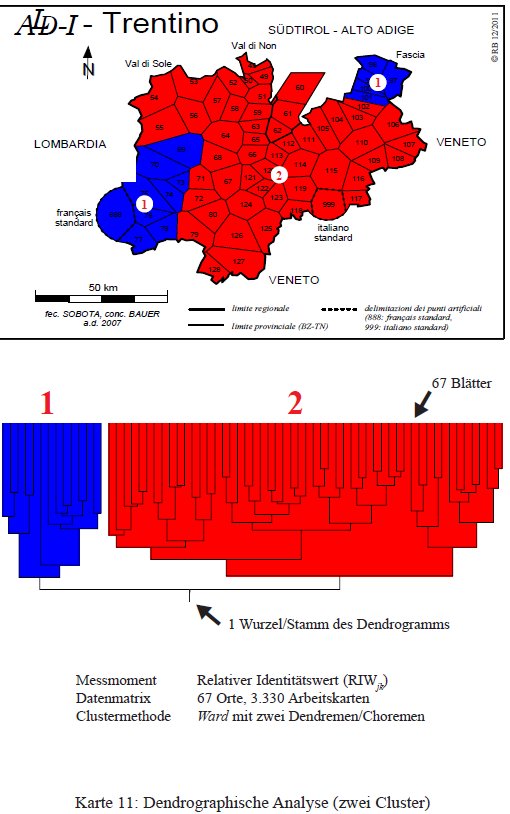
Classificazione gerarchica agglomerativa del Trentino con due cluster (= Karte 11 in Bauer 2012).
Nella fase con quattro cluster (PDF originale) si assiste a una separazione del ladino fassano (1) e in una suddivisione del cluster maggioritario: valle del Noce (4 = Val di Sole & Val di Non) vs. trentino centrale e orientale (3).
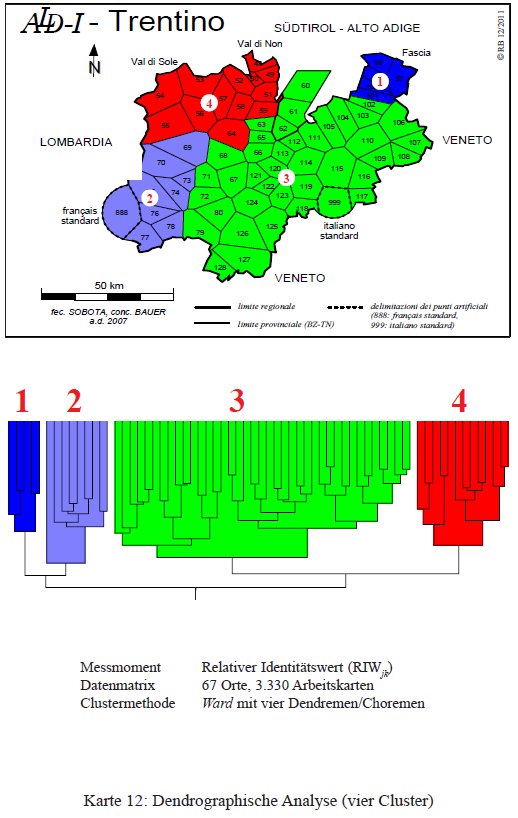
Classificazione gerarchica agglomerativa del Trentino con quattro cluster (= Karte 12 in Bauer 2012).
Agglomerando i dati in sei gruppi (PDF originale), si osserva il distacco del francese (2) e la suddivisione in trentino centrale (5) e trentino orientale (4).
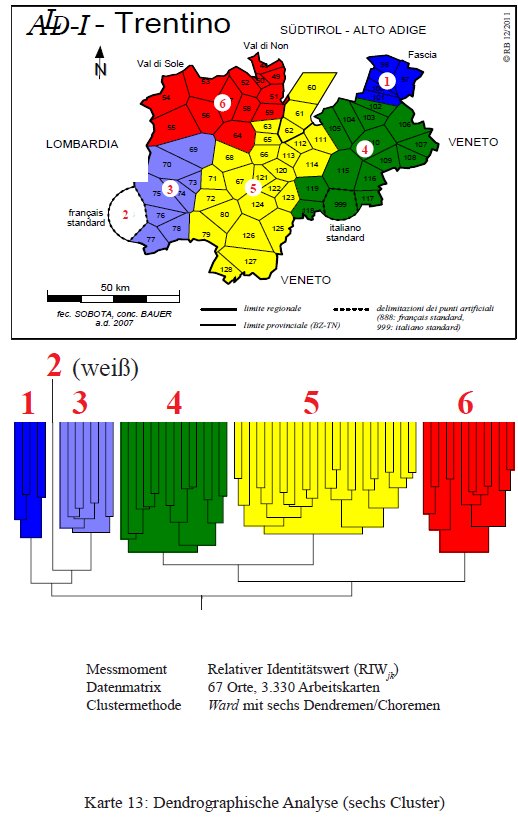
Classificazione gerarchica agglomerativa del Trentino con sei cluster (= Karte 13 in (Bauer 2012)).
Una strutturazione ancora più dettagliata dei dialetti trentini si ottiene dalla classificazione in otto gruppi (PDF originale). Assistiamo alla bipartizione del blocco trentino orientale nei dialetti della Valsugana (4) e in quelli del Primiero e della Val di Fiemme (5). Anche i dialetti della valle del Noce si separano in solandro (7) e anaunico (8).
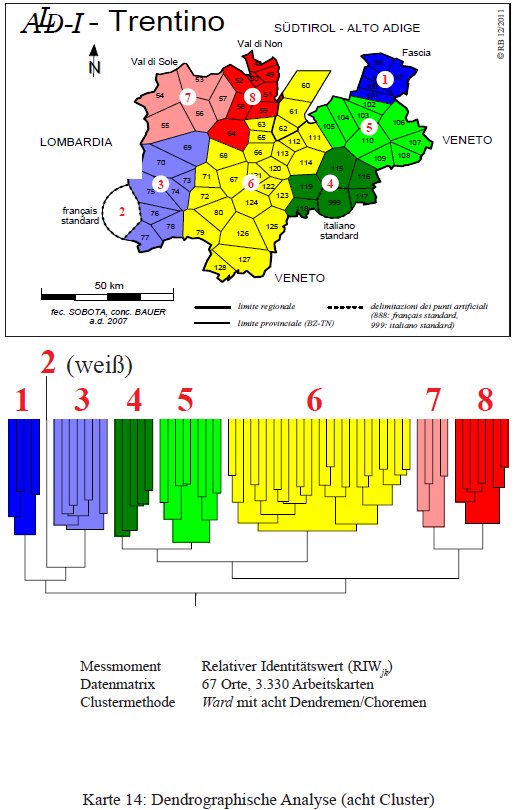
Classificazione gerarchica agglomerativa del Trentino con otto cluster (= Karte 14 in Bauer 2012).
L'ultima elaborazione del Trentino comporta una strutturazione in dieci gruppi distinti (PDF originale). L'italiano è classificato a parte (4), Val di Fiemme (7) e Primiero (6) si separano, mentre gli altri gruppi restano stabili, ivi compreso il macro-cluster del trentino centrale (8).
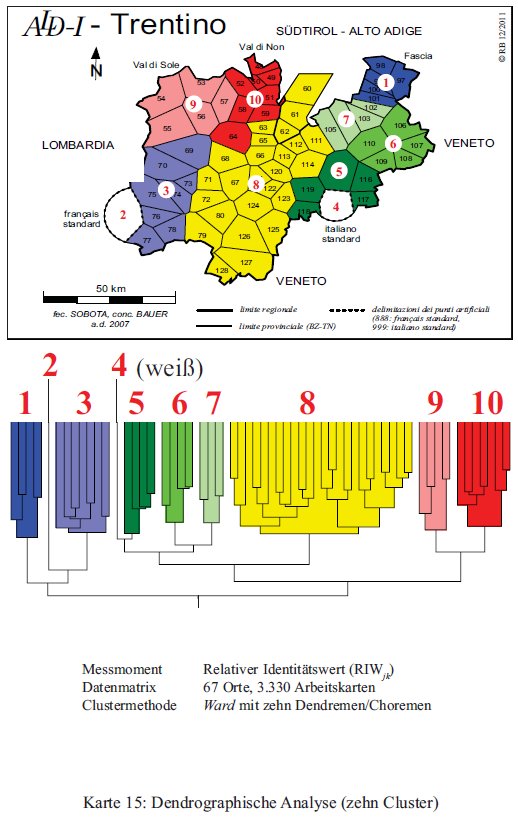
Classificazione gerarchica agglomerativa del Trentino con dieci cluster (= Karte 15 in Bauer 2012).
2.3.3. Ladinia dolomitica47
L'analisi gerarchica della Ladinia dolomitica tiene conto di 22 parlate (= 21 dialetti ladini documentati nell'ALD & punto artificiale Ladin dolomitan) e di un corpus misto composto di 2.969 carte di lavoro (applicazione dell'IRIjk e del metodo agglomerativo secondo Ward 1963).48
La prima suddivisione del "mondo ladino" (PDF originale) riguarda una bipartizione in ladino meridionale (1 = Fassa, Livinallongo e Ampezzo) e ladino settentrionale (Badia e Gardena) con il Ladin dolomitan (2).
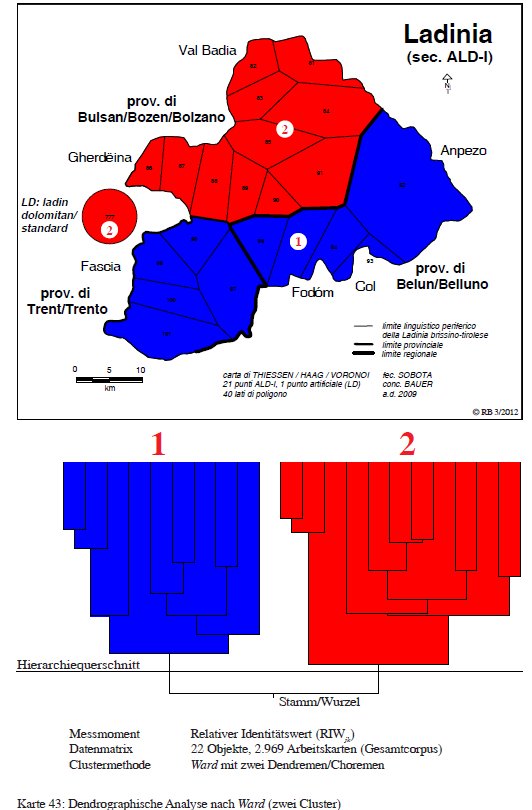
Classificazione gerarchica agglomerativa della Ladinia dolomtica con due cluster (= Karte 43 in Bauer 2012b, 329).
Passando a una segregazione in quattro cluster (PDF originale) si osserva una separazione del nord in Gardena (3) e Badia (4, incl. Ladin dolomitan) nonché la differenziazione tra Livinallongo (1) e Fassa con Ampezzo (2) per quel che riguarda il sud della Ladinia dolomitica.
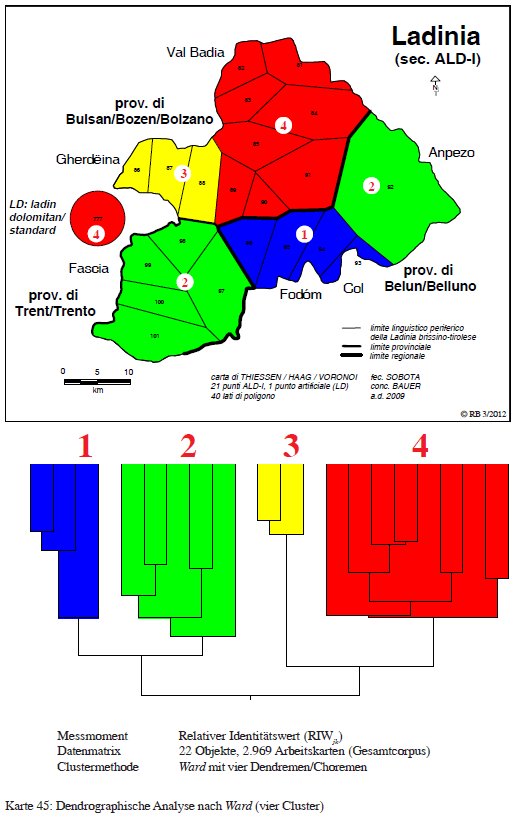
Classificazione gerarchica agglomerativa della Ladinia dolomtica con quattro cluster (= Karte 45 in Bauer 2012b, 331).
Tenendo conto di sei classi (PDF originale) si assiste alla strutturazione del sud in quattro gruppi (1 Livinallongo, 2 Colle Sta. Lucia, 3 Fassa, 4 Ampezzo) mentre il nord resta stabile.
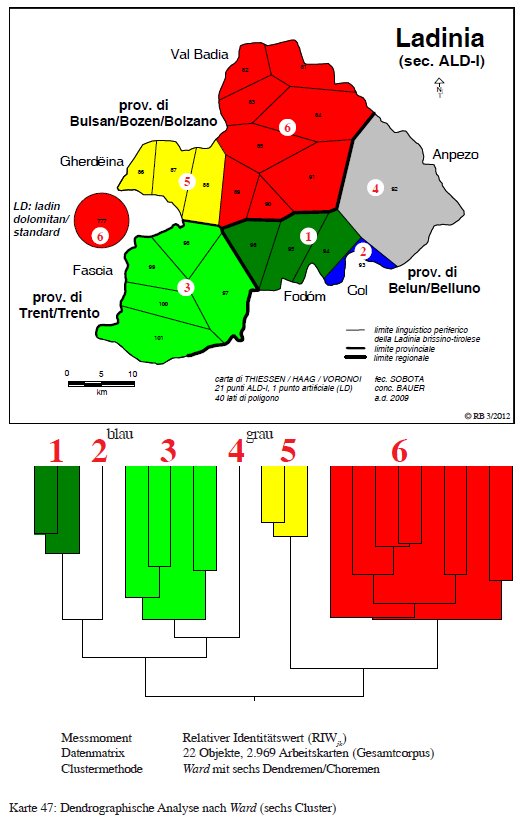
Classificazione gerarchica agglomerativa della Ladinia dolomtica con sei cluster (= Karte 47 in Bauer 2012b, 333).
Il quadro più dettagliato risulta dalla classificazione con nove cluster (PDF originale). Nella parte settentrionale si separa Marebbe (9) dalla Val Badia (8), il Ladin dolomitan (7) forma un cluster a parte. La Ladinia meridionale si compone ora di cinque gruppi con la (nuova) bipartizione di Fassa (3) in brach (bassa valle) e (4) cazet (alta valle).
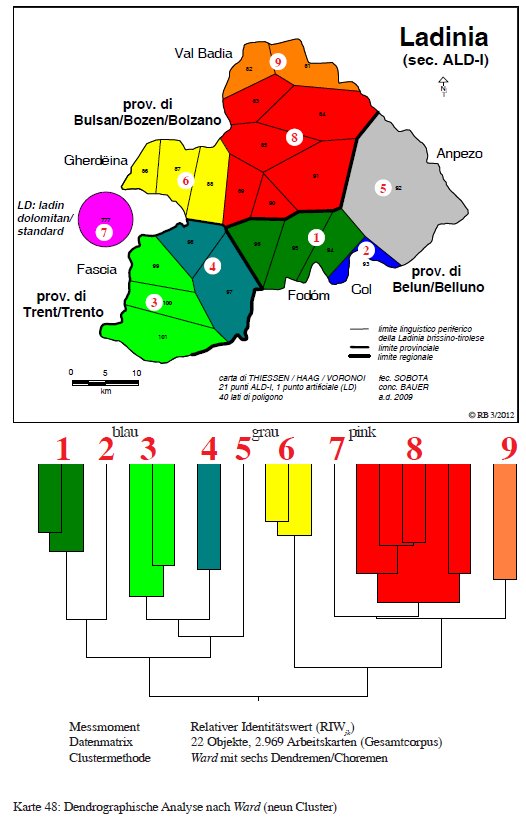
Bibliografia
- AIS = Jaberg, Karl / Jud, Jakob (1928-1940): Sprach- und Sachatlas Italiens und der Südschweiz, vol. 8, Zofingen (Link).
- ALD 1 = Goebl, Hans / Bauer, Roland / Haimerl, Edgar (Hrsgg.) (1998): Atlant linguistich dl ladin dolomitich y di dialec vejins, 1a pert / Atlante linguistico del ladino dolomitico e dei dialetti limitrofi, 1a parte / Sprachatlas des Dolomitenladinischen und angrenzender Dialekte, 1. Teil, vol. 7 [4 voll. mit Sprachkarten / con mappe linguistiche (vol. I: 1-216; vol. II: 217-438: vol. III: 439-660; vol. IV: 661-884), 3 voll. mit Indizes / con indici (vorwärts alphabetisch / alfabetico: X, 823 pp.; rückwärts alphabetisch / inverso: X, 833 pp.; etymologisch / etimologico: X, 177 pp.], Wiesbaden, Dr. Ludwig Reichert Verlag [3 CD-ROM (Salzburg 1999), 1 DVD (Salzburg 2002)] (Link).
- ALD 2 = Goebl, Hans (2012): Atlant linguistich dl ladin dolomitich y di dialec vejins, 2a pert / Atlante linguistico del ladino dolomitico e dei dialetti limitrofi, 2a parte / Sprachatlas des Dolomitenladinischen und angrenzender Dialekte, 2. Teil, Strasbourg, Éditions de Linguistique et de Philologie (Link).
- ALI = Bartoli, Matteo (1995-): Atlante linguistico italiano, a cura di U. Pellis & L. Massobrio, vol. 7, Roma, Istituto Poligrafico e Zecca dello Stato (Link).
- Ascoli 1873 = Ascoli, Graziadio Isaia (1873): Saggi Ladini, in: Archivio Glottologico Italiano, vol. I, 1 - 556.
- ASLEF = Pellegrini, Giovan Battista (1974-1986): Atlante storico-linguistico-etnografico friulano, vol. 1-6, Padova.
- Bauer 2002/2003 = Bauer, Roland (2002/2003): Dolomitenladinische Ähnlichkeitsprofile aus dem Gadertal. Ein Werkstattbericht zur dialektometrischen Analyse des ALD-I, in: Ladinia, vol. XXVI/XXVII, San Martin de Tor, Istitut Ladin Micurá de Rü, 209-250.
- Bauer 2002b = Bauer, Roland (2002): Il progetto ALD-DM (Analisi dialettometrica dell´Atlante linguistico ladino). Stato attuale dei lavori alla fine del 2002, in: Bollettino dell'Atlante Linguistico Italiano, vol. III/26, Istituto dell'Atlante Linguistico Italiano, 197-198.
- Bauer 2002c = Bauer, Roland (2002): Peder, Pire, Piero: namenkundliche Splitter aus dem romanischen Alpenraum als Prolegomena zu einer Dialektometrisierung des ALD-I, in: Peter Anreiter, Peter Ernst, Isolde Hausner (Hgg.), Namen, Sprachen und Kulturen. Imena, Jeziki in Kulture. Festschrift für Heinz-Dieter Pohl zum 60. Geburtstag, Wien, Edition Praesens, 79-99.
- Bauer 2003 = Bauer, Roland (2003): Sguardo dialettometrico su alcune zone di transizione dell´Italia nord-orientale (lombardo vs. trentino vs. veneto), in: Raffaella Bombi, Fabiana Fusco (eds.), Parallela X. Sguardi reciproci. Vicende linguistiche e culturali dell´area italofona e germanofona. Atti del Decimo Incontro italo-austriaco dei linguisti, Udine, Forum Editrice, 93-119.
- Bauer 2004 = Bauer, Roland (2004): Dialekte - Dialektmerkmale - dialektale Spannungen. Von "Cliquen", "Störenfrieden" und "Sündenböcken" im Netz des dolomitenladinischen Sprachatlasses ALD-I, in: Ladinia, vol. XXVIII, San Martin de Tor, Istitut Ladin Micurá de Rü, 201-242.
- Bauer 2004b = Bauer, Roland (2004): Analyse- und Visualisierungstechniken sprachgeographischer Daten am Ende des 20. Jahrhunderts, in: Wolfgang DAHMEN et al. (Hgg.), Romanistik und neue Medien. Romanistisches Kolloquium XVI, Tübingen, Narr, 189-208.
- Bauer 2005 = Bauer, Roland (2005): La classificazione dialettometrica dei basiletti altoitaliani e ladini rappresentati nell´Atlante linguistico del ladino dolomitico e dei dialetti limitrofi (ALD-I), in: Cristina GUARDIANO et al. (eds.), Lingue, istituzioni, territori. Riflessioni teoriche, proposte metodologiche ed esperienze di politica linguistica. Atti del XXXVIII Congresso Internazionale di Studi della Società di Linguistica Italiana (SLI), Roma, Bulzoni, Società di Linguistica Italiana , 347-365.
- Bauer 2007 = Bauer, Roland (2007): Convergenze, divergenze e correlazioni interdialettali nella rete dell´Atlante linguistico ladino, in: Vito MATRANGA / Roberto SOTTILE (Hgg.), Percorsi di geografia linguistica. Esperienze italiane e europee, Palermo, Centro di Studi Filologici e Linguistici Siciliani, 63-83.
- Bauer 2008b = Bauer, Roland (2008): Ladinia Germanica. Zum Einfluss des Deutschen auf das rätoromanische Lexikon, in: Gabriele BLAIKNER-HOHENWART et al. (Hgg.), Ladinometria. Festschrift für Hans Goebl zum 65. Geburtstag, vol. 1, Salzburg et al., 75-92.
- Bauer 2009 = Bauer, Roland (2009): Dialektometrische Einsichten. Sprachklassifikatorische Oberflächenmuster und Tiefenstrukturen im lombardo-venedischen Dialektraum und in der Rätoromania, San Martin de Tor, Istitut Ladin Micurà de Rü.
- Bauer 2009b = Bauer, Roland (2009): Profili dialettometrici veneto-bellunesi, in: Ladin!, vol. VI/2, 8-20.
- Bauer 2009c = Bauer, Roland (2009): I germanesimi nel ladino o retoromanzo. Una sperimentazione dialettometrica, in: Marco PRANDONI/Gabriele ZANELLO (eds.), Multas per gentes. Miscellanea per Giorgio Faggin, Padova, Il Poligrafo, 299-314.
- Bauer 2010 = Bauer, Roland (2010): Verifica dialettometrica della Ladinia di Graziadio Isaia Ascoli (a 100 anni dalla sua morte), in: Maria ILIESCU / Heidi SILLER-RUNGGALDIER/Paul DANLER (eds.), Actes du XXV Congrès International de Linguistique et de Philologie Romanes, Berlin, De Gruyter, 3-10.
- Bauer 2010b = Bauer, Roland (2010): Der ladinische Sprachatlas ALD. Von der Feldforschung zur dialektometrischen Datenanalyse, in: P. Sture URELAND (ed.), From the Russian Rivers to the North Atlantic. Migration, Contact and Linguistic Areas, Berlin, Logos, 353-370.
- Bauer 2010c = Bauer, Roland (2010): Die Position des Rätoromanischen und seine Beziehungen zum Deutschen, Französischen und Italienischen, in: Linguistica, vol. L, Ljubljana, 7-26.
- Bauer 2012 = Bauer, Roland (2012): Zur inneren Arealgliederung des Trentino. Eine dialektometrische Nachschau, in: Köhler/Tosques 2012 (Link).
- Bauer 2012b = Bauer, Roland (2012): Wie ladinisch ist Ladin dolomitan? Zum innerlinguistischen Naheverhältnis zwischen der panladinischen Standardsprache und den historisch gewachsenen Talschaftsdialekten, in: Ladinia, vol. XXXVI, San Martin de Tor, Istitut Ladin Micurá de Rü, 205-335.
- Bauer 2014 = Bauer, Roland (2014): Kurz gefasste Anmerkungen zur Position des Grödnerischen, in: Paul Danler/Christine Konecny (eds.), Dall’architettura della lingua italiana all’architettura linguistica dell’Italia. Saggi in omaggio a Heidi Siller-Runggaldier, Frankfurt, Peter Lang, 529-541.
- Bauer 2014b = Bauer, Roland (2014): Zur Dialektometrisierung des ALD (I und II): Ein Arbeits- und Erfahrungsbericht 2000–2012, in: Tosques, Fabio (Hg.), 20 Jahre digitale Sprachgeographie, Berlin, Humboldt-Universität/Institut für Romanistik, 95-120.
- Bauer 2014c = Bauer, Roland (2014): L'élaboration du Ladin Dolomitan et l'apport de la dialectométrie, in: La géolinguistique dans les Alpes au XXIe siècle: méthodes, défis et perspectives, Aoste , Centre d'Etudes francoproveçales, 53-73.
- Bauer 2015 = Bauer, Roland (2015): Profili linguistici friulani: gortano vs. ertano, in: Ce fastu?, vol. XCI, 21-46.
- Bauer 2016 = Bauer, Roland (2016): Analisi qualitativa e classificazione quantitativa dei dialetti altoitaliani e ladini/retoromanzi: dalla fonetica al lessico, in: Federico Vicario (ed.), Ad Limina Alpium. VI Colloquium retoromanistich, Udine , Società Filologica Friulana, 11-38.
- Bauer 2017 = Bauer, Roland (2017): Die Bezeichnungen des Regenbogens im romanischen Alpenraum, in: Annette Gerstenberg et al. (eds.), Romanice loqui. Festschrift für Gerald Bernhard zu seinem 60. Geburtstag, Tübingen , Stauffenburg, 115-135.
- Bauer/Boattini/Bortolini/Gueresi/Miglio/Ottone/Pettener 2021 = Bauer, Roland / Boattini, Alessio / Bortolini, Eugenio / Gueresi, Paola / Miglio, Rossella / Ottone, Marta / Pettener, Davide (2021): The surname structure of Trentino (Italy) and its relationship with dialects and genes, vol. 48, 3, Annals of Human Biology, Taylor & Frncis Online, 260-269 (Link).
- Bauer/Casalicchio 2017 = Bauer, Roland / Casalicchio, Jan (2017): Morphologie und Syntax im Projekt ALD-DM, in: Roland BAUER / Leander MORODER (eds.), Contribuc/Tagungsakten/Atti VII Colloquium Retoromanistich, vol. I, San Martin de Tor , 81-108.
- Gauchat 1903 = Gauchat, Louis (1903): Gibt es Mundartgrenzen?, in: Archiv für das Studium der Neueren Sprachen und Literaturen 111, Berlin, Schmidt, 345-403.
- Goebl 1981 = Goebl, Hans (1981): Isoglossen, Distanzen und Zwischenpunkte. Die dialektale Kammerung der Rätoromania und Oberitaliens aus dialektometrischer Sicht, in: Ladinia, vol. V, 23-55.
- Haag 1898 = Haag, Karl (1898): Die Mundarten des oberen Neckar- und Donaulandes (schwäbisch-alemninisches Grenzgebiet: Baarmundarten), Reutlingen, Hutzler.
- Köhler/Tosques 2012 = Köhler, Carola / Tosques, Fabio (Hrsgg.) (2012): (Das) diskrete Tatenbuch. Digitale Festschrift für Dieter Kattenbusch zum 60 Geburtstag , Berlin (Link).
- Mastrelli Anzilotti 1995 = Mastrelli Anzilotti, Giulia (1995): I dialetti dell’alta Val di Sole, in: Emanuele Banfi et al. (eds.): Italia settentrionale: crocevia di idiomi romanzi, Tübingen, Niemeyer, 15-23.
- Tomasini 1960 = Tomasini, Giulio (1960): Profilo linguistico della regione tridentina, Trento, Saturnia.
- Ward 1963 = Ward, Joe H. Jr. (1963): Hierarchical grouping to optimize an objective function, in: Journal of the American Statistical Association, vol. 58, 236-244.